参考文档
https://www.jianshu.com/p/486b0965c296
概念说明
用户空间和内核空间
现在操作系统都是采用虚拟存储器,那么对32位操作系统而言,它的寻址空间(虚拟存储空间)为4G(2的32次方)。
操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核(kernel),保证内核的安全,操作系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。针对linux操作系统而言,将最高的1G字节(从虚拟地址0xC0000000到0xFFFFFFFF),供内核使用,称为内核空间,而将较低的3G字节(从虚拟地址0x00000000到0xBFFFFFFF),供各个进程使用,称为用户空间。进程切换
为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的执行。这种行为被称为进程切换。因此可以说,任何进程都是在操作系统内核的支持下运行的,是与内核紧密相关的
从一个进程的运行转到另一个进程上运行,这个过程中经过下面这些变化:
1)保存处理机上下文,包括程序计数器和其他寄存器。
2)更新PCB信息。
3)把进程的PCB移入相应的队列,如就绪、在某事件阻塞等队列。
4)选择另一个进程执行,并更新其PCB。
5)更新内存管理的数据结构。
6)恢复处理机上下文
进程的阻塞
正在执行的进程,由于期待的某些事件未发生,如请求系统资源失败、等待某种操作的完成、新数据尚未到达或无新工作做等,则由系统自动执行阻塞原语(Block),使自己由运行状态变为阻塞状态。可见,进程的阻塞是进程自身的一种主动行为,也因此只有处于运行态的进程(获得CPU),才可能将其转为阻塞状态。当进程进入阻塞状态,是不占用资源的
文件描述符
我们都知道unix(Linux)世界里,一切皆文件,而文件是什么呢?文件就是一串二进制流而已,不管socket,还是FIFO、管道、终端,对我们来说,一切都是文件,一切都是流。在信息交换的过程中,我们都是对这些流进行数据的收发操作,简称为I/O操作(input and output),往流中读出数据,系统调用read,写入数据,系统调用write。不过计算机里有这么多的流,我怎么知道要操作哪个流呢?对,就是文件描述符,即通常所说的fd,一个fd就是一个整数,所以,对这个整数的操作,就是对这个文件(流)的操作。我们创建一个socket,通过系统调用会返回一个文件描述符,那么剩下对socket的操作就会转化为对这个描述符的操作。
文件描述符(File descriptor)是计算机科学中的一个术语,是一个用于表述指向文件的引用的抽象化概念。文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于UNIX、Linux这样的操作系统。
