20172313 2018-2019-1 《程序设计与数据结构》第六周学习总结
教材学习内容总结
- 概述
- 树是一种非线性结构,其中的元素被组织成一个层次结构。
- 树由一个包含结点(node)和(edge)的集构成,其中的元素被存储在这些结点中,边则将一个结点和另一个结点连接起来。每一结点都位于该数层次结构中的某一特定层上,树的根就是那个位于该树顶层的唯一结点。一棵树只有一个根结点。
- 基本术语:
- 结点:存储数据元素和指向子树的链接,由数据元素和构造数据元素之间关系的引用组成。
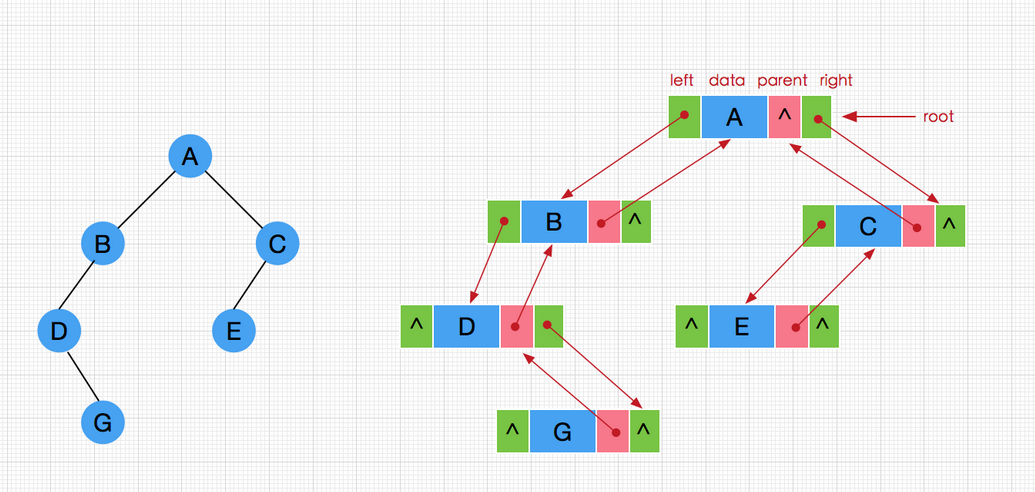
- 孩子结点:树中一个结点的子树的根结点称为这个结点的孩子结点,如图1中的A的孩子结点有B、C、D
- 双亲结点:树中某个结点有孩子结点(即该结点的度不为0),该结点称为它孩子结点的双亲结点,也叫前驱结点。双亲结点和孩子结点是相互的,如图1中,A的孩子结点是B、C、D,B、C、D的双亲结点是A。
- 兄弟结点:具有相同双亲结点(即同一个前驱)的结点称为兄弟结点,如图1中B、B、D为兄弟结点。
- 结点的度:结点所有子树的个数称为该结点的度,如图1,A的度为3,B的度为2。
- 树的度:树中所有结点的度的最大值称为树的度,如图1的度为3。
- 叶子结点:度为0的结点称为叶子结点,也叫终端结点。如图1的K、L、F、G、M、I、J
- 分支结点:度不为0的结点称为分支结点,也叫非终端结点。如图1的A、B、C、D、E、H
- 结点的层次:从根结点到树中某结点所经路径的分支数称为该结点的层次。根结点的层次一般为1(也可以自己定义为0),这样,其它结点的层次是其双亲结点的层次加1。
- 树的深度:树中所有结点的层次的最大值称为该树的深度(也就是最下面那个结点的层次)
- 有序树和无序树:树中任意一个结点的各子树按从左到右是有序的,称为有序树,否则称为无序树。
- 我们将每一节点限制为不超过n个孩子的树称为n叉树。
- 如果说树的所有叶子都位于同一层或者至少是彼此相差不超过一个层,就称之为平衡的。
- 如果某树是平衡的,且底层所有叶子都位于树的左边,则认为该树是完全的。
- 树的数组实现之计算策略
- 树的数组实现之计算策略:
- 一种可能的计算策略是将元素n的左孩子置于位置(2 * n-1),将右孩子置于位置(2 *(n+1))
- 优点:我们可以依照容量对其进行管理,这与我们用数组实现列表、队列和栈且对其进行容量管理时的方式基本一样。
- 缺点:如果存储的树不是完全的或只是相对完全的,则该数组会为不包括数据的树位置分配空间,浪费了大量的存储空间。
- 树的数组实现之模拟链接策略:
- 模拟链接策略允许连续分配数组位置而不用考虑该树的完全性。
- 该数组的每一元素都是一个结点类,每一节点存储的是每一孩子(可能还有其双亲)的数组索引,而不是作为指向其孩子(可能还有其双亲)指针的对象引用变量。
- 优点:这种方式是的元素能够连续存储在数组中,因此不会浪费空间。
- 缺点:该方式增加了删除树中元素的成本,因为它要么需要对生育元素进行移位以维持连续状态,要么需要保留一个空闲列表。
- 一般而言,一棵含有m各元素的平衡n元树具有的高度为lognm。
- 树的数组实现之计算策略:
- 树的遍历
- 前序遍历: 从根结点开始,访问每一结点及其孩子。
Visit node Traverse(left child) Traverse(right child)- 中序遍历: 从根节点开始,访问结点的左孩子,然后是该结点,再然后是任何剩余结点。
Traverse(left child) Visit node Traverse(right child)- 后序遍历: 从根结点开始,访问结点的孩子,然后是该结点。
Traverse(left child) TRaverse(right child) Visit node- 层序遍历: 从根结点开始,访问每一层的所有结点,访问每一层的所有结点,一次一层。
Creat a queue called nodes Create an unordered list calles results Enqueue the root onto the nodes queue while the nodes queue is not empty { Dequeue the first element from the queue If that element is not null Add that element to the rear of the results list Enqueue the children of the element on the nodes queue Else Add null on the result list } Return an iterator for the result list - 二叉树
| 操作 | 最差时间复杂度 |
|---|---|
| getRoot | 返回指向二叉树根的引用 |
| isEmpty | 判定该树是否为空 |
| size | 判定树中的元素数目 |
| contains | 判定指定目标是否在该树中 |
| find | 如果找到指定元素,则返回指向其的引用 |
| toString | 返回树的字符串表示 |
| itertorInOrder | 为树的中序遍历返回一个迭代器 |
