参考链接:http://t.zoukankan.com/dayang12525-p-6229629.html
操作步骤:
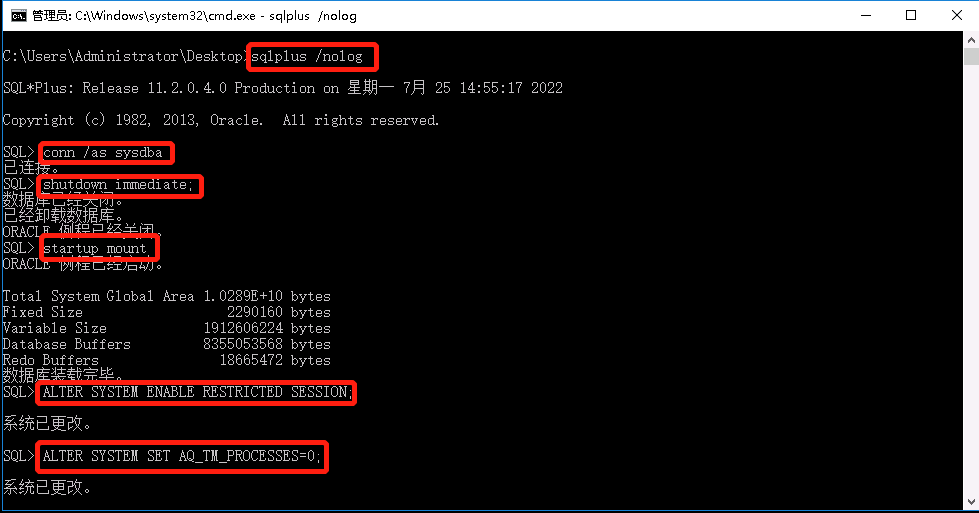
cmd 然后输入 sqlplus /nolog
conn /as sysdba
shutdown immediate;
startuo mount
ALTER SYSTEM ENABLE RESTRICTED SESSION;
ALTER SYSTEM SET JOB_QUEUE_PROCESSES=0;
ALTER SYSTEM SET AQ_TM_PROCESSES=0;
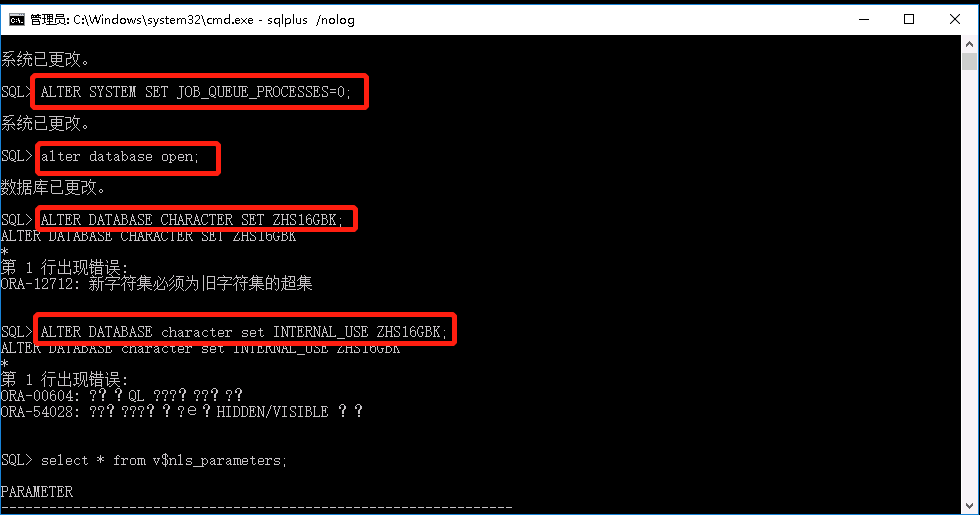
ALTER DATABASE OPEN;
ALTER DATABASE CHARACTER SET INTERNAL_USE ZHS16GBK; //跳过超子集检测
ALTER DATABASE national CHARACTER SET INTERNAL ZHS16GBK;
SHUTDOWN IMMEDIATE;
STARTUP
--查询数据库编码
select * from v$nls_parameters where parameter='NLS_CHARACTERSET';
