什么是闭包?———>是一个函数,一个可以访问其他函数内部数据的函数。
栗子一:
function foo() { var a = 1; } function fn() { console.log(a);//报错,因为这里是无法访问到a的 }
function foo() { var a = 1; function fn() { console.log(a);//这样是可以访问到a的 } return fn;//fn就是闭包,其在foo内部调用没有意义,所以将其返回,交由外部来决定调用时机,更具开发意义,当执行外部函数时,才会创建闭包fn }
一、闭包基本结构:
1.定义外层函数;
2.定义内部函数;
3.内层函数引用外层函数定义的数据;
4.要将内层函数作为外层函数的返回值;
function outer() { var data = {name: "xiaoming”};//外层函数的内部数据会一直缓存在内存中 function inner() { return data; } return inner; } var closure1 = outer();//拿到闭包之后就可以决定什么时候执行它; console.log(closure1()); var closure2 = outer(); console.log(closure2 == closure1);//false,由于调用了两次outer函数,从而创建了两个data对象,因此两个闭包访问到的数据(data)在内存中的地址是不同的; var d1 = closure1(); Var d2 = closure1(); Console.log(d1 == d2);//true
一个闭包是共享一个数据的,两个闭包则是两个数据,所以不必创建两个闭包(即执行两次外部函数);
闭包实际应用: 点击每个li打印出每个li对应的数字
<ul>
<li>0</li>
<li>1</li>
<li>2</li>
<li>3</li>
<li>4</li>
</ul>
<script>
var lists = document.getElementsByTagName("li");
var i = 0,
l = lists.length;
for (; i<l; i++) {
lists[i].onclick = function() {//给每个li绑定了点击事件
console.log(i);//结果都打印5,因为当点击li的时候,i已经变成了5
}
}
</script>
运用闭包来解决问题:
var lists = document.getElementsByTagName("li"); var i = 0, l = lists.length; for (; i<l; i++) { lists[i].onclick = (function(i) {//2.接收参数到外层函数内部,并作为内部数据缓存在内存中 function fn() { console.log(i);//3.这里的i为外层函数的内部数据,分别为0,1,2,3,4 } return fn;//4.返回到外部作为点击事件的处理函数,当发生点击事件时,触发这个闭包的执行,那时打印出来的i为外层函数缓存的i值 })(i);//1.自执行函数,将全局变量i依次传入外层函数中 }
