2.1进行误差分析
(1)一识别猫为案例,错误率为10%,这时系统还可以有较大提升空间,这时该往哪方面努力呢?可以通过误差分析,具体可以拿出100个分类错误的样本,然后利用表格统计每个样本分类错误的原因(如下图所示),比如很模糊,狗和猫很像,有滤镜等,一个样本出错可以同时有多个原因,统计看因为什么原因导致分类错误的比例最高,那么就应该着重花功夫在那上面。
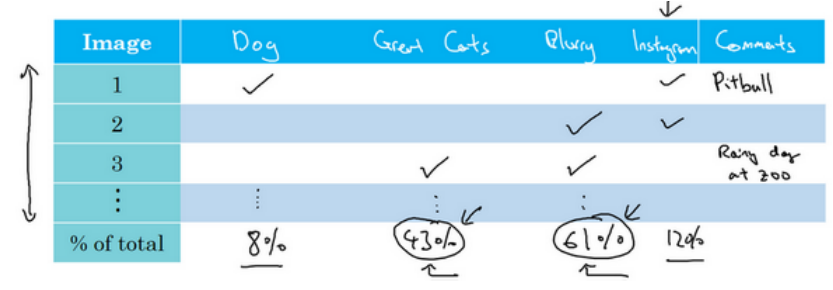
(2)根据上面的统计也可以预估出如果完美解决该问题可以带来多大性能的提升,比如100张样本中有5张图把狗误认为了猫,所以即使解决了狗识别成猫的问题,最终能带来的性能提升是从90%到90.5%。
2.2清楚标记错误的数据
(1)深度学习对于训练集样本(注意此处只讲了是训练集)样本随机标注错误其实表现出很强的健壮性,一般没有必要去修正训练集样本的错误标注(一来没必要,而来训练集可能非常之大耗时耗力)。
(2)对于验证集而言,务必将验证集的操作运用到测试集上,保证二者的同分布。
(3)同样在误差分析的表格中添加一列作为样本标记错误导致的,看看他的占比,比如说修正能提升0.6%,那么如果现在误差是10%的话,显然其他原因可提升性能空间更大,应优先考虑,但是当误差只有2%时,这时就不得不考虑到样本标记错误了,因为它已经成为主要原因了。
(4)在验证集、测试集上看分类错误的样本上的样本标记错误的同时,也应该看判断正确的样本里是否有标记错误,那也是需要修正的,否则如果只修正算法出错的样本,你对算法的偏差故居可能会变大。
2.3快速搭建你的第一个系统,并进行迭代
(1)针对一个你第一次处理的新问题:总之一句话就是尽快确定验证集、测试集和单一指标,即有了目标,然后迅速建立起一个系统,即使很粗糙也没有关系。有了这个系统之后就可以用它做偏差方差分析,做误差分析,进而知道下一步该往哪方面优化了。
(2)如果你已经很有经验了,又或者你面对的问题有非常多的学术文献可以借鉴,比如人脸识别设备,那么可以在大量文献的基础之上,一开始就构建比较复杂的系统。
2.4在不同的划分上进行训练并测试
(1)猫分类案例:20万张照片是网络爬取的高清照,10000张是用户上传的模糊的低像素的照片,以下是两种划分方法:
1.将200 000和10 000张合并在一起,然后205000作为训练集,2500作为开发集,2500作为测试集,这样虽然三者同分布,但是优化的目标(开发集)中其实非常多的都是来自网络的照片,不是真实场景中的,所以最终应用的效果并不会很好。不赞同这种方式。
2.将5000张用户照片放入到200 000张照片中组成训练集,然后2500张来自用户的作为开发集,2500张来自用户的作为开发集,这样的划分效果会更加。
(2)语音激活汽车后视镜案例:500 000段语音以及20 000段与后视镜语音激活相关的语音,分类方法类似上面的第二种,将10 000段与后视镜语音激活相关的放入500 000段中组成训练集,5000段与后视镜语音激活相关的做开发集,剩下5000段作为测试集,这样效果为佳。
2.5不匹配数据划分的偏差与方差
(1)当训练集和开发集/测试集不同分布时会出现数据不匹配,这时开发集误差减去训练集误差得到的不一定是方差了,所以提出在训练集中拿出一部分数据,组成训练-开发集,训练-开发集与训练集同分布,这样训练-开发集的误差减去训练集的误差就是系统方差了。
(2)如下图所示:训练集误差减去人类水平误差得到偏差,训练--开发集误差减去训练集误差得到的是方差,开发集/测试集误差减去训练-开发集误差得到的是数据不匹配带来的误差。
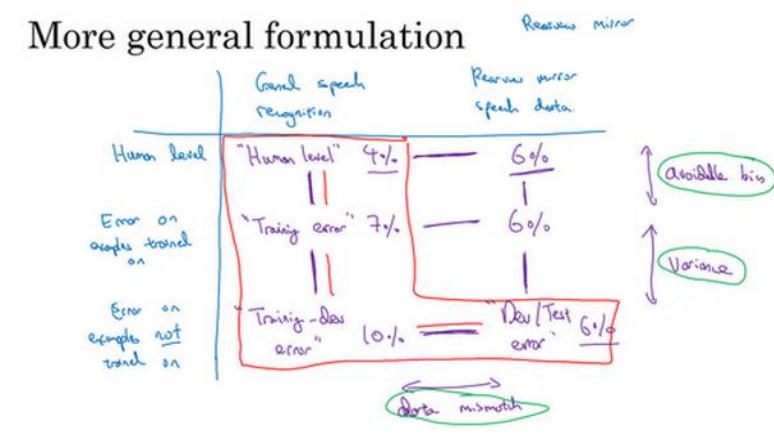
(3)有时会发现开发集/测试集误差比训练-开发集还要小,原因是因为训练时使用了非常难的样本,而在实际中很少出现这么难的样本。
(4)很遗憾的是关于数据不匹配造成的误差并没有什么很系统的方法来解决。
2.6定位数据不匹配
(1)如果发现存在数据不匹配问题,建议做错误分析,或者看看开发集和训练集,试图找出这两个数据集分布到底有什么不同,然后看看有没有办法手机更多看起来像开发集的数据作训练。
(2)案例1:后视镜语音激活。发现在开发集中有很多汽车噪声,而训练集中没有,这就是造成分布不同的一大原因,解决办法就是录很多汽车噪声的声音,然后与安静的训练集进行合成形成更像开发集的训练集。这里需要注意一点是录噪声的时间多应该尽可能的多,比如1000个小时,而不是用相同的1个小时噪声取合成,这样人听起来没什么区别,但是神经网络可能已经对那一小时噪声过拟合了。下图是语音的合成:

(3)汽车目标检测同样如此,在用计算机视觉合成汽车图像作为数据集时,应该合成尽可能多的种类的汽车,而不是就一二十汽车,虽然他们都很逼真,如下图所示:

2.7迁移学习
(1)迁移学习最常用的场景:如果尝试优化任务B的性能,通常这个任务的数据相对较少,例如,在放射科很难收集足够多的X射线扫描图片,所以这种情况下,你可能找一个相关但不同的业务,如图像识别,其中你可能有一百万张图片训练过了,并从中学到很多低层次特征,所以那也许能帮助网络在任务B在放射科任务上做的更好,尽管任务B没有那么多数据。注意也有不起作用的时候,那就是任务A实际上数据量比任务B要少,这种情况下增益可能不多。
(2)迁移学习方法:一般去掉别人网络的最后一层,然后重新按照需求添加最后一层或者几层,这一层或者几层从新赋初值,前面的权重利用别人已经训练好的权重(较做预训练pre-training),然后根据新数据来训练添加的网络的权重(叫做微调fine tuning),如果数据量多的话,可以训练整个网络权重,少的话就训练后天添加的。如下图示意:

2.8多任务学习
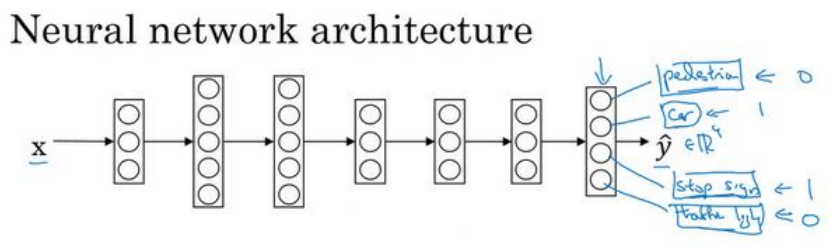
(1)一个网络中学习多个任务,如下图中:是否有人、是否有车、是否有交通灯、是否有停车牌,这就是一个多任务,一个样本中可以有多个标签,这也是与softmax区别的地方,softmax一个样本中只有一个标签。