缓存io
缓存 IO 又被称作标准 IO,大多数文件系统的默认 IO 操作都是缓存 IO。在 Linux 的缓存 IO 机制中,操作系统会将 IO 的数据缓存在文件系统的页缓存( page cache )中,也就是说,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。缓存 IO 的缺点:
数据在传输过程中需要在应用程序地址空间和内核进行多次数据拷贝操作,这些数据拷贝操作所带来的 CPU 以及内存开销是非常大的。Linux IO模型
网络IO的本质是socket的读取,socket在linux系统被抽象为流,IO可以理解为对流的操作。刚才说了,对于一次IO访问(以read举例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。所以说,当一个read操作发生时,它会经历两个阶段:第一阶段:等待数据准备 (Waiting for the data to be ready)。
第二阶段:将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
网络应用需要处理的无非就是两大类问题,网络IO,数据计算。相对于后者,网络IO的延迟,给应用带来的性能瓶颈大于后者。网络IO的模型大致有如下几种:
同步阻塞io
同步非阻塞io
io多路复用io
信号量io
异步io
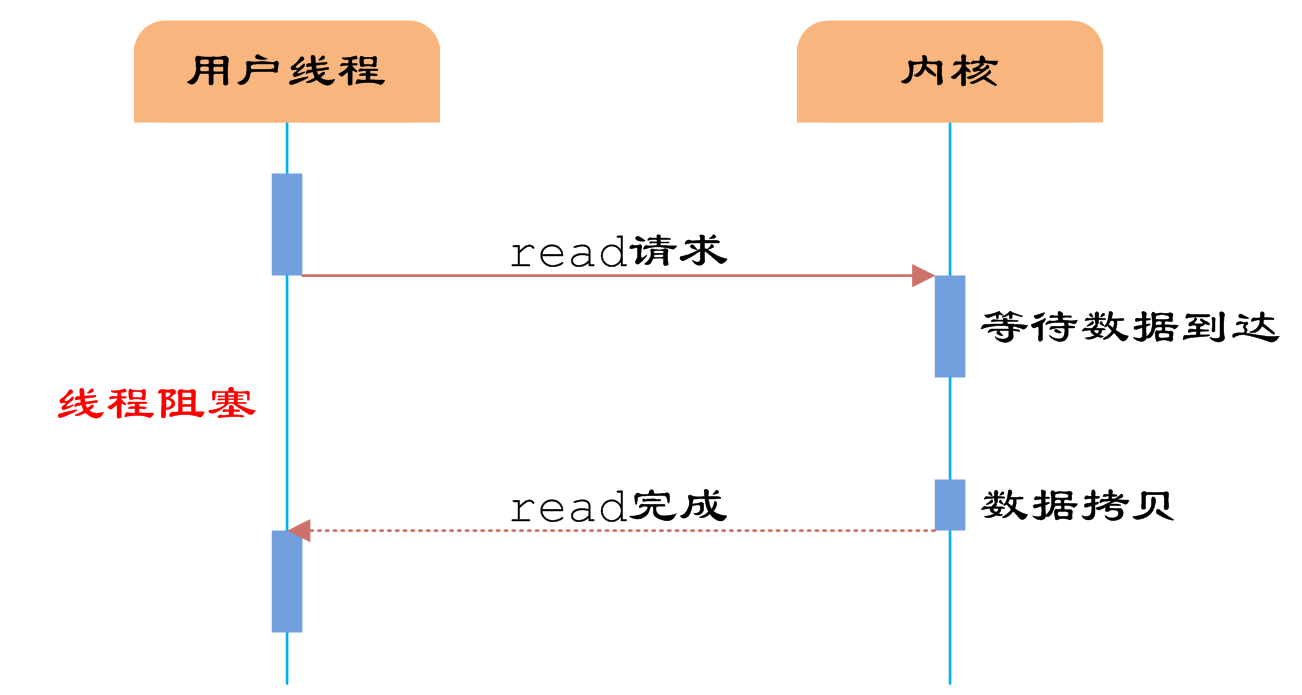
同步阻塞 IO(blocking IO)
在这个IO模型中,用户空间的应用程序执行一个系统调用(recvform),这会导致应用程序阻塞,什么也不干,直到数据准备好,并且将数据从内核复制到用户进程,最后进程再处理数据,在等待数据到处理数据的两个阶段,整个进程都被阻塞。不能处理别的网络IO。
调用应用程序处于一种不再消费 CPU 而只是简单等待响应的状态,因此从处理的角度来看,这是非常有效的。在调用recv()/recvfrom()函数时,发生在内核中等待数据和复制数据的过程, 当用户进程调用了recv()/recvfrom()这个系统调用,
kernel就开始了IO的第一个阶段:准备数据(对于网络IO来说,很多时候数据在一开始还没有到达。比如,还没有收到一个完整的UDP包。这个时候kernel就要等待足够的数据到来)。这个过程需要等待,也就是说数据被拷贝到操作系统内核的缓冲区中是需要一个过程的。而在用户进程这边,整个进程会被阻塞(当然,是进程自己选择的阻塞)。第二个阶段:当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。优点:
>够及时返回数据,无延迟
>对内核开发者来说这是省事了
缺点:
