yuanwenlianjie:https://www.cnblogs.com/wt645631686/p/13473186.html
什么是消息延迟?
消息队列在消费过程中大量堆积就是消息延迟,也就是消费的频率跟不上生产。比方说,生产者向队列中一共生产了1000条消息,某一个消费者消费进度是900条,那么这个消费者的消费延迟就是100条消息。
如何监控消息延迟
- 使用消息队列提供的工具,通过监控消息的堆积来完成;
- 通过生成监控消息的方式来监控消息的延迟情况。
kafka的消费延迟及监控
在Kafka0.9之前的版本中,消费进度是存储在ZooKeeper中的,消费者在消费消息的时候,先要从ZooKeeper中获取最新的消费进度,再从这个进度的基础上消费后面的消息。
在Kafka0.9版本之后,消费进度被迁入到Kakfa的一个专门的topic叫“__consumer_offsets”里面。可以依据不同的版本,从不同的位置,获取到这个消费进度的信息。
kafka的两个消息监控工具
1、kafka-consumer-groups.sh”(它在Kafka安装包的bin目录下)
2、JMX
程序的消费延迟检测
可以定义一种特殊的消息,然后启动一个监控程序,将这个消息定时地循环写入到消息队列中,消息的内容可以是生成消息的时间戳,并且也会作为队列的消费者消费数据。业务处理程序消费到这个消息时直接丢弃掉,而监控程序在消费到这个消息时,就可以和这个消息的生成时间做比较,如果时间差达到某一个阈值就可以向我们报警。

当然推荐用工具 和结合程序检测同时使用
减少消息延迟的正确姿势
想要减少消息的处理延迟,需要在消费端和消息队列两个层面来完成。在消费端,我们的目标是提升消费者的消息处理能力,你能做的是:
- 优化消费代码提升性能;
- 增加消费者的数量(这个方式比较简单)。
不过,第二种方式会受限于消息队列的实现。比如说,如果消息队列使用的是Kafka就无法通过增加消费者数量的方式,来提升消息处理能力。
因为在Kafka中,一个Topic(话题)可以配置多个Partition(分区),数据会被平均或者按照生产者指定的方式,写入到多个分区中,那么在消费的时候,Kafka约定一个分区只能被一个消费者消费,为什么要这么设计呢?在我看来,如果有多个consumer(消费者)可以消费一个分区的数据,那么在操作这个消费进度的时候就需要加锁,可能会对性能有一定的影响。
所以说,话题的分区数量决定了消费的并行度,增加多余的消费者也是没有用处的,那么你可以通过增加分区来提高消费者的处理能力。
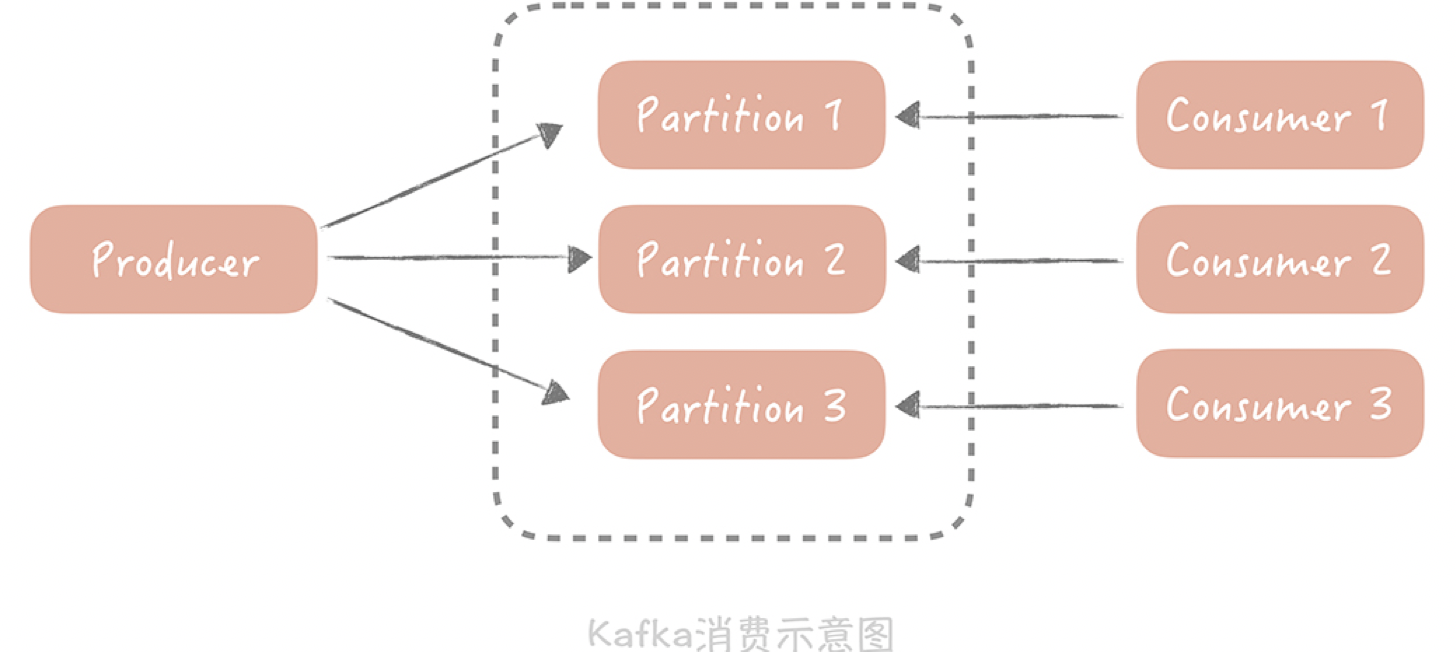
那么,如何在不增加分区的前提下提升消费能力呢?
