sql语句练习题:https://blog.csdn.net/byf0521hlyp/article/details/80224840
参考链接:https://cloud.tencent.com/developer/article/1157338
1。 聚合函数不能出现在where条件语句中。
2。 有group by 时,select 中出现的字段中只能有group by 的字段和聚合函数;
3。 在HAVING子句中可以使用聚合函数,但在WHERE子句中不能。
4。insert into插入多条记录时,values后面跟多个括号,一个括号一条记录,括号内不同字段之间用逗号分隔;
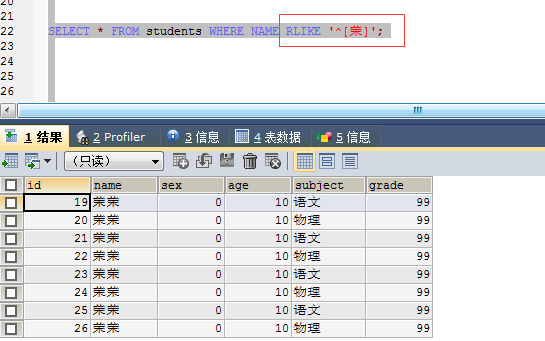
5。通配符: 下划线_:匹配任意一个字符
百分号%:匹配0个或多个字符
中括号[]:匹配中括号中任意一个字符
中括号加尖号[^]:不匹配中括号中小尖后的任意一个字符
其中 []和[^]一般都和 like连用。使用通配符的一般都是模糊查询。
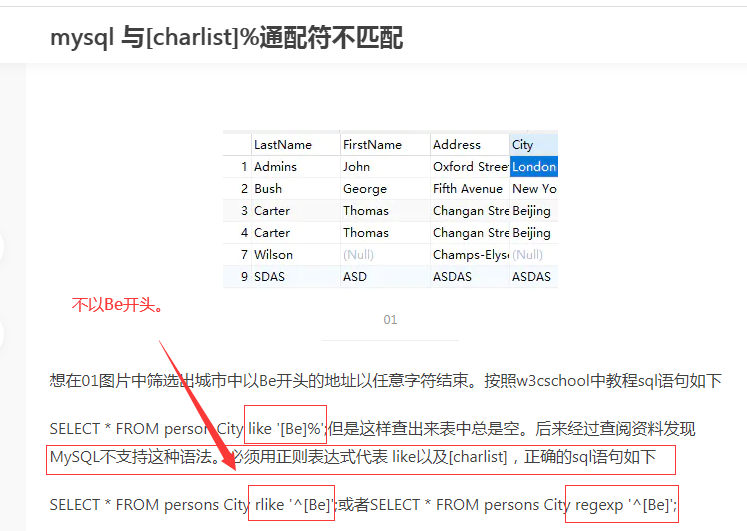
通过实践下面的语句查询不出结果,改成regexp可以。原因是mysql不支持这种写法。

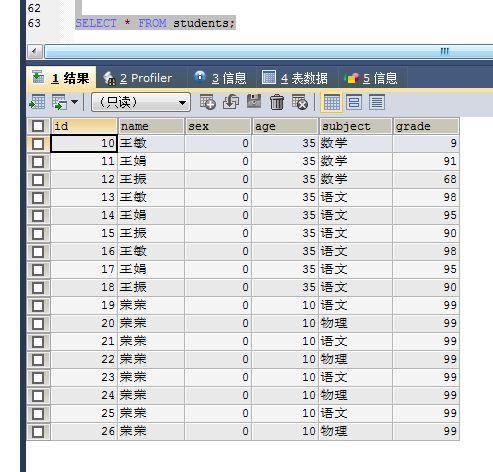


6。常用聚合函数除 COUNT(*) 外,其它函数在计算过程中均忽略NULL值 ,用 count(distinct <列名>) ????
count(*):相当于统计行数,包含NULL ,且不去重。
count(name):不包含NULL,不去重。
count(distinct name) :不包含NULL 且去重。
当count 与 group by 连用时,count是对 group by 结果的各个分组进行计数。 若group by 后面有两个字段,filed A 、filed B ,按A 分成M组,按B 分成N 组,则count出来的就是M*N个组的统计结果.