>对用户来说处于等待就要付出性能的代价了
同步非阻塞io

当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。
优点:
能够在等待任务完成的时间里干其他活了(包括提交其他任务,也就是 “后台” 可以有多个任务在同时执行)。
缺点:任务完成的响应延迟增大了,因为每过一段时间才去轮询一次read操作,而任务可能在两次轮询之间的任意时间完成。这会导致整体数据吞吐量的降低。
io多路复用
同步是需要主动等待消息通知,而异步是被动接收消息通知,通过回调、通知、状态等方式来被动获取消息。IO多路复用阻塞到select阶段时,用户进程是主动等待并调用select函数获取数据就绪状态消息,
并且其进程状态为阻塞。所以,把IO多路复用归为阻塞模式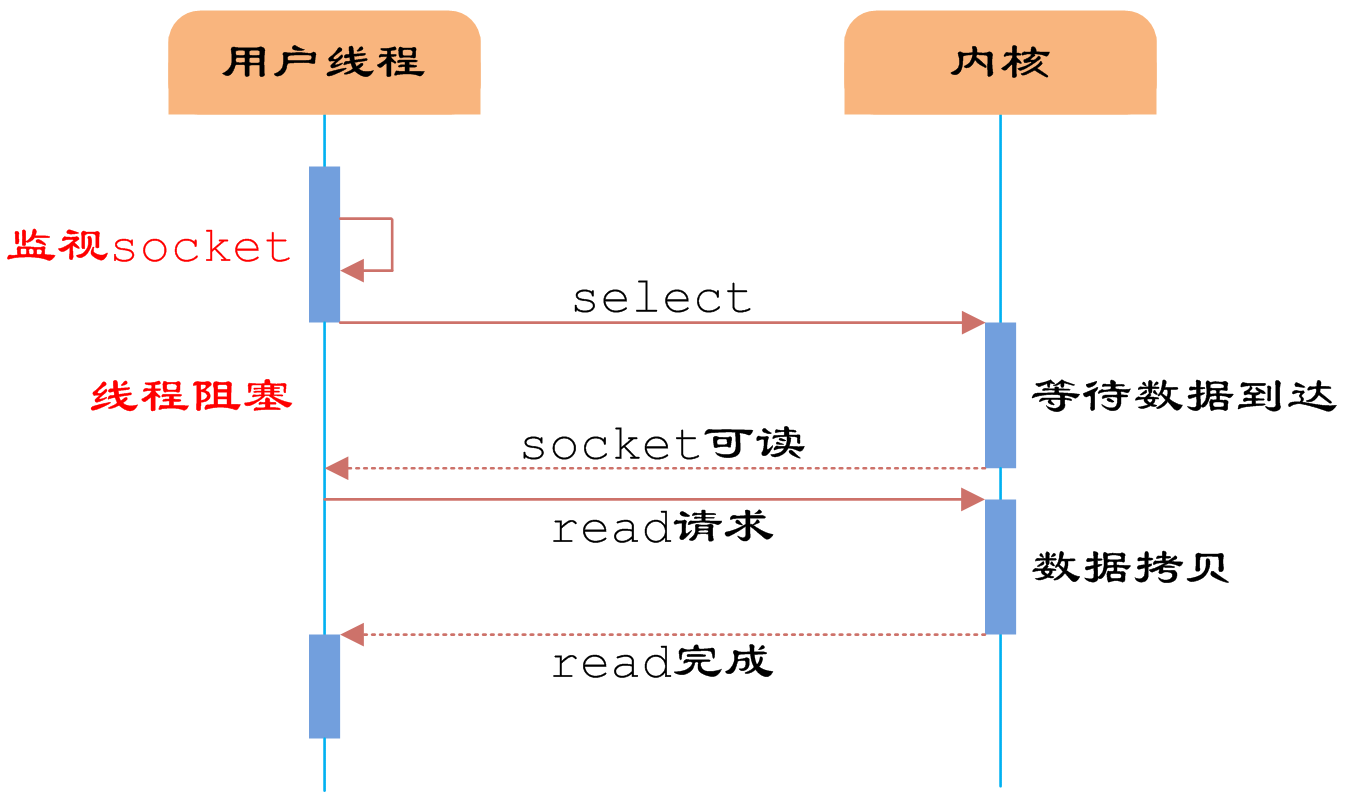
IO multiplexing就是我们说的select,poll,epoll,有些地方也称这种IO方式为event driven IO。
select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select,poll,epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。 上面的图和blocking IO的图其实并没有太大的不同,事实上,还更差一些。
因为这里需要使用两个system call (select 和 recvfrom),而blocking IO只调用了一个system call (recvfrom)。但是,用select的优势在于它可以同时处理多个connection。所以,如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。(select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。)在IO multiplexing Model中,实际中,对于每一个socket,一般都设置成为non-blocking,但是,如上图所示,整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket IO给block。所以IO多路复用是阻塞在select,epoll这样的系统调用之上,而没有阻塞在真正的I/O系统调用如recvfrom之上。在I/O编程过程中,当需要同时处理多个客户端接入请求时,可以利用多线程或者I/O多路复用技术进行处理。I/O多路复用技术通过把多个I/O的阻塞复用到同一个select的阻塞上,从而使得系统在单线程的情况下可以同时处理多个客户端请求。与传统的多线程/多进程模型比,I/O多路复用的最大优势是系统开销小,系统不需要创建新的额外进程或者线程,也不需要维护这些进程和线程的运行,降底了系统的维护工作量,节省了系统资源信号驱动式IO(signal-driven IO)