图片:

注意:修改完之后,发现库中的中文都乱码了,提示ORA-29275部分多字节字符处理
将kettle相关的表又删除了 R_开头的 K_开头的 DI开头的 将之前的这三个又导入还是报错,TB_DIC_DEPARTMENT和
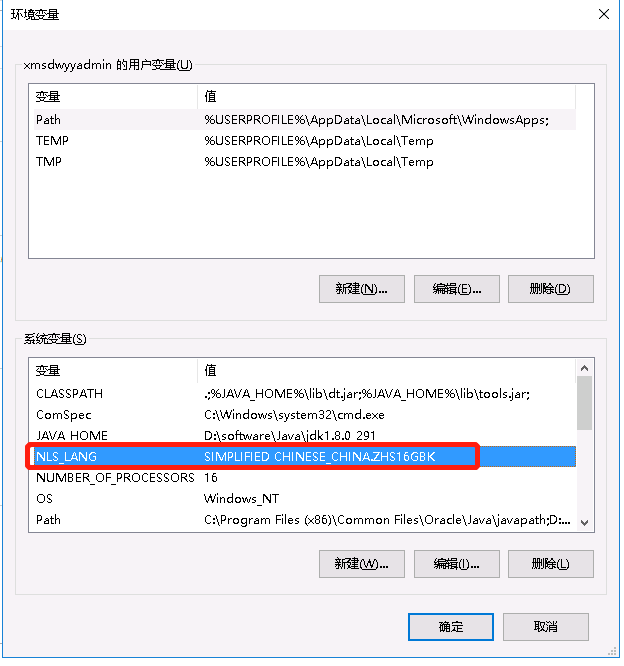
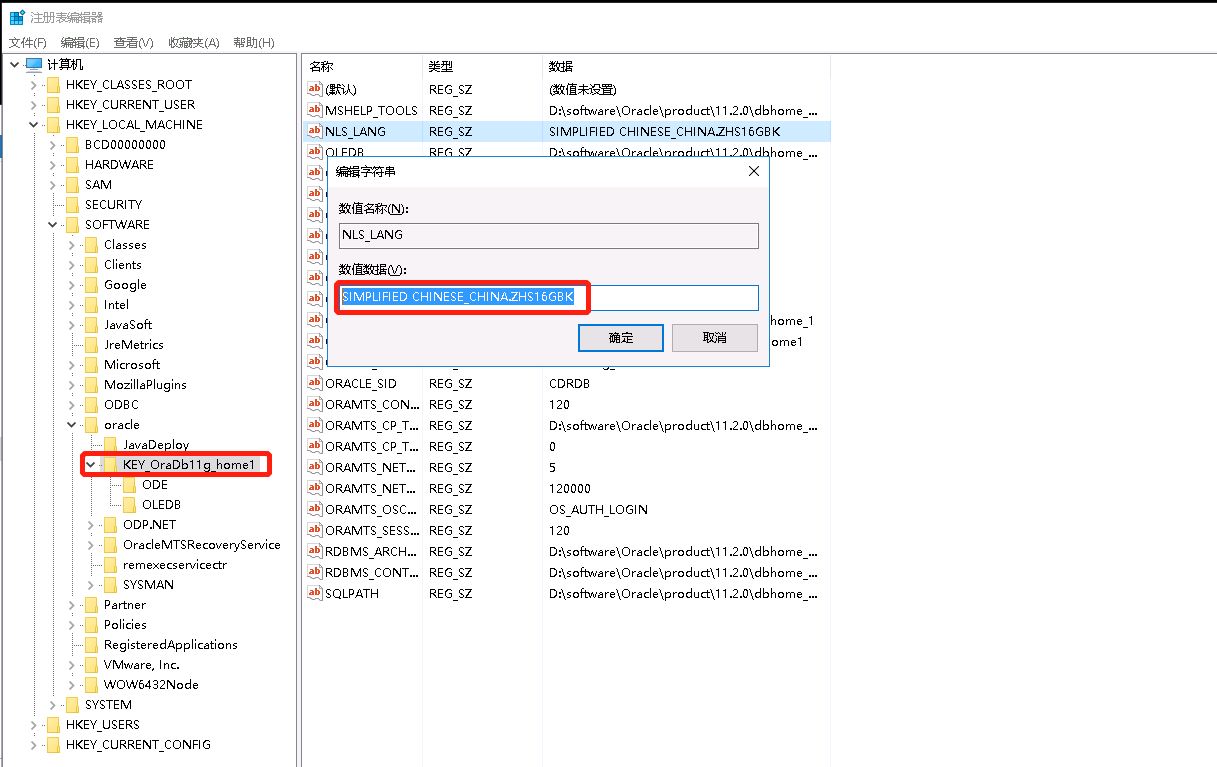
TB_DIC_PRACTITIONER数据清空,还是报错,百度了一下,说要设置系统变量
NLS_LANG SIMPLIFIED CHINESE_CHINA.ZHS16GBK
设置了,还是报错,
最终解决方案:最终将NPPT用户删除,重新按照之前的顺序NPPT.dmp,删除R_开头的,导入KETTLE.dmp,再导入K.dmp和DI.dmp 一共是756个表 之后就不报错了
总结:在导入表之前一定看下源库的数据库编码,导入库的编码需要和源库一样,先设置成一样的,之后再导入dmp文件,这样才对
--查询数据库编码
select * from v$nls_parameters where parameter='NLS_CHARACTERSET';