7。where、group by 、having 的执行顺序, 第一where对from出来的记录进行筛选,然后group by 对where后的结果进行统计,最后having 再对group by后的结果进行筛选。
8。连接查询:若一个查询同时涉及到两张或以上的表,则称为连接查询。包括:内连接、自连接、外连接。
内连接:使用内连接时,如果两个表的相关字段满足条件,则从两个表中提取数据组成新的记录。
FROM 表1 [INNER] JOIN 表2 ON <连接条件>
自连接:
外连接:
a
9。char 和 varchar的区别: 若某列数据类型为varchar(20),存字符串”Jone”时,只占用4个字节,而char(20)会在为填满的空间中填写空格。所以, varchar类型比char类型更节省空间,但它的开销会大一些,处理速度也慢一些。因此,n值比较小(小于4),用char类型更好些
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
例句分析:
1。 查询物理系和数学系每个系的学生人数。 select subject,count(*) from students where subject in ('物理','数学') group by subject;

2。查询名字的第二个字为“小” 或“大” 的学生的详细信息。 select * from studnets where name like '_[小大]%' mysql不支持
3。查询不姓张的学生的详细信息。 select * from students where name not like '张%'
4。查询姓“张”、“李”的学生的详细信息。 select * from students where name like '[李张]%' mysql不支持
5。查询各科目的最高分和最低分。 select subject,max(grade),min(grade) from students group by subject;

6。查询各科成绩的最高分和最低分的人的名字及分数; 先按科目分组将各科的最高分和最低分查询出来,外面包一层,查出各科最高最低分对应的人的姓名,最后结果中去重。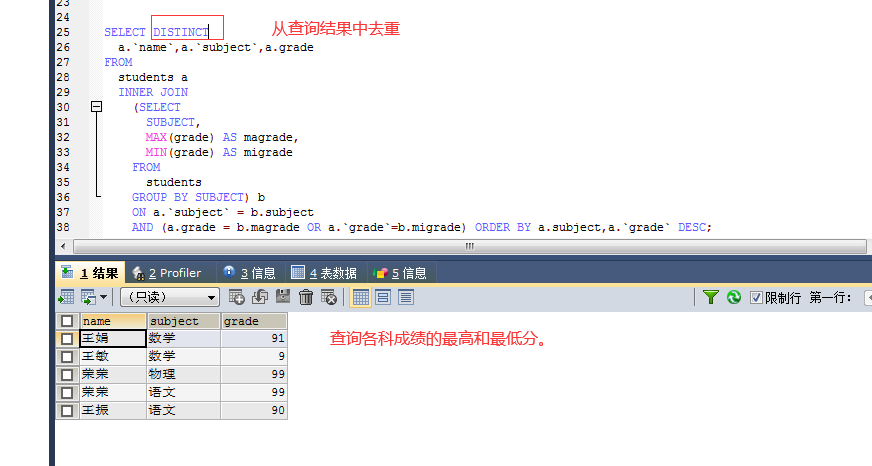
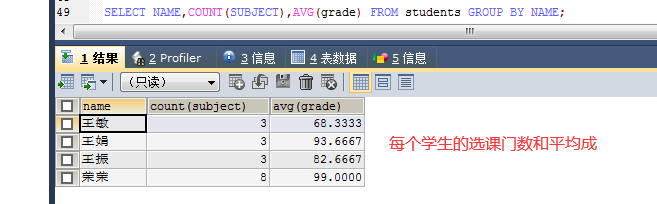
7。获取每个学生的选课门数及平均成绩。
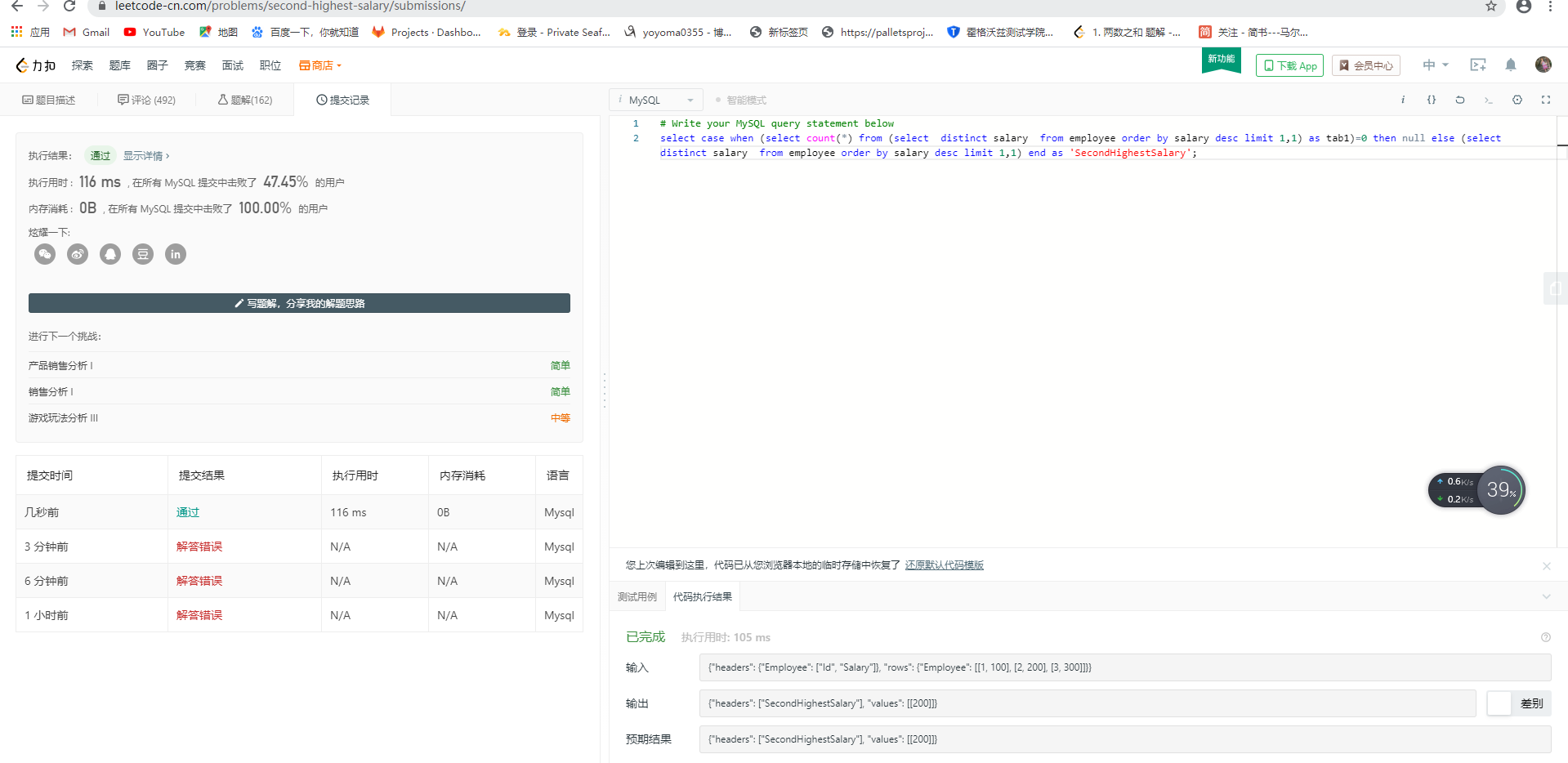
编写一个 SQL 查询,获取 Employee 表中第二高的薪水(Salary) 。
+----+--------+
| Id | Salary |
+----+--------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+----+--------+
例如上述 Employee 表,SQL查询应该返回 200 作为第二高的薪水。如果不存在第二高的薪水,那么查询应返回 null。
+---------------------+
| SecondHighestSalary |
+---------------------+
| 200 |
+---------------------+
解题思路:
1. 如果仅出现两个人并列第一时,也是没有第二高薪水的,此时也是需要返回null,所以需要去重.
2. 第二高,用到limit x,y.

3.如果查询结果无返回值(查询不到数据),可用 case when + count(*) 进行处理
正确答案如下:
SELECT
CASE
WHEN
(SELECT
COUNT(*)
FROM
(SELECT DISTINCT
salary
FROM
employee
ORDER BY salary DESC