iife(立即执行函数表达式):
(Function(){})();
!function(){}();
+function(){}();
二、闭包的作用
1.避免全局污染
var $ = function() {};//定义的事全局变量$ //但如果在这之前引入了一个jquery.js,那么jquery的$函数就会被这个全局变量$覆盖
在日常开发中,这种事情会很常见,因为你不能保证其他开发人员会定义怎样的变量,这时一个页面先引入了的js文件中的变量就有可能被后面的js文件中定义的同名的全局变量覆盖;
另外,全局变量生命周期是随着页面的存在而存在的,页面在,变量就会一直占用内存,耗费性能,所以不推荐过多的使用全局变量;
function outer() {//外层函数中的$和attr其实就相当于全局变量,只要闭包存在,这些变量就会一直在 var $ = function() {}; var attr = 10; return {//这里面的$和attr不会被任何其他的全局变量污染 $ : $, getAttr : function() { return attr; } } } var query = outer(); query.$(“divs”); console.log(query.getAttr);
以上栗子中将$和attr变量放在一个外层函数里面作为内部数据,而将闭包(指$和getAttr两个方法)返回并赋值给一个全局变量query,当全局变量较多时就能够极大的降低全局污染的概率。
2.缓存数据
1)可用全局变量做缓存———>生命周期太长耗费性能
2)可用cookielocalStorage等做缓存——>io流没有在内存中访问速度快
3)用闭包来做缓存
举个栗子:求fibonancci数列第n项值
function fib(n) { if (n < 1) { throw new Error("value not increct"); } if (n == 1 || n == 2) { return 1; } else { return fib(n - 1) + fib(n - 2); } }
递归方式求Fib(6)值的过程图解:
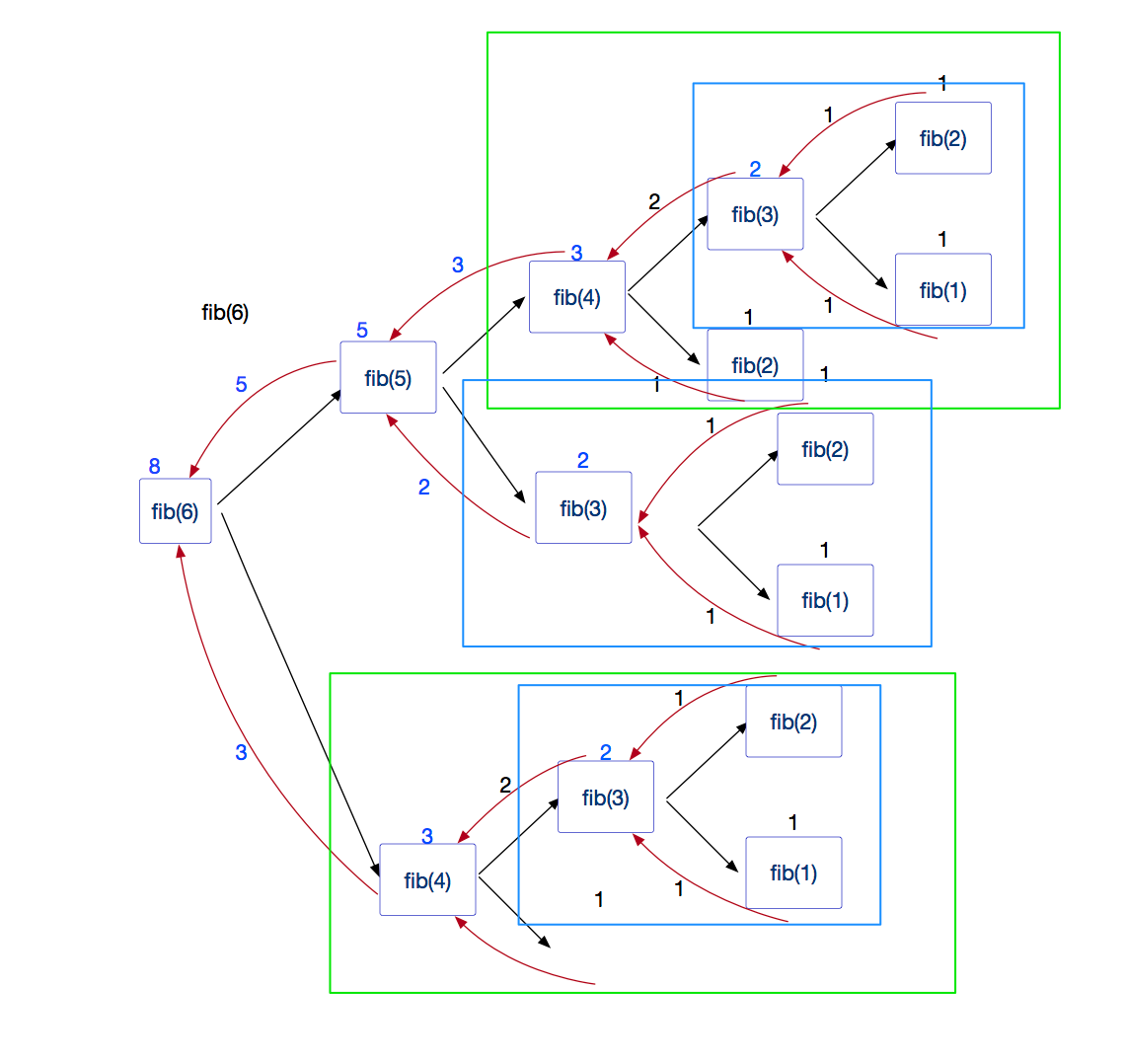
这里面有太多的重复计算,当要求的数值很大时,性能就会特别低;
用闭包来进行优化:
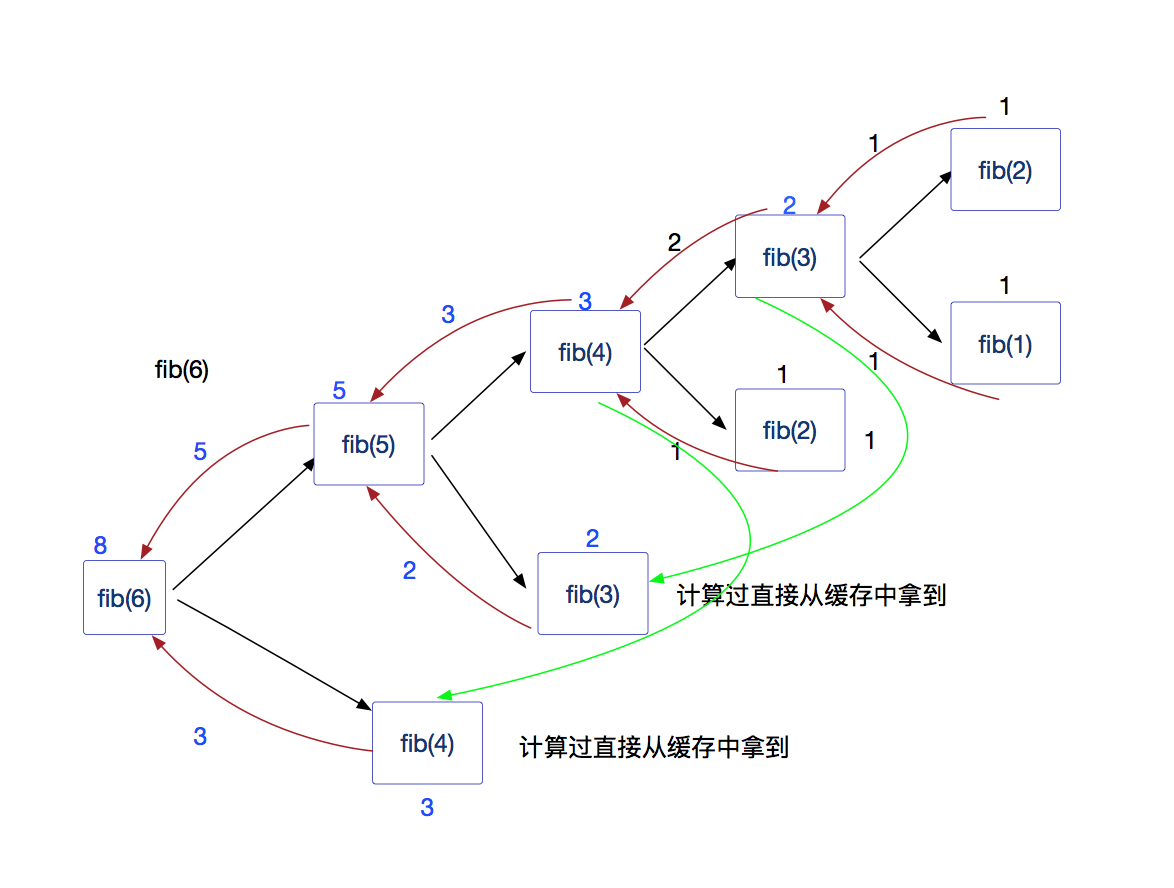
function createFib() { var cache = [, 1, 1];//存储计算结果,计算过的结果得以缓存在内存中以便下次直接使用 return function(n) {//闭包这个函数的作用是求得地n项的值,闭包函数可拿到缓存中已经计算过结果的那些项的值; var res = cache[n];//如果缓存中有这一项,那么直接用 if (!res) {//若没有这一项的值,就要重新计算 res = cache[n] = fib(n - 1) + fib(n - 