既然不能增加consumer,那么可以在一个consumer中提升处理消息的并行度,所以可以考虑使用多线程的方式来增加处理能力:可以预先创建一个或者多个线程池,在接收到消息之后,把消息丢到线程池中来异步地处理,这样,原本串行的消费消息的流程就变成了并行的消费,可以提高消息消费的吞吐量,在并行处理的前提下,就可以在一次和消息队列的交互中多拉取几条数据,然后分配给多个线程来处理。
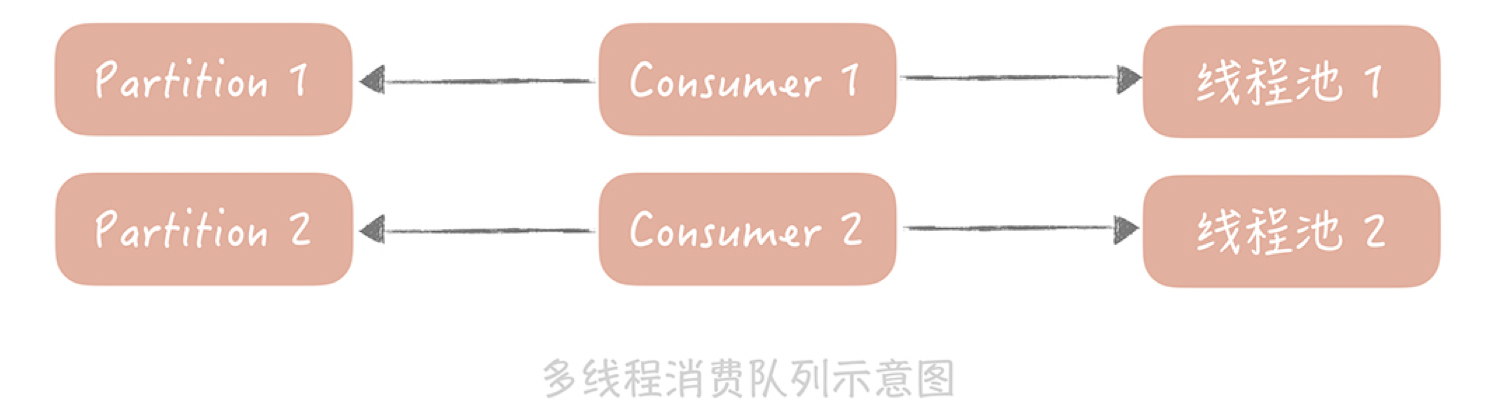
另外,写消费客户端的时候要考虑这种场景,拉取不到消息可以等待一段时间再来拉取,等待的时间不宜过长,否则会增加消息的延迟。一般建议固定的10ms~100ms,也可以按照一定步长递增,比如第一次拉取不到消息等待10ms,第二次20ms,最长可以到100ms,直到拉取到消息再回到10ms。
总结
如何提升消息队列的性能来降低消息消费的延迟,重点是:
- 可以使用消息队列提供的工具,或者通过发送监控消息的方式,来监控消息的延迟情况;
- 横向扩展消费者是提升消费处理能力的重要方式;
- 选择高性能的数据存储方式,可以提升消息的消费性能。