LIMIT 1, 1) AS tab1) = 0
THEN NULL
ELSE
(SELECT DISTINCT
salary
FROM
employee
ORDER BY salary DESC
LIMIT 1, 1)
END AS 'SecondHighestSalary' ;
-------------------------------------------------------------------------------------------------------------------------------------------
Employee 表包含所有员工,他们的经理也属于员工。每个员工都有一个 Id,此外还有一列对应员工的经理的 Id。
+----+-------+--------+-----------+ | Id | Name | Salary | ManagerId | +----+-------+--------+-----------+ | 1 | Joe | 70000 | 3 | | 2 | Henry | 80000 | 4 | | 3 | Sam | 60000 | NULL | | 4 | Max | 90000 | NULL | +----+-------+--------+-----------+
给定 Employee 表,编写一个 SQL 查询,该查询可以获取收入超过他们经理的员工的姓名。在上面的表格中,Joe 是唯一一个收入超过他的经理的员工。
+----------+ | Employee | +----------+ | Joe | +----------+
select a.name as employee from employee as a inner join employee as b on a.managerid=b.id and a.salary > b.salary
----------------------------------------------------------------------------------------------------------------------------------
编写一个 SQL 查询,查找 Person 表中所有重复的电子邮箱。
示例:
+----+---------+ | Id | Email | +----+---------+ | 1 | a@b.com | | 2 | c@d.com | | 3 | a@b.com | +----+---------+
根据以上输入,你的查询应返回以下结果:
+---------+ | Email | +---------+ | a@b.com | +---------+
给定一个 salary 表,如下所示,有 m = 男性 和 f = 女性 的值。交换所有的 f 和 m 值(例如,将所有 f 值更改为 m,反之亦然)。要求只使用一个更新(Update)语句,并且没有中间的临时表。
注意,您必只能写一个 Update 语句,请不要编写任何 Select 语句。
例如:
| id | name | sex | salary | |----|------|-----|--------| | 1 | A | m | 2500 | | 2 | B | f | 1500 | | 3 | C | m | 5500 | | 4 | D | f | 500 |
运行你所编写的更新语句之后,将会得到以下表:
| id | name | sex | salary | |----|------|-----|--------| | 1 | A | f | 2500 | | 2 | B | m | 1500 | | 3 | C | f | 5500 | | 4 | D | m | 500 |
解题思路: update和case when合用.
