前两天,想抢购一个小米MIX,结果,一开始抢就没有了。于是想,作为程序猿,总得有点特殊手段吧,比如说一个小脚本。最近在学习python,百度了一下,发现了Splinter这个强大的东东!用了不到两小时的时间,就可以实现许多令人点赞的功能,真让人很兴奋呐!
首先,官网(https://splinter.readthedocs.io/en/latest/index.html)介绍,一句话,一个开源工具用来通过python自动化测试web,让电脑自动操作网页:
Splinter is an open source tool for testing web applications using Python. It lets you automate browser actions, such as visiting URLs and interacting with their items.
既然可以自动操作网页,当然不局限于自动化测试喽!
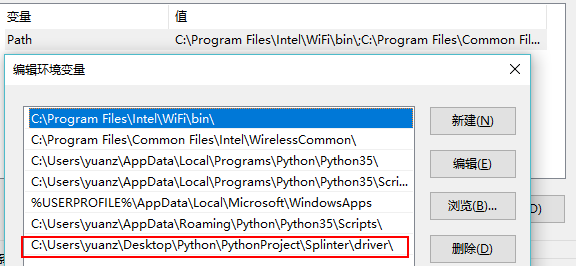
第一步,下载Splinter模块和Chrome或FireFox的驱动(就是强大的开源web自动化测试框架selenium的驱动)。
Splinter模块是python egg,下载当然很简单:pip install splinter
由于基于selenium,所以,FireFox和Chrome的驱动,都依赖于pip install selenium,不过好像执行pip install splinter之后默认就已经安装了,没有的话再安装一下。
我这个用Chrome的驱动chromedriver,注意版本要对应,不然基本上会有unknown error,打不开浏览器!
官网下载地址:https://sites.google.com/a/chromium.org/chromedriver/downloads 当然这里需要可以连接上google!
selenium 3.x开始,webdriver/firefox/webdriver.py的__init__中,executable_path="geckodriver",所以火狐浏览器需要这个驱动!
下载地址:https://github.com/mozilla/geckodriver/releases/
上述驱动也可以在selenium官网中查找并下载:http://docs.seleniumhq.org/download/
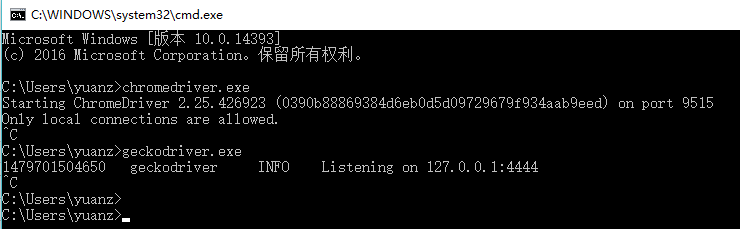
这样,Splinter就可以自动打开浏览器,并进行操作了!
WebDriverException: Message: Expected browser binary location, but unable to find binary in default location, no 'moz:firefoxOptions.binary' capability provided, and no binary flag set on the command line

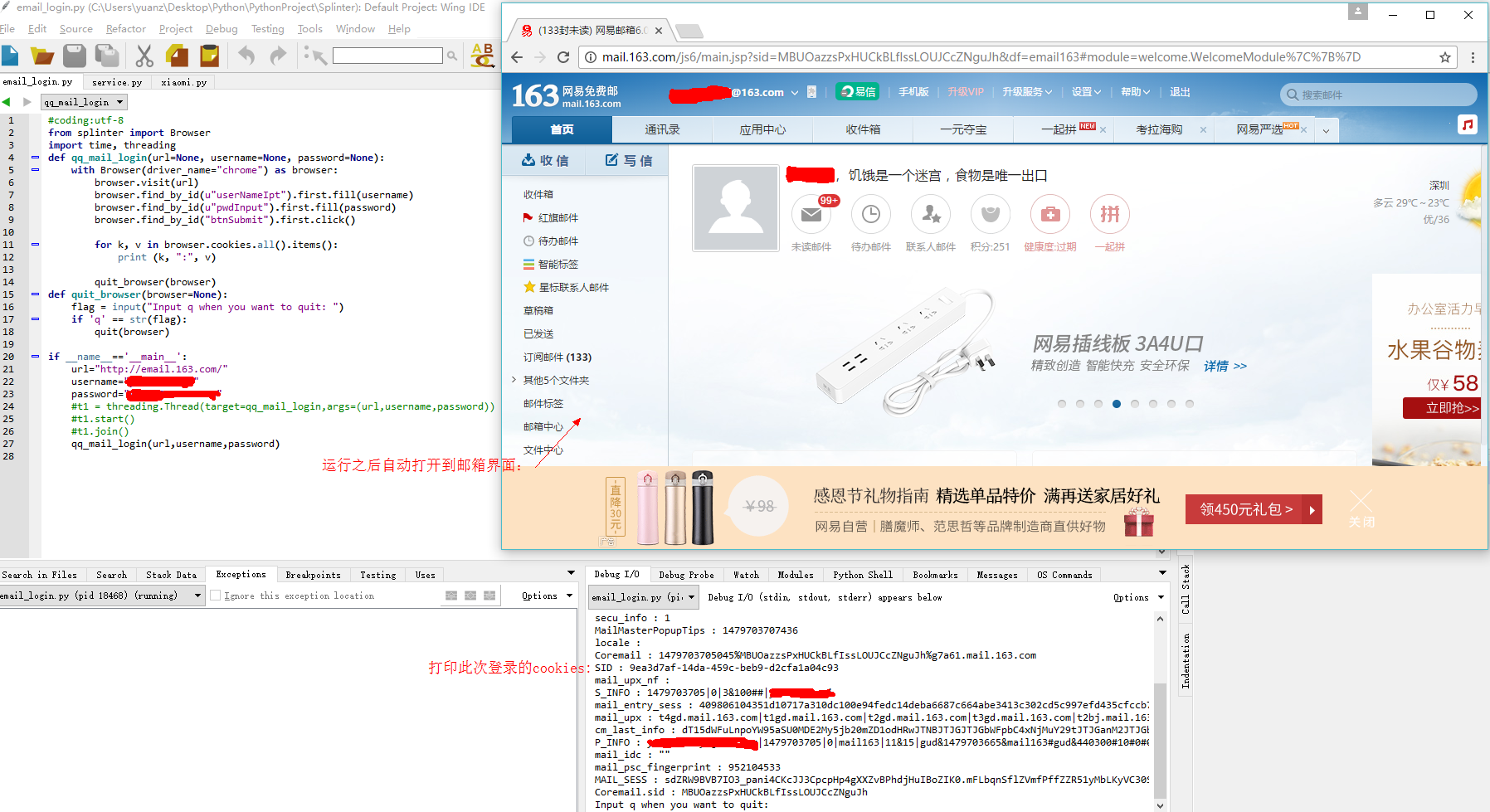
#coding:utf-8 from splinter import Browser import time, threading def qq_mail_login(url=None, username=None, password=None): with Browser(driver_name="chrome") as browser: browser.visit(url) browser.find_by_id(u"userNameIpt").first.fill(username) browser.find_by_id(u"pwdInput").first.fill(password) browser.find_by_id("btnSubmit").first.click() for