前言
APScheduler 有四种组件,分别是:调度器(scheduler),作业存储(job store),触发器(trigger),执行器(executor)。
job stores 存储
job stores 支持四种任务存储方式
- memory:默认配置任务存在内存中
- mongdb:支持文档数据库存储
- sqlalchemy:支持关系数据库存储
- redis:支持键值对数据库存储
默认是存储在内存中,也就是重启服务后,就无法查看到之前添加的任务了。我们希望任务能保存到数据库,让任务一直都在,可以使用sqlalchemy保存到mysql数据库。
mysql 数据库持久化配置
# mysql 数据库持久化配置
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
SQLALCHEMY_DATABASE_URI = "mysql+mysqlconnector://root:123456@127.0.0.1:3306/web"
# 存储位置
SCHEDULER_JOBSTORES = {
'default': SQLAlchemyJobStore(url=SQLALCHEMY_DATABASE_URI)
}
MongoDB 数据库持久化配置
# MongoDB 数据库持久化配置
from apscheduler.jobstores.mongodb import MongoDBJobStore
SCHEDULER_JOBSTORES = {
'default': MongoDBJobStore(host='mongoserver', port=27017)
}
redis 持久化配置
from apscheduler.jobstores.redis import RedisJobStore
REDIS = {
'host': '127.0.0.1',
'port': '6379',
'db': 0,
'password': '****'
}
SCHEDULER_JOBSTORES = {
'default': RedisJobStore(**REDIS)
}
使用示例
from flask import Flask
from flask_apscheduler import APScheduler
import time
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
class Config(object):
SCHEDULER_TIMEZONE = 'Asia/Shanghai' # 配置时区
SCHEDULER_API_ENABLED = True # 调度器开关
# 配置mysql
SQLALCHEMY_DATABASE_URI = 'mysql+mysqlconnector://root:123456@127.0.0.1:3306/web'
# job存储位置
SCHEDULER_JOBSTORES = {
'default': SQLAlchemyJobStore(url=SQLALCHEMY_DATABASE_URI)
}
# 线程池配置
SCHEDULER_EXECUTORS = {
'default': {'type': 'threadpool', 'max_workers': 10}
}
scheduler = APScheduler()
def task1(x):
print(f'task 1 executed --------: {x}', time.time())
def task2(x):
print(f'task 2 executed --------: {x}', time.time())
if __name__ == '__main__':
app = Flask(__name__)
app.config.from_object(Config())
scheduler.init_app(app)
# add_job() 添加任务
scheduler.add_job(func=task1, args=('循环',), trigger='interval', seconds=5, replace_existing=True, id='interval_task')
scheduler.add_job(func=task2, args=('定时任务',), trigger='cron', second='*/10', replace_existing=True, id='cron_task')
scheduler.start()
app.run(use_reloader=False)
运行后数据库会生成一张表apscheduler_jobs
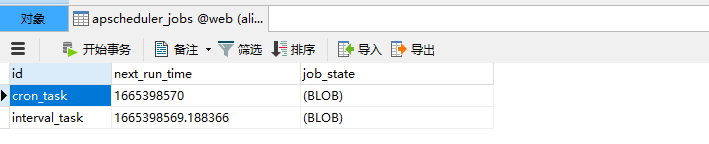
可以查看任务名称和下一次执行时间
启动和暂停任务
暂停任务:根据任务id名称,调用pause_job 可以暂停任务
scheduler.pause_job(task_id)
重新启动任务
scheduler.resume_job(task_id)
删除任务
scheduler.remove_job(task_id)
查看任务
all_jobs = scheduler.get_jobs()
# 查看指定的job信息
job_info = scheduler.get_job(task_id)