给定一个 Weather 表,编写一个 SQL 查询,来查找与之前(昨天的)日期相比温度更高的所有日期的 Id。
+---------+------------------+------------------+ | Id(INT) | RecordDate(DATE) | Temperature(INT) | +---------+------------------+------------------+ | 1 | 2015-01-01 | 10 | | 2 | 2015-01-02 | 25 | | 3 | 2015-01-03 | 20 | | 4 | 2015-01-04 | 30 | +---------+------------------+------------------+
例如,根据上述给定的 Weather 表格,返回如下 Id:
+----+ | Id | +----+ | 2 | | 4 | +----+
部门表 Department:
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | revenue | int | | month | varchar | +---------------+---------+ (id, month) 是表的联合主键。 这个表格有关于每个部门每月收入的信息。 月份(month)可以取下列值 ["Jan","Feb","Mar","Apr","May","Jun","Jul","Aug","Sep","Oct","Nov","Dec"]。
编写一个 SQL 查询来重新格式化表,使得新的表中有一个部门 id 列和一些对应 每个月 的收入(revenue)列。
查询结果格式如下面的示例所示:
Department 表: +------+---------+-------+ | id | revenue | month | +------+---------+-------+ | 1 | 8000 | Jan | | 2 | 9000 | Jan | | 3 | 10000 | Feb | | 1 | 7000 | Feb | | 1 | 6000 | Mar | +------+---------+-------+ 查询得到的结果表: +------+-------------+-------------+-------------+-----+-------------+ | id | Jan_Revenue | Feb_Revenue | Mar_Revenue | ... | Dec_Revenue | +------+-------------+-------------+-------------+-----+-------------+ | 1 | 8000 | 7000 | 6000 | ... | null | | 2 | 9000 | null | null | ... | null | | 3 | null | 10000 | null | ... | null | +------+-------------+-------------+-------------+-----+-------------+ 注意,结果表有 13 列 (1个部门 id 列 + 12个月份的收入列)。
CREATE TABLE department (
id INT (10) NOT NULL,
revenue INT (10) NOT NULL,
MONTH VARCHAR (10) NOT NULL,
PRIMARY KEY (id,MONTH)
) ;
#插入数据
INSERT INTO department (id, revenue, MONTH)
VALUES
(1, 8000, 'Jan'),
(2, 9000, 'Jan'),
(3, 10000, 'Feb'),
(1, 7000, 'Feb'),
(1, 6000, 'Mar') ;
#查询
SELECT id,
SUM(CASE `month` WHEN 'Jan' THEN revenue END) Jan_Revenue,
SUM(CASE `month` WHEN 'Feb' THEN revenue END) Feb_Revenue,
SUM(CASE `month` WHEN 'Mar' THEN revenue END) Mar_Revenue,
SUM(CASE `month` WHEN 'Apr' THEN revenue END) Apr_Revenue,
SUM(CASE `month` WHEN 'May' THEN revenue END) May_Revenue,
SUM(CASE `month` WHEN 'Jun' THEN revenue END) Jun_Revenue,
SUM(CASE `month` WHEN 'Jul' THEN revenue END) Jul_Revenue,
SUM(CASE `month` WHEN 'Aug' THEN revenue END) Aug_Revenue,
SUM(CASE `month` WHEN 'Sep' THEN revenue END) Sep_Revenue,
SUM(CASE `month` WHEN 'Oct' THEN revenue END) Oct_Revenue,
SUM(CASE `month` WHEN 'Nov' THEN revenue END) Nov_Revenue,
SUM(CASE `month` WHEN 'Dec' THEN revenue END) Dec_Revenue
FROM Department
GROUP BY id;
总结:以后自己 写的长的SQL 语句,多思考一下如何简化. 以下是自己写的将返回的0改为null
SELECT
id,
SUM(Jan_revenue) AS 'Jan_Revenue',
SUM(Feb_revenue) AS 'Feb_revenue',
SUM(Mar_revenue) AS 'Mar_revenue',
SUM(Apr_revenue) AS 'Apr_revenue',
SUM(May_revenue) AS 'May_revenue',
SUM(Jun_revenue) AS 'Jun_revenue',
SUM(Jul_revenue) AS 'Jul_revenue',
SUM(Aug_revenue) AS 'Aug_revenue',
SUM(Sep_revenue) AS 'Sep_revenue',
SUM(Oct_revenue) AS 'Oct_revenue',
SUM(Nov_revenue) AS 'Nov_revenue',
SUM(Dec_revenue) AS 'Dec_revenue'
FROM
(SELECT
id,
CASE MONTH
WHEN'Jan'
THEN revenue
END AS 'Jan_Revenue',
