在这篇martin和另外两位模式匹配领域专家的论文里说了模式匹配的几种实现方式,以及scala是选择哪种方式来实现的。
http://lampwww.epfl.ch/~emir/written/MatchingObjectsWithPatterns-TR.pdf
我引用了里面的一些描述。
在面向对象的程序中数据被组织为一级一级的类(class)
面向对象语言在模式匹配方面的问题在于如何从外部探测这个层级。
有6种实现模式匹配的方法:
1) 面向对象的分解 (decomposition)
2) 访问器模式 (visitor)
3) 类型测试/类型造型 (type-test/type-cast)
4) typecase
5) 样本类 (case class)
6) 抽取器 (extractor)
论文里从3个维度9个标准来对比了各种实现方式:
简明程度(框架支持、浅匹配、深匹配),维护性(表征独立、扩展性),性能(基础性能、广度和深度延展性)
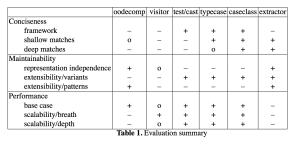
比较的细节在这篇论文里有提,不一一展开。
最终scala选择了采用 样本类(case class) 和 抽取器(extractor) 来实现模式匹配。
我们大致了解一下case class和extractor 是怎么回事
1)样本类(case class)
本质上case class是个语法糖,对你的类构造参数增加了getter访问,还有toString, hashCode, equals 等方法;
最重要的是帮你实现了一个伴生对象,这个伴生对象里定义了apply 方法和 unapply 方法。
apply方法是用于在构造对象时,减少new关键字;而unapply方法则是为模式匹配所服务。
这两个方法可以看做两个相反的行为,apply是构造(工厂模式),unapply是分解(解构模式)。
case class在暴露了它的构造方式,所以要注意应用场景:当我们想要把某个类型暴露给客户,但又想要隐藏其数据表征时不适宜。
2) 抽取器(extrator)
抽取器是指定义了unapply方法的object。在进行模式匹配的时候会调用该方法。
unapply方法接受一个数据类型,返回另一数据类型,表示可以把入参的数据解构为返回的数据。
比如
class A
class B(val a:A)
object TT {
def unapply(b:B) = Some(new A)
}
这样定义了抽取器TT后,看看模式匹配:val b = new B(new A); b match{ case TT(a) => println(a) }
直观上以为 要拿b和TT类型匹配,实际被翻译为 TT.unapply(b) match{ case Some(…) => … }
它与上面的case class相比,相当于自己手动实现unapply,这也带来了灵活性。
后续会专门介绍一下extrator,这里先看一下extractor怎么实现case class无法实现的”表征独立”(representation independence)
比如我们想要暴露的类型为A
//定义为抽象类型
trait A
//然后再实现一个具体的子类,有2个构造参数
class B (val p1:String, val p2:String) extends A
//定义一个抽取器
object MM{
//抽取器中apply方法是可选的,这里是为了方便构造A的实例
def apply(p1:String, p2:String) : A = new B(p1,p2);
//把A分解为(String,String)
def unapply(a:A) : Option[(String, String)] = {
if (a.isInstanceOf[B]) {
val b = a.asInstanceOf[B]
return Some(b.p1, b.p2)
}
None
}
}
这样客户只需要通过 MM(x,y) 来构造和模式匹配了。客户只需要和MM这个工厂/解构角色打交道,A的实现怎么改变都不受影响。
注:
有很多的资料里在介绍case class时经常把它和函数式语言里的代数数据类对比(ADT)
严格的说Scala中的case class并不是ADT,但比较靠近,可以模拟ADT。
这篇文章中提到case class介于类继承和代数数据类型之间 http://blog.csdn.net/jinxfei/article/details/4677359
提到:”Scala则提供了一种介于两者之间(类继承和代数数据类型),被称为条件类(case classes)的概念”
《Programming in Scala》中文版,在术语表中有提到ADT:
通过提供若干个含有独立构造器的备选项(alternative)来定义的类型。通常可以辅助于通过模式匹配解构类型的方式。
这个概念可以在规约语言和函数式语言中发现。代数数据类型在Scala中可以用样本类(case class)模拟。
转自:http://ifeve.com/pattern-matching-2/