k, v in browser.cookies.all().items(): print (k, ":", v) quit_browser(browser) def quit_browser(browser=None): flag = input("Input q when you want to quit: ") if 'q' == str(flag): quit(browser) if __name__=='__main__': url="http://email.163.com/" username="你的邮箱地址" password="你的邮箱密码" #t1 = threading.Thread(target=qq_mail_login,args=(url,username,password)) #t1.start() #t1.join() qq_mail_login(url,username,password)
运行效果就是,你什么都不用管,可以自动用指定浏览器打开你的邮箱:
#coding:utf-8 from splinter import Browser import time, threading def qq_mail_login(url=None, username=None, password=None): with Browser(driver_name="chrome") as browser: browser.visit(url[0]) #进入登录界面 browser.click_link_by_href("//order.mi.com/site/login?redirectUrl=http://www.mi.com/") #输入用户名密码,完成登录 browser.find_by_id(u"username").first.fill(username) browser.find_by_id(u"pwd").first.fill(password) browser.find_by_id("login-button").first.click() time.sleep(1) #进入购买界面 browser.visit(url[1]) #点击购买“下一步” count = 1 while not browser.is_element_not_present_by_id('J_chooseResultInit'): print ("第",count,"次: ",browser.is_element_not_present_by_id('J_chooseResultInit')) time.sleep(10) count += 1 browser.find_by_id("J_chooseResultInit").first.click() quit_browser(browser) def quit_browser(browser=None): flag = input("Input q when you want to quit: ") if 'q' == str(flag): quit(browser) if __name__=='__main__': url=["http://www.mi.com/","http://item.mi.com/buyphone/mix/"] username="你的用户名" password="你的密码" #t1 = threading.Thread(target=qq_mail_login,args=(url,username,password)) #t1.start() #t1.join() qq_mail_login(url,username,password)