(2)多样本是Y的输出如下:
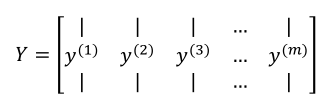
神经网络结构如下:
损失函数如下:
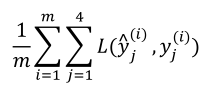

(3)把多个任务放在一个网络中比分成多个网络独立完成一个任务表现出了更好的性能,这就是多任务学习的力量。
(4)以上面的例子为例,有时候不一定每个样本都有四个完整的标签,可以有一个,可能三个,标签如下所示,问号表示没有,这时候忽略问号掉即可,只对有标签的进行求和。
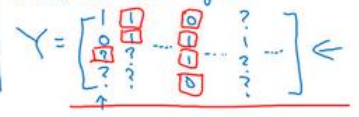
(5)当满足下面情况时,多任务学习才有意义:
1.如果你训练的一组任务,可以共用低层次特征。
2.如果每个任务的数据量接近时(这个不一定绝对)。
3.神经网络足够的大,神经网络不够大时可能出现单独训练效果更好。
(6)迁移学习目前使用频率高于多任务学习,图像目标检测算是多任务学习中一个典型的例子了。
2.9什么是端到端的深度学习
(1)端到端学习简而言之就是以前有一些数据处理系统或学习系统,它需要多个阶段的处理,那么端到端深度学习就是忽略所有这些不同的阶段,用单个神经网络代替。如语音识别为例,输入是音频,输出就是文本,不需要这个中间人工操作。
(2)只有数据非常足的时候端到端深度学习的厉害之处才能表现出来。
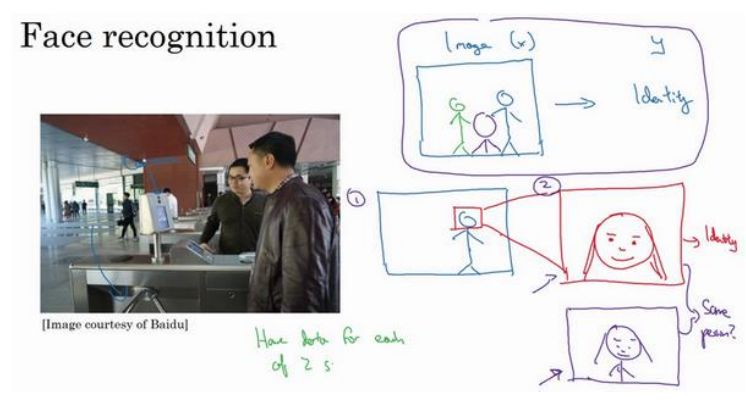
(3)案例1两步走实现人脸识别门禁:第一步是检测图像中人脸的位置裁剪出来,然后进行人脸识别。这样每一步多比较简单,都有相对应足够多的数据。如果直接从图像到人的判断其数据量不足,难度非常大。
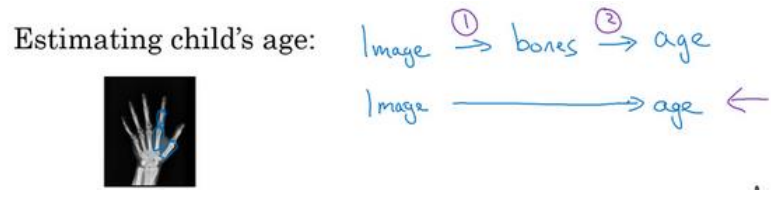
(4)案例2:从小孩的手的X射线图中判断小孩的年龄也是两步骤:第一是分割出图像中的手指,然后测量手指长度再根据手指长度与年龄关系的表判断小孩的年龄。这种更容易实现,如果直接从图像到年龄难度大,数据少。
(5)其他像语音识别,翻译等都可以通过端到端学习。
2.10是否要使用端到端的深度学习
(1)归根到底还是看数据量,如果够的话可以使用端到端,不够的化采用多步方式。
(2)端到端的好处:用数据说话,避免了引入人的成见;所需的手工设计的组件更少,所以也简化了你的设计工作流程。
(3)端到端的缺点:需要特别大的数据量,往往没有那么多;它排除了可能有用的手工设计组件,学习算法有两个主要的知识来源:一个是数据,另一个使人手工设计的任何东西,如组件、功能或者其他东西。