| itertorPreOrder | 为树的前序遍历返回一个迭代器 |
| iteratorPostOrder | 为树的后序遍历返回一个迭代器 |
| iteratorLevelOrder | 为树的层序遍历返回一个迭代器 |
- 二叉树的性质
-
若二叉树的根节点位于第一层
- 在二叉树的第i层最多有2i-1个结点。
- 深度为k的二叉树最多有2k-1个结点。
- 对任何一棵二叉树,如果其叶结点个数为n0,度为2的结点数为n2则有n0=n2+1。
-
两种特殊的二叉树
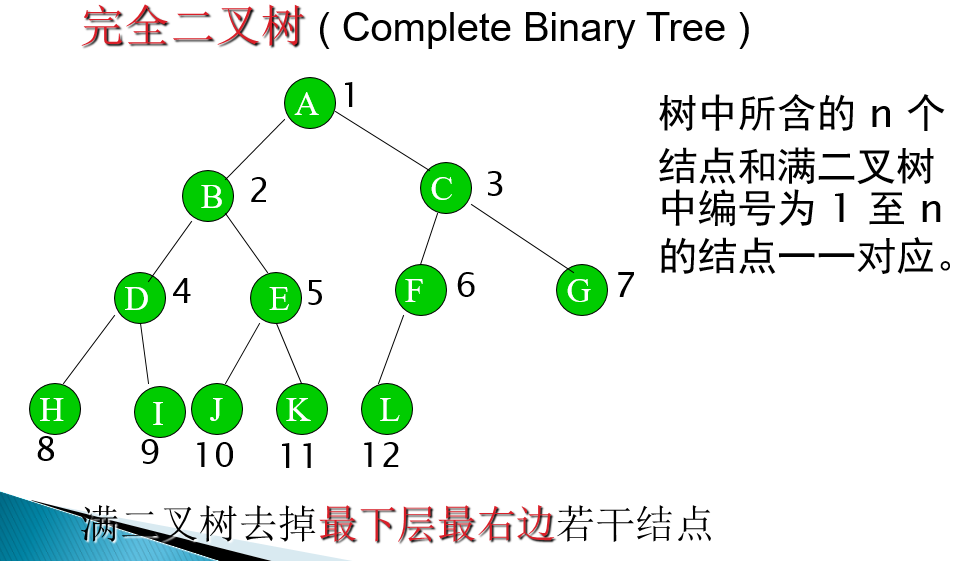
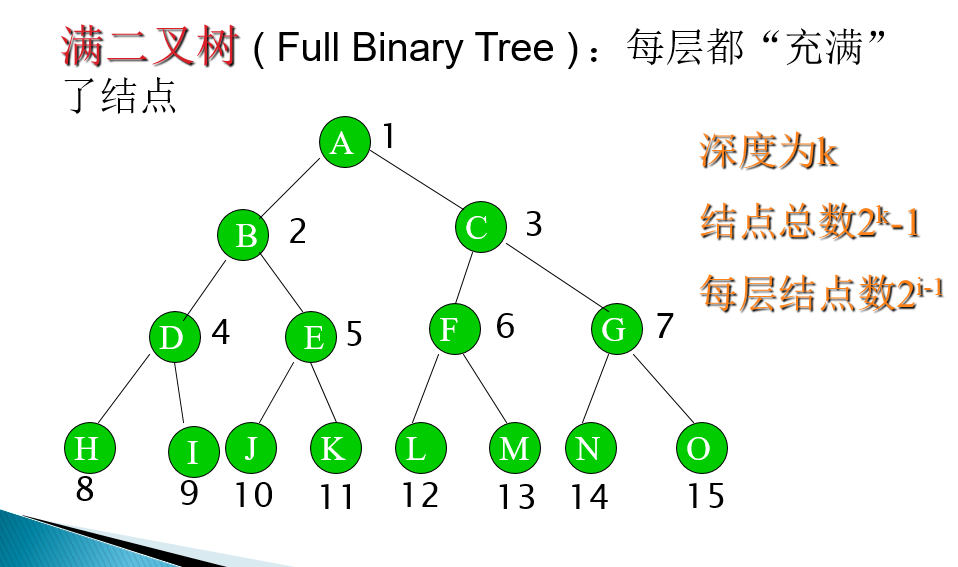
-
完全二叉树的性质
- 具有n个结点的完全二叉树的高度为log2n(下取整)+1
- 如果将一棵有n个结点的完全二叉树自顶向下,同一层自左向右给结点编号1,2,3......n,则对于任意结点(1<=i<=n),有:
- 若i= 1,则该i结点是树根,它无双亲;
- 若2i>n,则编号为i的结点无左孩子,否则它的左孩子是编号为2*i的结点;
- 若2i+1>n,则编号为i的结点无右孩子,否则其右孩子结点编号为2*i+1;
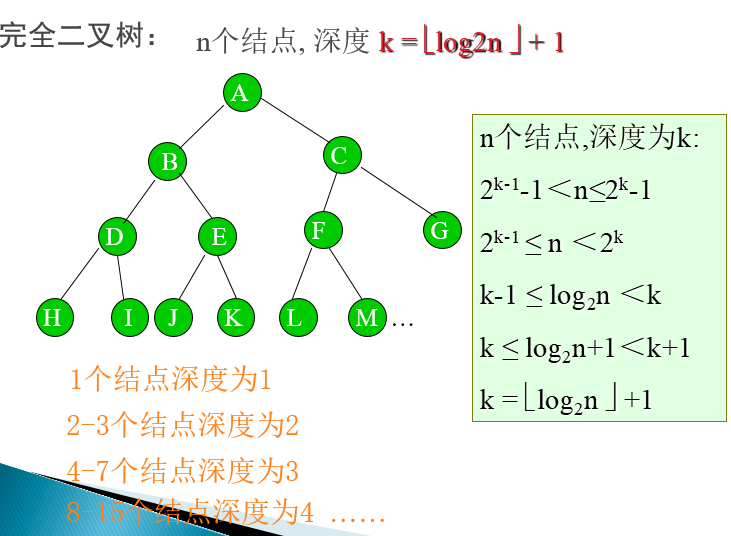
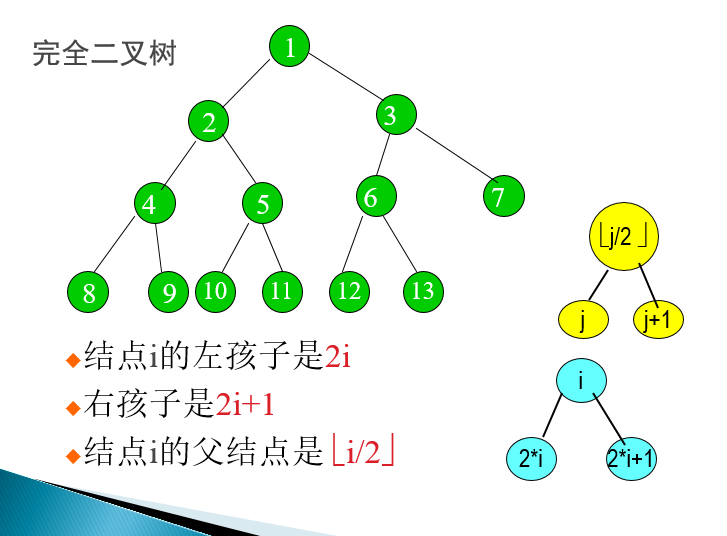
-
二叉树的二叉链表存储结构。二叉链表结构主要由一个数据域和两个分别指向左、右孩子的结点组成,其结构如下:
BinaryNode(T data , BinaryNode<T> left , BinaryNode<T> right ) -

- 二叉树的三叉链表存储结构。三叉链表主要是在二叉链表的基础上多添加了一个指向父结点的域,这样我们就存储了父结点与孩子结点的双向关系,当然这样也增加了一定的空开销其结点结构如下:
ThreeNode(T data ,ThreeNode<T> parent,ThreeNode<T> left,ThreeNode<T> right)
教材学习中的问题和解决过程
- 问题一:在树中Expression中有这样一段代码(如下图代码),由二叉树的性质可知,一棵二叉树当满树的情况时它的结点总数最多为2(depth+1)-1,而书上在这里的int型变量posssibleNodes变量为2(depth+1)-1,但在实际进行操作的时候并不能保证该二叉树是满树,那么为什么可以使用“countNodes < possibleNodes”作为循环条件进行遍历呢?
UnorderedListADT<BinaryTreeNode<ExpressionTreeOp>> nodes =