CASE MONTH
WHEN 'Feb'
THEN revenue
END AS 'Feb_Revenue',
CASE MONTH
WHEN 'Mar'
THEN revenue
END AS 'Mar_Revenue',
CASE MONTH
WHEN 'Apr'
THEN revenue
END AS 'Apr_Revenue',
CASE MONTH
WHEN 'May'
THEN revenue
END AS 'May_Revenue',
CASE MONTH
WHEN 'Jun'
THEN revenue
END AS 'Jun_Revenue',
CASE MONTH
WHEN 'Jul'
THEN revenue
END AS 'Jul_Revenue',
CASE MONTH
WHEN 'Aug'
THEN revenue
END AS 'Aug_Revenue',
CASE MONTH
WHEN 'Sep'
THEN revenue
END AS 'Sep_Revenue',
CASE MONTH
WHEN 'Oct'
THEN revenue
END AS 'Oct_Revenue',
CASE MONTH
WHEN 'Nov'
THEN revenue
END AS 'Nov_Revenue',
CASE MONTH
WHEN 'Dec'
THEN revenue
END AS 'Dec_Revenue'
FROM
department) AS t1
GROUP BY id ;
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
某城市开了一家新的电影院,吸引了很多人过来看电影。该电影院特别注意用户体验,专门有个 LED显示板做电影推荐,上面公布着影评和相关电影描述。
作为该电影院的信息部主管,您需要编写一个 SQL查询,找出所有影片描述为非 boring (不无聊) 的并且 id 为奇数 的影片,结果请按等级 rating 排列。
例如,下表 cinema:
+---------+-----------+--------------+-----------+ | id | movie | description | rating | +---------+-----------+--------------+-----------+ | 1 | War | great 3D | 8.9 | | 2 | Science | fiction | 8.5 | | 3 | irish | boring | 6.2 | | 4 | Ice song | Fantacy | 8.6 | | 5 | House card| Interesting| 9.1 | +---------+-----------+--------------+-----------+
对于上面的例子,则正确的输出是为:
+---------+-----------+--------------+-----------+ | id | movie | description | rating | +---------+-----------+--------------+-----------+ | 5 | House card| Interesting| 9.1 | | 1 | War | great 3D | 8.9 | +---------+-----------+--------------+-----------+
#建表
CREATE TABLE cinema (
id INT (10) NOT NULL AUTO_INCREMENT,
movie VARCHAR (10) NOT NULL,
description VARCHAR (30) NOT NULL,
rating FLOAT NOT NULL,
PRIMARY KEY (id));
#插入
INSERT INTO cinema (movie, description, rating)
VALUES
('war', 'great 3D', 8.9),
('science', 'fiction 3D', 8.5),
('irish', 'boring 3D', 6.2),
('ice song', 'fantacy 3D', 8.6),
('house card', 'interesting', 9.1) ;
#查询
SELECT
*
FROM
cinema
WHERE description NOT LIKE '%boring%' AND MOD(id,2) = 1
ORDER BY rating DESC ;
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
某网站包含两个表,Customers 表和 Orders 表。编写一个 SQL 查询,找出所有从不订购任何东西的客户。
Customers 表:
+----+-------+ | Id | Name | +----+-------+ | 1 | Joe | | 2 | Henry | | 3 | Sam | | 4 | Max | +----+-------+
Orders 表:
+----+------------+ | Id | CustomerId | +----+------------+ | 1 | 3 | | 2 | 1 | +----+------------+
例如给定上述表格,你的查询应返回:
+-----------+ | Customers | +-----------+ | Henry | | Max | +-----------+
#建表
CREATE TABLE customers (
id INT (10) NOT NULL AUTO_INCREMENT,
NAME VARCHAR (20) NOT NULL,
PRIMARY KEY (id)
) ;
CREATE TABLE orders (
id INT (10) NOT NULL AUTO_INCREMENT,
customerid INT(10) NOT NULL,
PRIMARY KEY (id),
FOREIGN KEY (customerid) REFERENCES customers(id)
) ;
#插入数据
INSERT INTO customers (NAME) VALUES ('Joe'),('Henry'),('Sam'),('Max');
INSERT INTO orders (customerid) VALUES (3),(1);
#查询语句
SELECT
NAME AS Customers
FROM
customers
WHERE id NOT IN
(SELECT
a.id
FROM
customers a
INNER JOIN orders b
ON a.id = b.`customerid`);
下面是官方给的. 精典. 感觉自己写那么多废话.5555555555555.
