ascll #只包含英文和特殊字符用一个字节表
GBK #中国式编码包含两万一千多多中国汉字用俩字节表示一个字符同时兼容ascll码
gb2312 #包含 六千左右汉字也是俩字节表示也个汉字
GB18030 #包含两万7千多文字也是俩字节一个汉字
unicode #用2-4个字节表示一个文字 它包含全球文字约13万多 其中它有映射其他国家语言的功能 别的国家下载中国GBK软件可以直接被转成中文
UTF-8 #用1,2,3,4不同文字或者符号表示不同的字节 是unicode的升级轻量版也是用的最多的
UTF-16 #用2-4个字节表示全球的所有文字 不常用
UTF-32 #用4个字节表示一个全球文字 用的更少 ·
文件名.encode('utf-8') #编码
文件名.decode('utf-8') #解码 用啥格式编码就用啥格式解码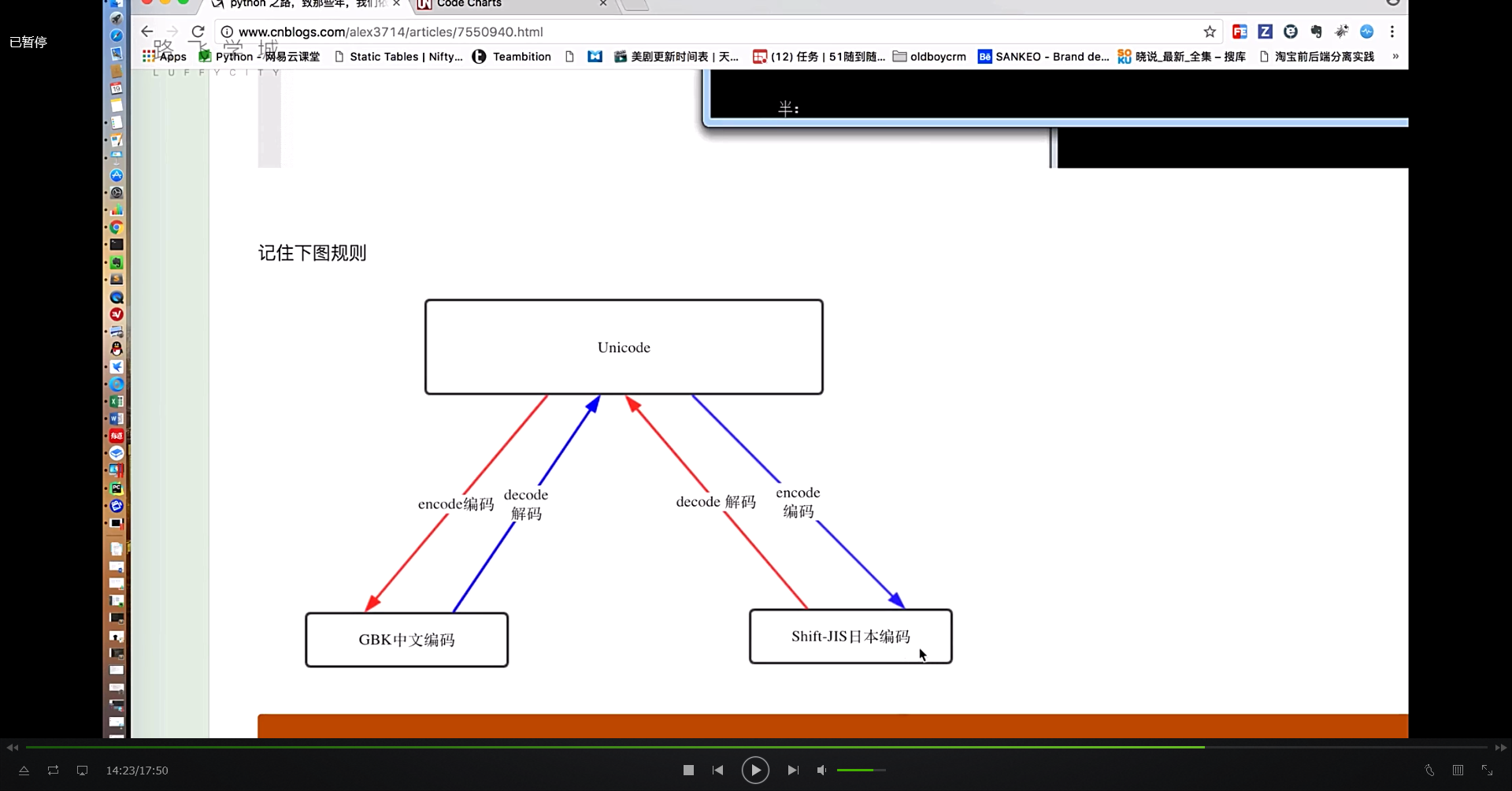