new ArrayUnorderedList<BinaryTreeNode<ExpressionTreeOp>>();
UnorderedListADT<Integer> levelList =
new ArrayUnorderedList<Integer>();
BinaryTreeNode<ExpressionTreeOp> current;
String result = "";
int printDepth = this.getHeight();
int possibleNodes = (int)Math.pow(2, printDepth + 1);
int countNodes = 0;
nodes.addToRear(root);
Integer currentLevel = 0;
Integer previousLevel = -1;
levelList.addToRear(currentLevel);
while (countNodes < possibleNodes)
{
countNodes = countNodes + 1;
current = nodes.removeFirst();
currentLevel = levelList.removeFirst();
if (currentLevel > previousLevel)
{
result = result + "
";
previousLevel = currentLevel;
for (int j = 0; j < ((Math.pow(2, (printDepth - currentLevel))) - 1); j++)
result = result + " ";
}
else
{
for (int i = 0; i < ((Math.pow(2, (printDepth - currentLevel + 1)) - 1)) ; i++)
{
result = result + " ";
}
}
if (current != null)
{
result = result + (current.getElement()).toString();
nodes.addToRear(current.getLeft());
levelList.addToRear(currentLevel + 1);
nodes.addToRear(current.getRight());
levelList.addToRear(currentLevel + 1);
}
else {
nodes.addToRear(null);