信号驱动式I/O:首先我们允许Socket进行信号驱动IO,并安装一个信号处理函数,进程继续运行并不阻塞。当数据准备好时,进程会收到一个SIGIO信号,可以在信号处理函数中调用I/O操作函数处理数据。过程如下图所示: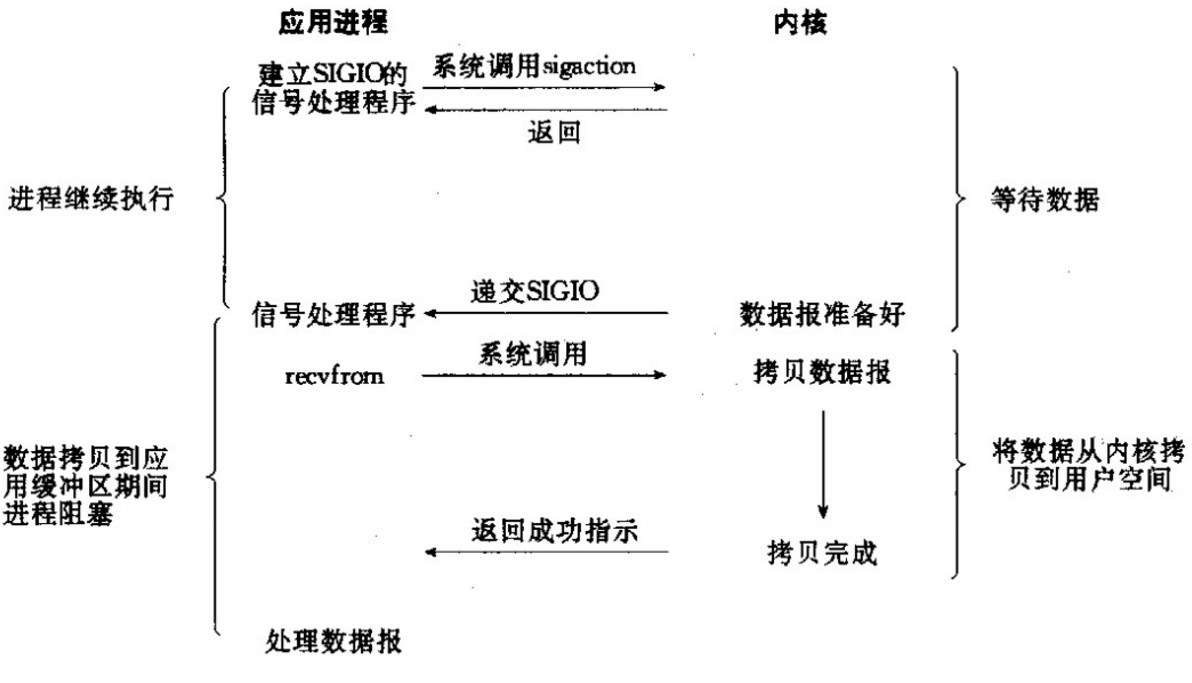
异步非阻塞 IO(asynchronous IO)

用户进程发起aio_read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成以后,kernel会给用户进程发送一个signal或执行一个基于线程的回调函数来完成这次IO处理过程,告诉它read操作完成了。
五种IO模型总结
blocking和non-blocking区别
调用blocking IO会一直block住对应的进程直到操作完成,而non-blocking IO在kernel还准备数据的情况下会立刻返回。synchronous IO和asynchronous IO区别
在说明synchronous IO和asynchronous IO的区别之前,需要先给出两者的定义。POSIX的定义是这样子的: synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes
An asynchronous I/O operation does not cause the requesting process to be blocked
两者的区别就在于synchronous IO 做"IO operation"的时候会将process阻塞。按照这个定义,之前所述的blocking IO,non-blocking IO,IO multiplexing都属于synchronous IO。有人会说,non-blocking IO并没有被block啊。这里有个非常“狡猾”的地方,定义中所指的"IO operation"是指真实的IO操作,就是例子中的recvfrom这个system call。non-blocking IO在执行recvfrom这个system call的时候,如果kernel的数据没有准备好,这时候不会block进程。但是,当kernel中数据准备好的时候,recvfrom会将数据从kernel拷贝到用户内存中,这个时候进程是被block了,在这段时间内,进程是被block的。而asynchronous IO则不一样,当进程发起IO操作之后,就直接返回再也不理睬了,知道kernel发送一个信号,告诉进程说IO完成。在这整个过程中,进程完全没有被block。
各个IO Model的比较如图所示:
