转载
一只小小的寄居蟹
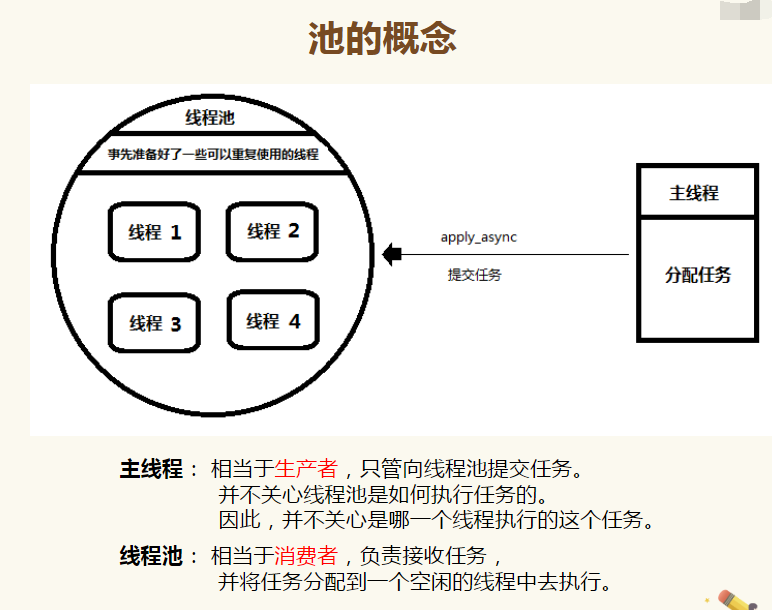
一个为什么要有进程池?进程池的概念。
在程序实际处理问题过程中,忙时会有成千上万的任务需要被执行,闲时可能只有零星任务。那么在成千上万个任务需要被执行的时候,我们就需要去创建成千上万个进程么?首先,创建进程需要消耗时间,销毁进程也需要消耗时间。第二即便开启了成千上万的进程,操作系统也不能让他们同时执行,这样反而会影响程序的效率。因此我们不能无限制的根据任务开启或者结束进程。那么我们要怎么做呢?
在这里,要给大家介绍一个进程池的概念,定义一个池子,在里面放上固定数量的进程,有需求来了,就拿一个池中的进程来处理任务,等到处理完毕,进程并不关闭,而是将进程再放回进程池中继续等待任务。如果有很多任务需要执行,池中的进程数量不够,任务就要等待之前的进程执行任务完毕归来,拿到空闲进程才能继续执行。也就是说,池中进程的数量是固定的,那么同一时间最多有固定数量的进程在运行。这样不会增加操作系统的调度难度,还节省了开闭进程的时间,也一定程度上能够实现并发效果
自带线程 1、
# pool.map(worker,msg_list)
from multiprocessing.pool import ThreadPool #线程池
from multiprocessing import Pool #进程池
import random
import time
#IO密集型
def worker(msg):
time.sleep(2)
print(msg)
msg_list = [1,2,3,4,5,6,7,8,9]
pool = ThreadPool(4) #实现一个线程池 ,参数是线程的数量
pool.map(worker,msg_list) #map方法会把序列里面的元素 一个一个的传入前面的方法 这个msg_list里面可以装任何东西 比如url
#因为上面是4个线程, 所以会4个一起执行,1、sleep 2秒 2、打印1234 3、sleep 2秒 4、打印5678
'''
打印下面的
4
2
3
1
停顿2秒
6
5
7
8
停顿2秒
9
'''
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
#
pool.apply_async(worker) 线程方法
from multiprocessing.pool import ThreadPool #线程池
from multiprocessing import Pool #进程池
import random
import time
start_time = time.time()
#IO密集型
def worker():
print("111111")
pool = ThreadPool(2) #实现一个线程池 ,参数是线程的数量
pool.apply_async(worker)
pool.apply_async(worker)
pool.apply_async(worker)
pool.apply_async(worker)
#没有打印是因为主线程已经结束, 如果要打印就需要加阻塞, 等待打印
pool.close() #关闭线程池, 不在提交任务,
pool.join() #等待线程池里面的任务 运行完毕
print(time.time() - start_time)
-----------------------------------------------------------------------------------------------------------------------------------------------
#自己写单线程池
import threading
import queue
class MyThread(threading.Thread): #继承线程类
def __init__(self):
super().__init__() #2、对父类进行初始化的过程
self.queue = queue.Queue()
#self.daemon = True #随着主线程一起退出 (守护线程)
self.start() #3、开启线程
#4、这是一个简单的方法, 只要上面的初始化运行了, 下面就开始运行
def run(self): #这只是一个线程run方法, 、让他始终去运行、去获取queue里面的任务、然后给任务分配函数去执行(获取任务在执行)
while True: #5、让他始终去运行
func,args,kwargs = self.queue.get() #8、去获取queue里面的任务 (这个地方涉及到万能传参args,kwarsg,所以要用func,args,kwargs))
func(*args,**kwargs) #9、然后给任务分配函数去执行
self.queue.task_done() #计数器 执行完这个任务后 (队列-1操作)
def apply_async(self,func,args = (),kwargs = {}): #7、这个是给队列(queue) 放任务的函数 (接受任务)
self.queue.put((func,args,kwargs)) #给了放(put)一个任务 (放任务的时候, 有时候不可能只有一个参数, 有好几个)
def join(self, timeout=None):
self.queue.join() #等待队列里面的任务处理完毕 self.queue.task_done()这句会让queue.join实现不阻塞
def func1(): #**********************重点10、 10.1、 10.2 一起作为线程运行的函数, 也就是消费者***************************
print("func1")
def func2(): #10.1
print("func2")
def func3(): #10.2
print("func3")
t = MyThread() # 1、实例了一个线程对象
t.apply_async(func1) #6、生产者, 开始给队列里面放东西
t.apply_async(func2)
t.apply_async(func3)
t.join()
print("处理完毕")