levelList.addToRear(currentLevel + 1);
nodes.addToRear(null);
levelList.addToRear(currentLevel + 1);
result = result + " ";
}
}
return result;
}
- 问题一解决方案:我们先来分析每一行代码的作用(第一次看到上面这坨代码,有那么多循环,真令人头皮发麻),单用眼看怕是很难看出来,最简单直接的方法就是run一下看运行出来的结果进行对比。先来run一下原本的代码:

OK,没有问题,非常完美。然后注释掉第一个for循环

我们可以清楚的看到左边的空白都没有了,很明显,第一个for循环是为了打印每一行最前面的空白来保证“树”的形状,我们再来注释掉第二个循环

同样的,我们可以很明显的看出每一行的两结点处的留白都没有了,现在我们弄明白了两个for循环的作用,免去了它们的干扰,接着我们回过头来看循环条件的问题。我们首先要明确的是这里possibleNodes的值,由于该程序中height是从一开始算的,所以这里的possibleNodes值应该是2的五次方,按照问题里我的想法,这个值的数目应该是远远大于所需要的限定值,我们先适当的缩小possibleNodes的范围看看结果会发生什么变化。(对possibleNodes-1)

结果并没有发生什么变化,这就说明possibleNodes的值确实是偏大的。该二叉树中共有九个元素所以理论上我们只需要九次循环就足够,所以把possibleNodes减去(32-9)(简单的数学问题)23次再试试!


这次就和预期的结果不太一样了,应该是possibleNodes再减去一的时候树才会发生变化才对,为什么现在结点就减少了呢?这时,我发现,树的最下面一层结点靠右侧,在代码表示时是预留了空间的,分别测试possibleNodes为15和14时的情况


如上图所示,跟预期的结果一样,所以综上所述,possibleNodes的限定范围确实是过大的,但是在循环完结点后,剩下的循环次数为打印空白,所以在视觉效果上就跟没有执行一样! - 问题二:ExpressionTreeOp类中定义了一个int型变量termType,在判断一个结点储存的element是都为操作符时返回“termType==1”,对这行代码不是特别明白。
- 问题二解决方案:紧接着教材的学习,有这样的一段代码
if ((operator == '+') || (operator == '-') || (operator == '*') ||
(operator == '/'))
{
operand1 = getOperand(treeStack);
