一.Hadoop2.x产生背景
1.Hadoop1.x中的HDFS和MapReduce在高可用、扩展性等方面存在问题。
2.HDFS存在的问题
1.NameNode单点故障,难以应用于在线场景。
2.NameNode压力过大,且内存受限,影响扩展性。
3.MapReduce存在的问题
1.JobTracker访问压力大,影响系统扩展性。
2.难以支持除MapReduce之外的计算框架,比如Spark、Strom等。
二.架构差异

1.Hadoop1.x由HDFS和MapReduce组成,不支持HA.
2.Hadoop2.x由HDFS、MapReduce和YARN三个分支组成,其中HDFS只支持2个节点HA【3.x支持一主多备】,MapReduce运行在YARN之上,YARN负责资源调度。
三.Hadoop2.x新特性
1.解决HDFS1.x中单点故障和内存受限的问题。通过主备NameNode使用HA解决单点故障问题。如果主NameNode发生故障,则切换到备NameNode之上。
2.解决内存受限问题,使用HDFS Federation机制,内存水平扩展,支持多NameNode。每个NameNode分管一部分目录,所有NameNode共享所有DataNode存储资源。
3.主NameNode对外提供服务,备NameNode同步主NameNode元数据,以待切换。
4.所有DataNode同时向两个NameNode汇报数据块信息。
四.切换方式
1.手动切换,通过命令实现主备之间的切换,可以用在HDFS升级等场合。
2.自动切换,基于Zookeeper。Zookeeper Failover Controller【ZKFC】会监控NameNode的健康状态,并向Zookeeper注册NameNode,当NameNode挂掉后,ZKFC为NameNode竞争锁,获得ZKFC锁的NameNode变为active。
五.Federation
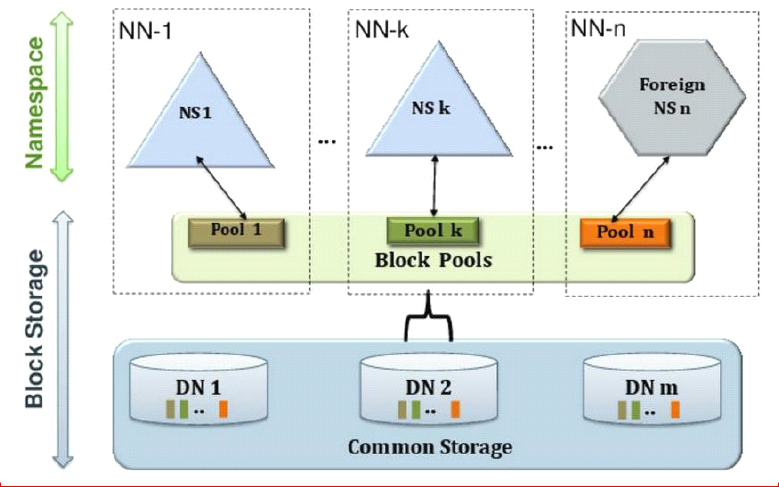
1.通过多个namenode/namespace把元数据的存储和管理分散到多个节点中,使得namenode/namespace可以通过增加机器来进行水平扩展。
2.能把单个namenode的负载分散到多个节点中,在HDFS数据规模较大的时候也不会降低HDFS的性能。可以通过多个namespace来隔离不同类型的应用,把不同类型应用的HDFS元数据的存储和管理分派给不同的namenode。