‘GBK’包含ascii但是只包含127位包括127位以内的称作低字节超过127-256的全部认为是中文称作高字节
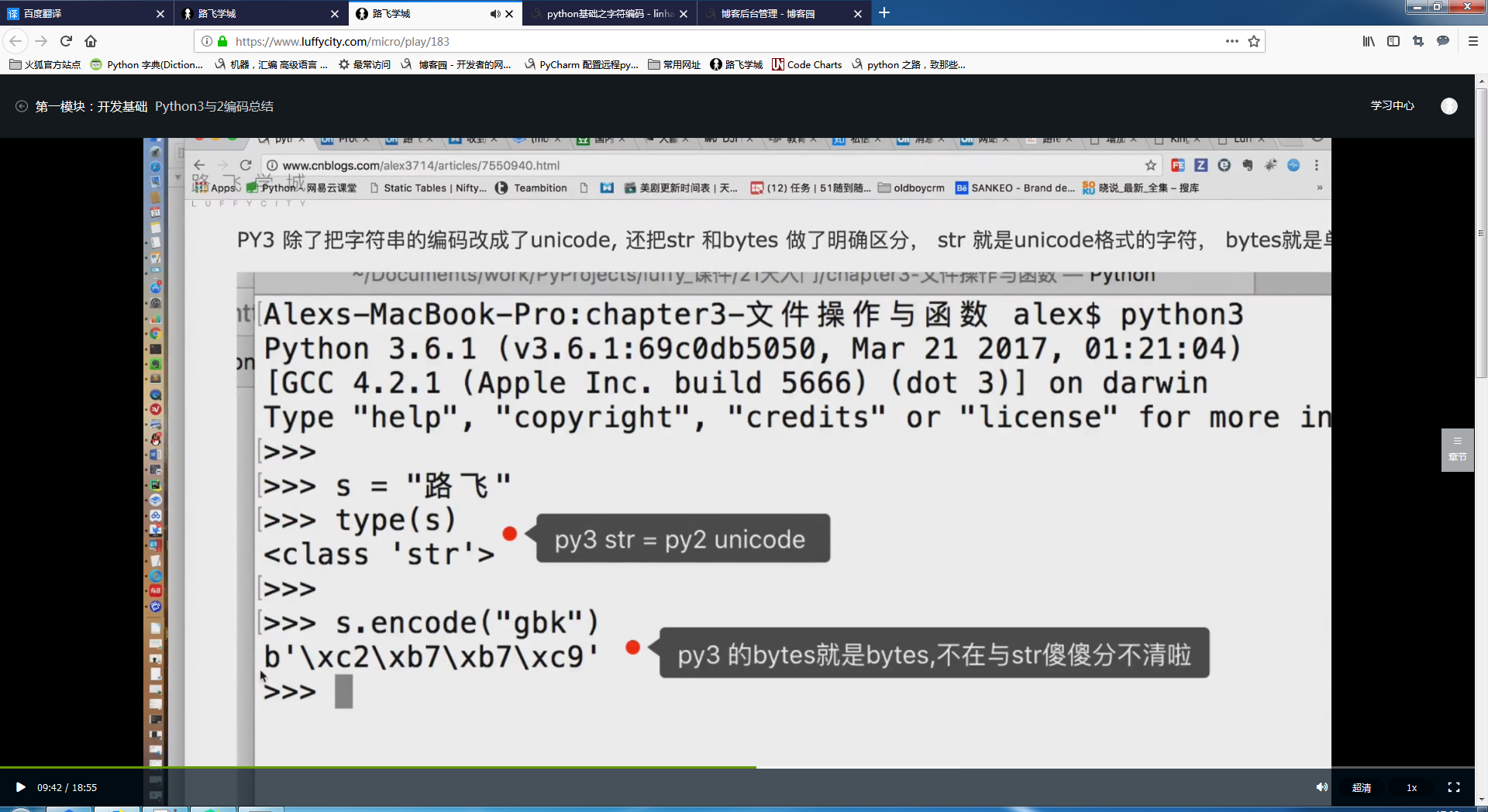
py2中:
str ==bytes==‘Unicode’三种类型
为什么要有bytes:
因为要存储 视频 图片 音频等格式的数据
以utf -8的格式在windows上无法正常显示
因为window是默认的‘GBK格式的编码
如何在python2上写一个软件在全球各个电脑都可以看?
1:在每个电脑安上你写软件用的编码
2:使用‘Unicode’去用你原来的编码去解码
文件头:
以’utf-8‘ or ’gbk‘的格式编写的代码加载到内存里还是你原来的编码格式并不会变成’unicode‘ 除非再次用‘decode(‘你原来的格式’)’解码成‘Unicode’
py3:
以’utf-8‘ or ’gbk‘的格式编写的代码加载到内存里编码格式会自动变成’unicode‘