一、聚类
聚类属于无监督学习,是其中研究最多,应用最广的算法。
作用:
(1)作为一个单独过程,寻找数据内部分布结构
(2)作为分类等其他学习任务的前驱过程
性能度量:
聚类性能度量亦称“有效性指标”,由此来评估聚类模型的好坏,并可将其作为聚类过程的优化目标。
聚类的目标:
簇内相似度(intra-cluster similarity)高且簇间相似度(inter-cluster similarity)低。
两个基本问题:
性能度量与距离计算
二、性能度量
两类度量指标:
外部指标:将聚类结果与某个“参考模型”进行比较
内部指标:直接考察聚类结果不利用任何参考模型
常用的外部指标:
对数据集D=x1,x2,...,xm,假定通过聚类给出的簇划分为C={C1,C2,...,Ck},参考模型给出簇划分为C∗={C∗1,C∗2,...,C∗s},相应的,令λ与λ∗分别表示与C和C∗对应的簇标记向量。将样本两两配对,定义:
a=|SS|, SS={(xi,xj)|λi=λj,λ∗i=λ∗j,i<j)}
b=|SD|, SD={(xi,xj)|λi=λj,λ∗i≠λ∗j,i<j)}
c=|DS|, DS={(xi,xj)|λi≠λj,λ∗i=λ∗j,i<j)}
d=|DD|, DD={(xi,xj)|λi≠λj,λ∗i≠λ∗j,i<j)}
其中集合SS中表示包含在C中属于相同簇且在C∗中也属于相同簇的样本对,以此类推。
基于以上定义可以导出下面常用的聚类性能度量外部指标:
(1)Jaccard系数:
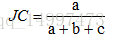
(2)FM指数:
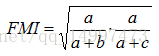
(3)Rand 指数:
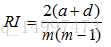
上述结果均在[0,1]区间,值越大越好。
常用的内部指标:
对于聚类结果的簇划分C={C1,C2,...,Ck},定义:
簇内平均距离:
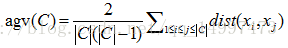
簇内最远距离:diam(C)=max1≤i<j≤|C|dist(xi,xj)
簇间最近距离:dmin(Ci,Cj)=minxi∈Ci,xj∈Cjdist(xi,xj)
簇间的中心距离:dcen(Ci,Cj)=dist(μi,μj)
基于以上定义,我们列出以下聚类性能度量内部指标:
(1)DB指数:

(2)Dunn指数:
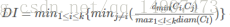
DBI值越小效果越好,DI值越大效果越好。
三、距离计算
对函数dist(·),若他是一个距离度量,则需要满足如下基本性质:
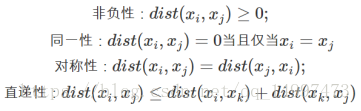
给定样本:xi=(xi1,xi2,...,xin)与xj=(xj1,xj2,...,xjn),按数据属性分类定义以下公式:
1.有序属性
“闵可夫斯基距离”:
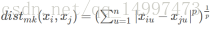
当p=1即为哈曼顿距离,当p=2即为欧氏距离。
2.无序属性
VDM距离:
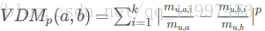
其中mu,a表示在属性u上取值为a的样本数,mu,a,i表示在第i个样本簇中在属性u上取值为a的样本数,k为样本簇数。
3.混合属性
将闵可夫斯基距离与VDM距离混合: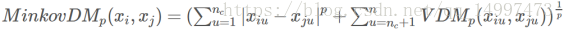
其中有nc个有序属性,n-nc个无序属性。
4.不同属性重要性不同
当样本空间中不同属性重要性不同时,可使用“加权距离”(以闵可夫斯基距离为例):
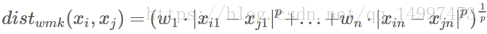
四、分类
(1)划分聚类:k-means、k-medoids、k-modes、k-medians、kernel k-means
(2)层次聚类:Agglomerative、divisive、BIRCH、ROCK、Chameleon
(3)密度聚类:DBSCAN、OPTICS
(4)网格聚类:STING
(5)模型聚类:GMM
(6)图聚类:Spectral Clustering(谱聚类)