operand2 = getOperand(treeStack);
treeStack.push(new ExpressionTree
(new ExpressionTreeOp(1,operator,0), operand2, operand1));
}
else
{
treeStack.push(new ExpressionTree(new ExpressionTreeOp
(2,' ',Integer.parseInt(tempToken)), null, null));
}
原来,termType的用法是接收传入的形参,判断传入的形参是否为1以此来返回ture或者false来判断是否为操作符。
代码调试中的问题和解决过程
- 问题1:在对方法进行测试时,发现使用toString时会出现空指针的情况
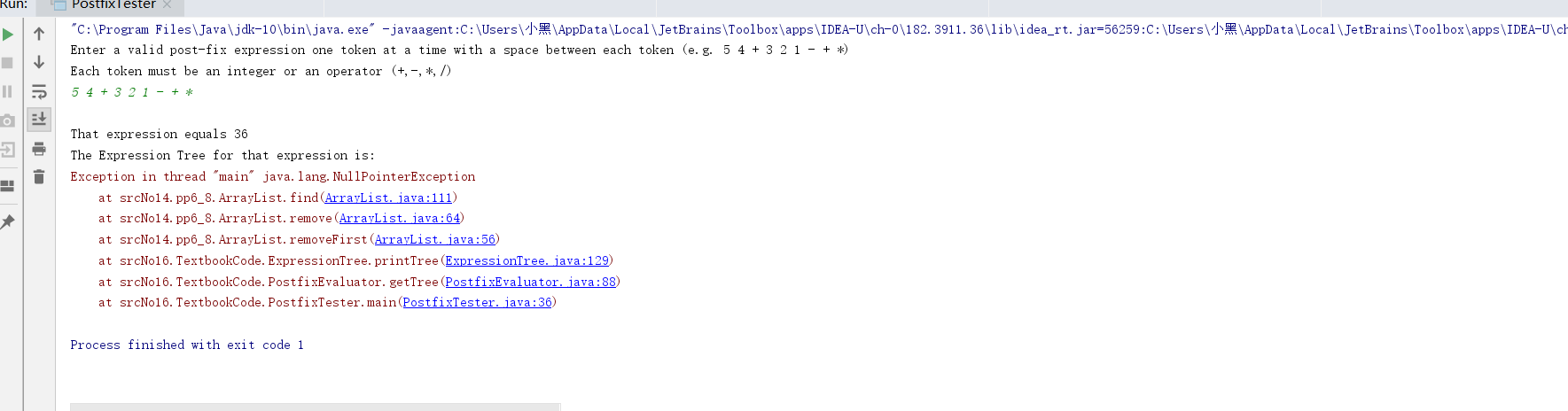
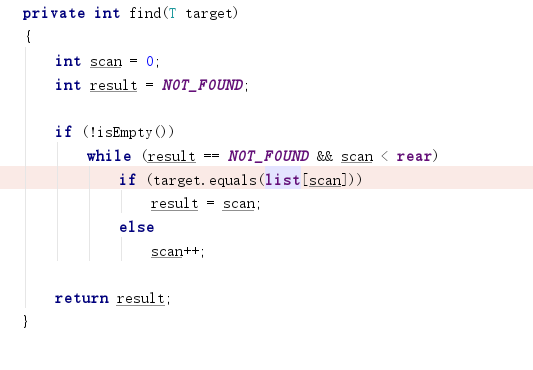
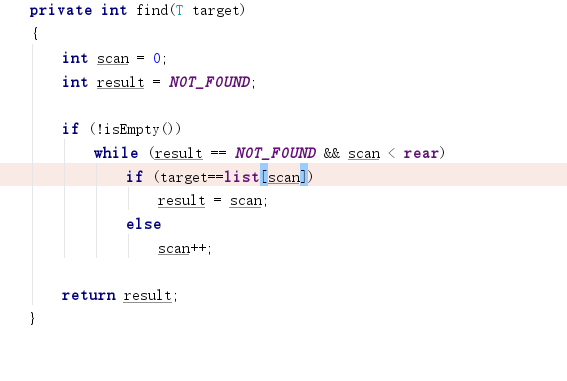
- 问题一解决方法:我仔细阅读了报错给的提示,发现最终是我的ArrayList中的find方法存在毛病,因为所比较的数据类型为T,所以在判断两个元素是否相等的时候不能使用“equals”,更改成“==”问题就得解决掉了。
代码托管

上周考试错题总结
这周没有错题哦~
结对及互评
- 博客中值得学习的或问题:
- 排版精美,对教材的总结细致,善于发现问题,对于问题研究得很细致,解答也很周全。
- 代码中值得学习的或问题:
- 代码写的很规范,思路很清晰,继续加油!
点评过的同学博客和代码
其他(感悟、思考等,可选)
这周的内容相比前面几周所学习的内容来说难了许多,从代码的理解难易程度上就能够感觉的出来,这周也花费了我更多的实践,同时也给自己敲了一个警钟,自己不会和不清楚的只是还有很多,不能再像之前那样佛系学习,要更加的努力才是,希望能在以后的学习生活中继续进步!
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 第一周 | 200/200 | 1/1 | 5/20 | |
| 第二周 | 981/1181 | 1/2 | 15/20 | |
| 第三周 | 1694/2875 | 1/3 | 15/35 | |
| 第四周 | 3129/6004 | 1/4 | 15/50 | |
| 第五周 | 1294/7298 | 1/5 | 15/65 | |
| 第六周 | 1426/8724 | 1/6 | 20/85 |
-
计划学习时间:20小时
-
实际学习时间:20小时