一.简介
KMeans 算法的基本思想是初始随机给定K个簇中心,按照最邻近原则把分类样本点分到各个簇。然后按平均法重新计算各个簇的质心,从而确定新的簇心。一直迭代,直到簇心的移动距离小于某个给定的值。
二.步骤
1.为待聚类的点寻找聚类中心。
2.计算每个点到聚类中心的距离,将每个点聚类到该点最近的聚类中。
3.计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心。
4.反复执行步骤2,3,直到聚类中心不再进行大范围移动或者聚类迭代次数达到要求为止。
三.演示

四.初始中心点选择
1.随机选择k个点作为中心点。
对应算法:KMeans
2.采用k-means++选择中心点。
基本思想:初始的聚类中心点之间的相互距离要尽可能远。
步骤:
1.从输入的数据点集合中随机选择一个点作为第一个聚类中心点。
2.对于数据点中的每一个点【已选择为中心点的除外】x,计算它与最近聚类中心点的距离D(x)。
3.选择一个新的数据点为聚类的中心点,原则是D(x)较大的点,被选择的概率较大。
4.重复步骤2,3,直到所有的聚类中心点被选择出来。
5.使用这k个初始中心点运行标准的KMeans算法。
五.D(x)映射被选择的概率
1.从输入的数据点集合D中随机选择一个点作为第一个聚类中心点。
2.对于数据点中的每一个点【已选择为中心点的除外】x,计算它与最近聚类中心点的距离Si,对所有Si求和得到sum。
3.取一个随机数,用权重的方式计算下一个中心点。取随机值random(0<random<sum),对点集D循环,做random-=Si运算,直到random<0,那么点i就是下一个中心点。
六.源码分析
1.MLlib的KMeans聚类模型的runs参数可以设置并行计算聚类中心的数量,runs代表同时计算多组聚类中心点,最后去计算结果最好的那一组中心点作为聚类的中心点。
2.KMeans快速查找,计算距离

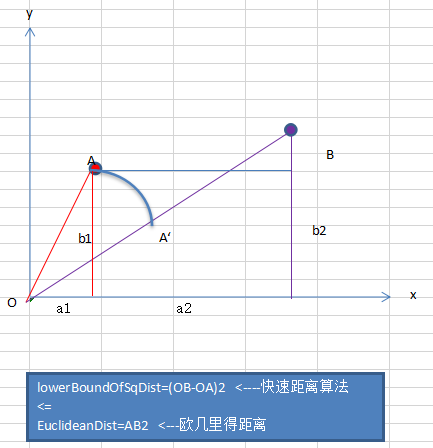
七.代码测试
1.测试数据
0.0 0.0 0.0
0.1 0.1 0.1
0.2 0.2 0.2
9.0 9.0 9.0
9.1 9.1 9.1
9.2 9.2 9.2
4.5 5.6 4.3
2.代码实现
package big.data.analyse.mllib import org.apache.log4j.{Level, Logger} import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.mllib.clustering.{KMeans, KMeansModel} import org.apache.spark.mllib.linalg.Vectors /** * Created by zhen on 2019/4/11. */ object KMeansTest { Logger.getLogger("org").setLevel(Level.WARN) def main(args: Array[String]) { val conf = new SparkConf().setAppName("KMeansExample") conf.setMaster("local[2]") val sc = new SparkContext(conf) // Load and parse the data val data = sc.textFile("data/mllib/kmeans_data.txt") val parsedData = data.map(s => Vectors.dense(s.split(' ').map(_.toDouble))).cache() // split data to train data and test data val weights = Array(0.8, 0.2) val splitParseData = parsedData.randomSplit(weights) // Cluster the data into two classes using KMeans val numClusters = 2 val numIterations = 20 val clusters = KMeans.train(parsedData, numClusters, numIterations) // Evaluate clustering by computing Within Set Sum of Squared Errors val WSSSE = clusters.computeCost(parsedData) println("Within Set Sum of Squared Errors = " + WSSSE) // predict data val result = clusters.predict(parsedData) result.foreach(println(_)) // Save and load model clusters.save(sc, "target/KMeansModel") val sameModel = KMeansModel.load(sc, "target/KMeansModel") sc.stop() } }
3.结果
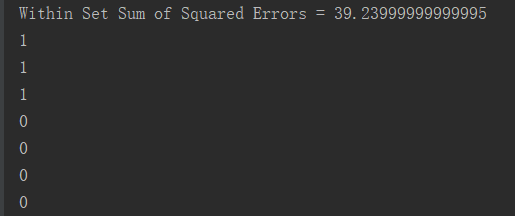
八.总结
聚类作为无监督的机器学习算法,只能根据具体的算法实现对不同数据进行分类,不能具体指出类内不同数据的相似性,以及与其它类内节点的差异性。