select customers.name as 'Customers'
from customers
where customers.id not in
(
select customerid from orders
);
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------
表1: Person
+-------------+---------+ | 列名 | 类型 | +-------------+---------+ | PersonId | int | | FirstName | varchar | | LastName | varchar | +-------------+---------+ PersonId 是上表主键
表2: Address
+-------------+---------+ | 列名 | 类型 | +-------------+---------+ | AddressId | int | | PersonId | int | | City | varchar | | State | varchar | +-------------+---------+ AddressId 是上表主键
编写一个 SQL 查询,满足条件:无论 person 是否有地址信息,都需要基于上述两表提供 person 的以下信息:
FirstName, LastName, City, State
#建表
create table person
(personid int(10) not null auto_increment,
firstname varchar(30) not null,
lastname varchar(30) not null,
primary key(personid));
create table address
(addressid int(10) not null auto_increment,
personid int(10) not null,
city varchar(30) not null,
state varchar(30) not null,
primary key (addressid));
#插入数据
insert into person (firstname,lastname) values('wang','min'),('li','yuerong'),('li','fengyan');
insert into address (personid,city,state) values(1,'changzhi','1'),(2,'yangquan','0');
#查询
select firstname,lastname,city,state from person a left join address b on a.personid = b.`personid`;
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
有一个courses 表 ,有: student (学生) 和 class (课程)。
请列出所有超过或等于5名学生的课。
例如,表:
+---------+------------+ | student | class | +---------+------------+ | A | Math | | B | English | | C | Math | | D | Biology | | E | Math | | F | Computer | | G | Math | | H | Math | | I | Math | +---------+------------+
应该输出:
+---------+ | class | +---------+ | Math | +---------+
Note:
学生在每个课中不应被重复计算。
解答:
#建表
CREATE TABLE courses (student VARCHAR(5) NOT NULL,class VARCHAR(10) NOT NULL);
#插入数据
INSERT INTO courses (student,class) VALUES
('A','Math'),
('B','English'),
('C','Math'),
('D','Biology'),
('E','Math'),
('F','Computer'),
('G','Math'),
('H','Math'),
('I','Math');
#查询
SELECT class FROM courses GROUP BY class HAVING COUNT(distinct student)>=5;
select class,count(distinct student) from courses group by class;
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
编写一个 SQL 查询来实现分数排名。如果两个分数相同,则两个分数排名(Rank)相同。请注意,平分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”。
+----+-------+ | Id | Score | +----+-------+ | 1 | 3.50 | | 2 | 3.65 | | 3 | 4.00 | | 4 | 3.85 | | 5 | 4.00 | | 6 | 3.65 | +----+-------+
例如,根据上述给定的 Scores 表,你的查询应该返回(按分数从高到低排列):
+-------+------+ | Score | Rank | +-------+------+ | 4.00 | 1 | | 4.00 | 1 | | 3.85 | 2 | | 3.65 | 3 | | 3.65 | 3 | | 3.50 | 4 | +-------+------+
编写一个 SQL 查询,获取 Employee 表中第 n 高的薪水(Salary)。
+----+--------+
| Id | Salary |
+----+--------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+----+--------+
例如上述 Employee 表,n = 2 时,应返回第二高的薪水 200。如果不存在第 n 高的薪水,那么查询应返回 null。
+------------------------+
| getNthHighestSalary(2) |
+------------------------+
| 200 |
+------------------------+
select
if(cnt < N, null, min) as getNthHighestSalary
from
(select
min(salary) as min,
count(1) as cnt
from
(select distinct
salary
from
Employee
order by salary desc
limit N) as a) as b;
小美是一所中学的信息科技老师,她有一张 seat 座位表,平时用来储存学生名字和与他们相对应的座位 id。
其中纵列的 id 是连续递增的
小美想改变相邻俩学生的座位。
你能不能帮她写一个 SQL query 来输出小美想要的结果呢?
示例:
+---------+---------+ | id | student | +---------+---------+ | 1 | Abbot | | 2 | Doris | | 3 | Emerson | | 4 | Green | | 5 | Jeames | +---------+---------+
假如数据输入的是上表,则输出结果如下:
+---------+---------+ | id | student | +---------+---------+ | 1 | Doris | | 2 | Abbot | | 3 | Green | | 4 | Emerson | | 5 | Jeames | +---------+---------+
注意:
如果学生人数是奇数,则不需要改变最后一个同学的座位。
#建表
CREATE TABLE seat (id INT(10) NOT NULL AUTO_INCREMENT,student VARCHAR(20) NOT NULL,PRIMARY KEY(id));
#插入
INSERT INTO seat (student) VALUES ("Abbot"),("Doris"),("Emerson"),("Green"),("Jeames");
#换座位 思路: ID为偶数时,变成本身减1, 如果为奇数时,变成本身加1, 但当ID为奇数且为最后一个(= count)时,就还是本身..