2);//第n项的值为他的前两项值的和,依旧用递归,这里不同的是,计算过的值不用再重新计算,而是直接拿缓存中的结果,另外本次计算完成后,也要将结果存储到cache中以便下次使用,并且将值赋给res变量用来返回; } return res; }; } var fib = createFib();//需要递归的是fib这个闭包而不是外层函数createFib,因为闭包才是真正的执行求第n项值的功能函数,而外层函数的作用是用内部数据来做缓存; console.log(fib(50));//大大提高计算效率
闭包的方式计算fib(6)值的过程如下:
3、高阶函数
满足以下条件之一就是高阶函数
- 函数类型作为参数(比如es5中forEach, map,filter,回调函数)
- 返回函数(闭包)
举个栗子:求员工工资(底薪+提成),普通员工底薪1000,提成每个人都不一样,经理底薪2000,提成每个经理都不同;
function calSalary(base, ext) { var base = base * 10 + 20;//每次计算都要重复 return base + ext; } var s1 = calSalary(1000, 100); var s2 = calSalary(1000, 200); : : var p1 = calSalary(2000, 100); var p2 = calSalary(2000, 300);
像这种有基数的计算,可以用闭包来进行优化:
function calSalary(base) { var base = base * 10 + 20;//一次计算后作为缓存 return function(ext) { return base + ext;//这里直接拿缓存中的base,省去了很多重复计算 } } var s = calSalary(1000);//拿到闭包 var s1 = s(500);//每次只执行闭包 var s2 = s(1000); var p = calSalary(2000);//创建另一个闭包,因为共享数据不同 var p1 = p(500);//同样每次只执行闭包 var p2 = p(500);
4、回调函数传参:
栗子:给定时器的回调函数传参,实现div1秒后背景变成红色;
setTimeout((function(color){//立即执行函数,接收color参数,缓存在内存中 var div = document.getElementById("div"); return function() {//返回一个函数作为延时回调函数,1秒后执行 div.style.background = color; } })('red'), 1000)
扩展:
- setInterval和setTimeout第三个参数可向函数中传参:setTimeout(function(){}, 200, 10);
- bind方法可实现向回调函数传参
-
setTimeout(function(color){ var div = document.getElementById("div”); div.style.background = color; }.bind(null, 'red'), 1000)