在centos7下搭建hadoop环境
确保在hosts文件中已配置红框中文字,bogon是我的系统用户名,跟在@后面的

1.首先安装好jdk,我是直接yum安装的,此处划重点!!一定要安装devel版本!!!!你可以看到它有这么多坑爹的东西==

yum -y install java-1.8.0-openjdk-devel.x86_64
安装好之后有下面这些东西

然后配置环境变量,yum安装的jdk路径基本是/usr/lib/jvm下面,具体版本可酌情修改
vi /etc/profile
在里面加入下面文字
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-0.b14.el7_4.x86_64 export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$JAVA_HOME/bin:$PATH
使配置生效
source /etc/profile
然后验证一下,这两个命令出来是同样东西就说明jdk安装配置完成啦~~~~^^
java -version $JAVA_HOME/bin/java -version
2.用root用户创建一个hadoop用户,
useradd hadoop
3.上官网下载hadoop包,hadoop-2.8.3.tar.gz,我下载的是这个,这个要配套jdk1.8
用secureCRT登录系统,hadoop用户,用这个软件的sftp功能将hadoop-2.8.3.tar.gz put到/home/hadoop下

解压
tar -zxf hadoop-2.8.3.tar.gz
此处可查看hadoop版本了,在/home/hadoop/hadoop-2.8.3 下运行下面指令
./bin/hadoop version
然后配置 环境变量,这是个用户级别的环境变量,/etc/profile是全用户的,这个环境变量在每次进入这个用户时都会被加载一次
vim ~/.bashrc
加入以下代码,注意,HADOOP_HOME可酌情更改为自己的路径
export JAVA_HOME=$JAVA_HOME export HADOOP_HOME=/home/hadoop/hadoop-2.8.3 export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
使配置生效
source ~/.bashrc
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml
core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/tmp/dfs/data</value>
</property>
</configuration>
执行 NameNode 的格式化:
./bin/hdfs namenode -format
开启 NaneNode 和 DataNode 守护进程:
./sbin/start-dfs.sh
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode”和SecondaryNameNode
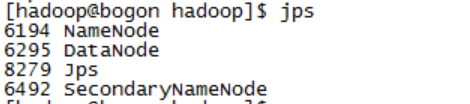
也可以通过http://localhost:50070来查看
注意!!!!
很多人按照网上的各类教程搭建hadoop,但经常在安装好了后,启动hadoop时出现各类的错误,本文就“Error:JAVA_HOME is not set and could not be found ”这一错误提出解决办法。
针对这个错误,其实是hadoop里面hadoop-env.sh文件里面的java路径设置不对,hadoop-env.sh在hadoop-2.8.3/etc/hadoop目录下,具体的修改办法如下:
sudo vim hadoop/etc/hadoop/hdoop-env.sh
将语句 export JAVA_HOME=$JAVA_HOME
修改为 export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-0.b14.el7_4.x86_64
保存后退出。
再次输入start-dfs.sh启动hadoop,则没有报错。
好了环境搭建完成,
接下来
不知道序号多少. 运行Hadoop伪分布式实例
伪分布式读取的则是 HDFS 上的数据。要使用 HDFS,首先需要在 HDFS 中创建用户目录(不是本地目录,不用ls去看了哈),本人尝试换后面的目录,发现后面创建input时出错,所以就使用/user/hadoop
./bin/hdfs dfs -mkdir -p /user/hadoop
在上面的用户目录下创建input,因为我使用的是hadoop用户登录系统,所以这里的input默认创建在/user/hadoop下,然后把./etc/hadoop/下的xml文件复制到input里。
./bin/hdfs dfs -mkdir input ./bin/hdfs dfs -put ./etc/hadoop/*.xml input
复制完成后,可以通过如下命令查看 HDFS 中的文件列表:
./bin/hdfs dfs -ls input
运行 MapReduce 作业
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
查看运行结果的命令
./bin/hdfs dfs -cat output/*
将运行结果取回到本地
./bin/hdfs dfs -get output ./output
关闭hadoop
./sbin/stop-dfs.sh
完成!!!!
此处感谢网上找到的一个教程:http://www.powerxing.com/install-hadoop-in-centos/
另外,还有一个坑爹的,用vi或者vim命令修改文件之后,如果用了:X(大写的X),之后会让你输两次密码,这是要加密文件的意思!!!!!!
加密之后文件就显示乱码了,连带我的secureCRT也显示乱码了TT
不要慌,直接用vi再次打开文件(这里输入的也显示乱码,但是是可以打开的),会让你输入密码,输入刚才加密时的密码,就可以打开了,然后直接打:set key =
然后回车,然后:wq保存,就行了。退出secureCRT,重新登录,又是美好的界面~~~~~~~