SELECT IF(id%2=0,id-1,IF(id=cnt,id,id+1)) AS id,student FROM (SELECT COUNT(*) AS cnt FROM seat)AS a,seat ORDER BY id;
SELECT IF(id%2=0,id-1,id(id=cnt,id,id+1)) AS id,student FROM (SELECT COUNT(*) AS cnt FROM seat) AS a,seat;
SELECT id,student,cnt FROM (SELECT COUNT(*) AS cnt FROM seat) AS a,seat ORDER BY id DESC;
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
部门工资最高的员工:
Employee 表包含所有员工信息,每个员工有其对应的 Id, salary 和 department Id。
+----+-------+--------+--------------+ | Id | Name | Salary | DepartmentId | +----+-------+--------+--------------+ | 1 | Joe | 70000 | 1 | | 2 | Henry | 80000 | 2 | | 3 | Sam | 60000 | 2 | | 4 | Max | 90000 | 1 | +----+-------+--------+--------------+
Department 表包含公司所有部门的信息。
+----+----------+ | Id | Name | +----+----------+ | 1 | IT | | 2 | Sales | +----+----------+
编写一个 SQL 查询,找出每个部门工资最高的员工。例如,根据上述给定的表格,Max 在 IT 部门有最高工资,Henry 在 Sales 部门有最高工资。
+------------+----------+--------+ | Department | Employee | Salary | +------------+----------+--------+ | IT | Max | 90000 | | Sales | Henry | 80000 | +------------+----------+--------+
#建表
CREATE TABLE Employee1 (id INT(10) NOT NULL AUTO_INCREMENT,NAME VARCHAR(10) NOT NULL,salary INT(10) NOT NULL,departmentid INT(10) NOT NULL,PRIMARY KEY(id));
CREATE TABLE Department (id INT(10) NOT NULL AUTO_INCREMENT,NAME VARCHAR(10) NOT NULL,PRIMARY KEY(id));
#插入
INSERT INTO Employee1 (NAME,salary,departmentid) VALUES ("Joe",70000,1),("Henry",80000,2),("Sam",60000,2),("Max",90000,1);
INSERT INTO Department (NAME) VALUES("IT"),("Sales");
#部门最高工资
SELECT
b.departmentname AS department,
a.name AS employee,
a.`salary`
FROM
Employee1 AS a
INNER JOIN
(SELECT
MAX(c.salary) AS salary,
c.departmentid,
d.`name` AS departmentname
FROM
Employee1 AS c INNER JOIN Department AS d ON c.`departmentid`=d.`id`
GROUP BY c.departmentid) AS b
ON a.`salary` = b.salary
AND a.`departmentid` = b.departmentid ORDER BY a.`salary` DESC ;
SELECT
Department.name AS 'Department',
Employee.name AS 'Employee',
Salary
FROM
Employee
JOIN
Department ON Employee.DepartmentId = Department.Id
WHERE
(Employee.DepartmentId , Salary) IN
( SELECT
DepartmentId, MAX(Salary)
FROM
Employee
GROUP BY DepartmentId
)
官方答案思路清晰,且条件是两个字段in一个子查询输出的两个字段. 即, where a,b in (select c,d from table); 这样的格式头一次见到,学习了.
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Trips 表中存所有出租车的行程信息。每段行程有唯一键 Id,Client_Id 和 Driver_Id 是 Users 表中 Users_Id 的外键。Status 是枚举类型,枚举成员为 (‘completed’, ‘cancelled_by_driver’, ‘cancelled_by_client’)。
+----+-----------+-----------+---------+--------------------+----------+ | Id | Client_Id | Driver_Id | City_Id | Status |Request_at| +----+-----------+-----------+---------+--------------------+----------+ | 1 | 1 | 10 | 1 | completed |2013-10-01| | 2 | 2 | 11 | 1 | cancelled_by_driver|2013-10-01| | 3 | 3 | 12 | 6 | completed |2013-10-01| | 4 | 4 | 13 | 6 | cancelled_by_client|2013-10-01| | 5 | 1 | 10 | 1 | completed |2013-10-02| | 6 | 2 | 11 | 6 | completed |2013-10-02| | 7 | 3 | 12 | 6 | completed |2013-10-02| | 8 | 2 | 12 | 12 | completed |2013-10-03| | 9 | 3 | 10 | 12 | completed |2013-10-03| | 10 | 4 | 13 | 12 | cancelled_by_driver|2013-10-03| +----+-----------+-----------+---------+--------------------+----------+
Users 表存所有用户。每个用户有唯一键 Users_Id。Banned 表示这个用户是否被禁止,Role 则是一个表示(‘client’, ‘driver’, ‘partner’)的枚举类型。
+----------+--------+--------+ | Users_Id | Banned | Role | +----------+--------+--------+ | 1 | No | client | | 2 | Yes | client | | 3 | No | client | | 4 | No | client | | 10 | No | driver | | 11 | No | driver | | 12 | No | driver | | 13 | No | driver | +----------+--------+--------+
写一段 SQL 语句查出 2013年10月1日 至 2013年10月3日 期间非禁止用户的取消率。基于上表,你的 SQL 语句应返回如下结果,取消率(Cancellation Rate)保留两位小数。
取消率的计算方式如下:(被司机或乘客取消的非禁止用户生成的订单数量) / (非禁止用户生成的订单总数)
+------------+-------------------+ | Day | Cancellation Rate | +------------+-------------------+ | 2013-10-01 | 0.33 | | 2013-10-02 | 0.00 | | 2013-10-03 | 0.50 | +------------+-------------------+
#建表
CREATE TABLE Trips1 (
id INT (10) NOT NULL AUTO_INCREMENT,
client_id INT (10) NOT NULL,
driver_id INT (10) NOT NULL,
city_id INT (10) NOT NULL,
STATUS VARCHAR (30) NOT NULL,
request_at DATETIME DEFAULT NULL,
PRIMARY KEY(id),
FOREIGN KEY(client_id) REFERENCES Users(users_id),
FOREIGN KEY(driver_id) REFERENCES Users(users_id));
CREATE TABLE Users (
users_id INT (10) NOT NULL AUTO_INCREMENT,
banned VARCHAR (10) NOT NULL,
role VARCHAR (10) NOT NULL,
PRIMARY KEY (users_id)
) ;
#插入
INSERT INTO Trips (client_id,driver_id,city_id,STATUS,request_at) VALUES
(1,10,1,"completed","2013-10-01"),
(2,11,1,"cancelled_by_driver","2013-10-01"),
(3,12,6,"completed","2013-10-01"),
(4,13,6,"cancelled_by_client","2013-10-01"),
(1,10,1,"completed","2013-10-02"),
(2,11,6,"completed","2013-10-02"),
(3,12,6,"completed","2013-10-02"),
(2,12,12,"completed","2013-10-03"),
(3,10,12,"completed","2013-10-03"),
(4,13,12,"cancelled_by_driver","2013-10-03");
INSERT INTO Users (users_id,banned,role) VALUES
(1,"No","client"),
(2,"Yes","client"),
(3,"No","client"),
(4,"No","client"),
(10,"No","driver"),
(11,"No","driver"),
(12,"No","driver"),
(13,"No","driver")
;
#行程和用户
SELECT DATE(T.request_at) AS 'Day',
ROUND(SUM(IF(T.status ='completed',0,1))/COUNT(T.status),2) AS 'Cancellation Rate'
FROM Trips AS T
INNER JOIN Users AS U1 ON (T.client_id = U1.users_id AND U1.banned ='No')
INNER JOIN Users AS U2 ON (T.driver_id = U2.users_id AND U2.banned ='No')
WHERE T.request_at BETWEEN '2013-10-01' AND '2013-10-03'
GROUP BY T.request_at;
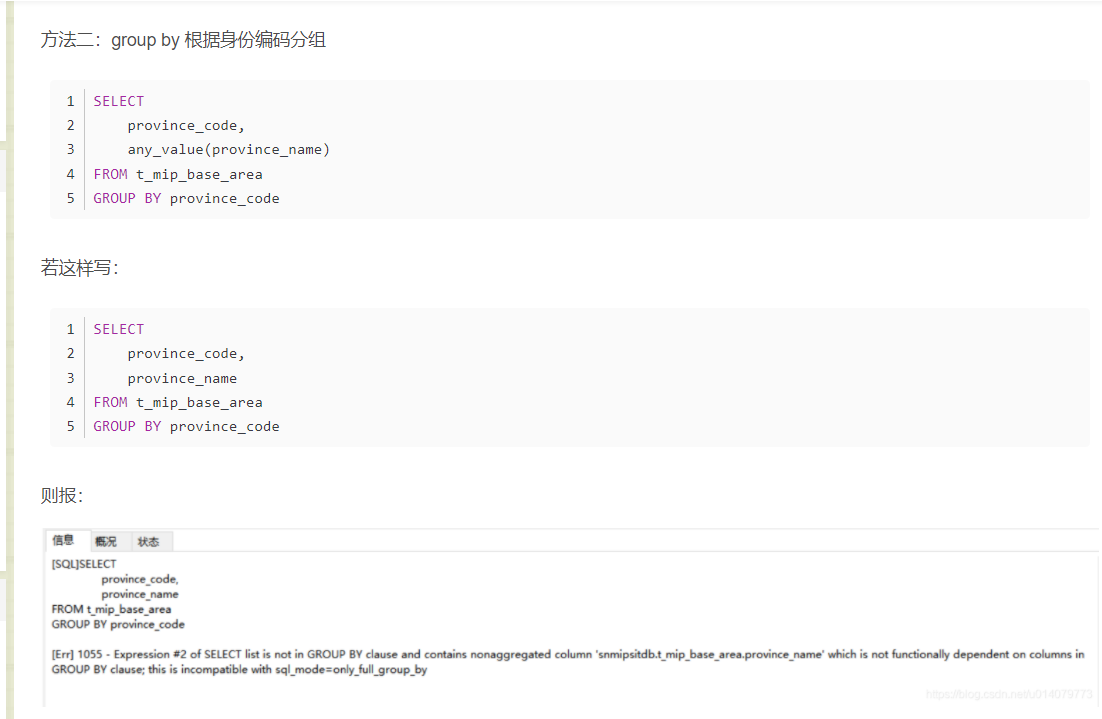
认识any_value()
#mysql中select后面跟的字段,必须在group by中出现,但有一个函数,可以将group by 中没有出现的字段,在select后面带出来,
这个函数就是any_value()
用法如下:
总结:
1.MySQL5.7之后,sql_mode中ONLY_FULL_GROUP_BY模式默认设置为打开状态。
2.ONLY_FULL_GROUP_BY的语义就是确定select target list中的所有列的值都是明确语义,简单的说来,在此模式下,target list中的值要么是来自于聚合函数(sum、avg、max等)的结果,要么是来自于group by list中的表达式的值
3.MySQL提供了any_value()函数来抑制ONLY_FULL_GROUP_BY值被拒绝
4.any_value()会选择被分到同一组的数据里第一条数据的指定列值作为返回数据