记录下和kafka相关的生产者和消费者,文中很多理解参考文末博文、书籍还有某前辈。
生产者
包含原理和代码两部分。
原理相关
如果要写生产者代码,需要先了解其发送的大致过程,即消息经历了什么才存储到对应topic的对应分区,大致如下。
(1)执行生产者代码后,会在JVM中启动一个producer,它会将数据发送到指定的topic。
(2)message不会直接就发送出去,会首先封装成ProducerRecord,构造ProducerRecord实例对象时,可以传入topic、key、value等。当需要指定消息发送到哪个分区,就需要传入key。value里是消息内容,一般是json格式。
(3)消息还需要序列化,因为涉及到数据的磁盘落地,然后又重新从磁盘读取数据,因此需要使用序列化(生产者)和反序列化(消费者)。
(4)序列化后的数据,还会经过分区器,这里可以指定自定义分区器,如果不指定就是默认分区器。分区器决定数据将存在topic哪个分区,那如何知道这个topic有几个分区?知道了又如何确定哪个分区就是leader分区,就算知道leader分区,又如何判断属于哪个broker呢?这一切都需要通过获取broker上的元数据来得到答案。
在0.8版本,这些元数据是存在zookeeper中的,这样设计是有弊端的,zookeeper本来不是为高并发设计的,如果大量访问涌入zookeeper获取元数据,可能会出问题。在0.10.x之后,这些原数据通过存在某个broker的controller,将从zookeeper获取的元数据都分发到各个broker一份,因此从其中一个broker获取到的数据就是元数据,这样各个broker分摊了zookeeper的压力,将以前从zookeeper获取元数据,分到多个broker去提供了。
(5)接下来数据还不会直接发送出去,会先存入到一个默认是32M大小的内存缓冲区。
(6)缓冲区的数据,会先填入一个又一个的batch,默认一个batch是16K,这个也是可以设置batch.size修改的,需要根据实际情况来配置。batch大小达到指定大小就会发送出去,如果大小没达到16K,还有一个时间限定,可以通过linger.ms来设置,当达到指定的时间不管batch有没有达到指定大小都会发送出去。
producer会有一个专门的sender线程,将满足条件的batch一起发送过去,这样可以将多条消息批量的发送,比一条条的发送更加的节省资源,不用频繁的创建和销毁连接,在0.8版本,是没有batch这个东西的,来一条就发送一条(有改进的空间,仿造批量发送可以提高性能,来自某前辈的经验)。
(7)消息通过sender发送给leader分区,需要经过三层网络架构,然后先写入到broker的os cache里,然后再落地到本地磁盘,落地到磁盘是采用顺序写的方式,一般不会直接写入到磁盘,这样会影响性能(datanode写入数据是直接写入到磁盘的,如果也先写入到os cache,会提高整体性能)。

代码相关
有了上面的原理,生产者的代码部分相对就好理解了,涉及到性能的优化,也会在代码中实现,具体参考代码注释。
package com.boe.producer;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
/**
* 定义一个生产者,将消息发送出去
*/
public class MyProducer {
public static void main(String[] args) throws InterruptedException, ExecutionException {
//step1 配置参数,这些跟优化kafka性能有关系
Properties props=new Properties();
//1 连接broker
props.put("bootstrap.servers","hadoop01:9092,hadoop02:9092,hadoop03:9092");
//2 key和value序列化
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//3 acks
// -1 代表所有处于isr列表中的follower partition都会同步写入消息成功
// 0 代表消息只要发送出去就行,其他不管
// 1 代表发送消息到leader partition写入成功就可以
props.put("acks","-1");
//4 重试次数
props.put("retries",3);//大部分问题,设置这个就可以解决,生产环境可以设置多些 5-10次
// 5 隔多久重试一次
props.put("retry.backoff.ms",2000);
//6 如果要提升kafka的吞吐量,可以指定压缩类型,如lz4
props.put("compression.type","none");
//7 缓冲区大小,默认是32M
props.put("buffer.size",33554432);
//8 一个批次batch的大小,默认是16k,需要根据一条消息的大小去调整
props.put("batch.size",323840);//设置为32k
//9 如果一个batch没满,达到如下的时间也会发送出去
props.put("linger.ms",200);
//10 一条消息最大的大小,默认是1M,生产环境中一般会修改变大,否则会报错
props.put("max.request.size",1048576);
//11 一条消息发送出去后,多久还没收到响应,就认为是超时
props.put("request.timeout.ms",5000);
//step2 创建生产者对象
KafkaProducer<String,String> producer=new KafkaProducer<String, String>(props);
//step3 使用消息的封装形式,注意value一般是json格式
ProducerRecord<String,String> record=new ProducerRecord<String,String>("topicA","{'name':'clyang','age':'34','salary':'8848'}");
//ProducerRecord<String,String> record=new ProducerRecord<String,String>("topicA","I am sorry");
//step4 调用生产者对象的send方法发送消息,有异步和同步两种选择
//1 异步发送,一般使用异步,发送后会执行一个回调函数
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
//判断是否有异常
if(exception==null){
System.out.println("消息发送到分区"+metadata.partition()+"成功");
}else{
System.out.println("消息发送失败");
//TODO 可以写入到redis,或mysql
}
}
});
Thread.sleep(10*1000);
//2 同步发送,需要等待一条消息发送完成,才能发送下一条消息
//RecordMetadata recordMetadata = producer.send(record).get();
//System.out.println("发送到的分区是:"+recordMetadata.partition());
//step5 关闭连接
producer.close();
}
}
执行后,控制台显示发送消息成功,并打印出发送到了哪个分区。

消费者
包含原理和代码两部分。
原理相关
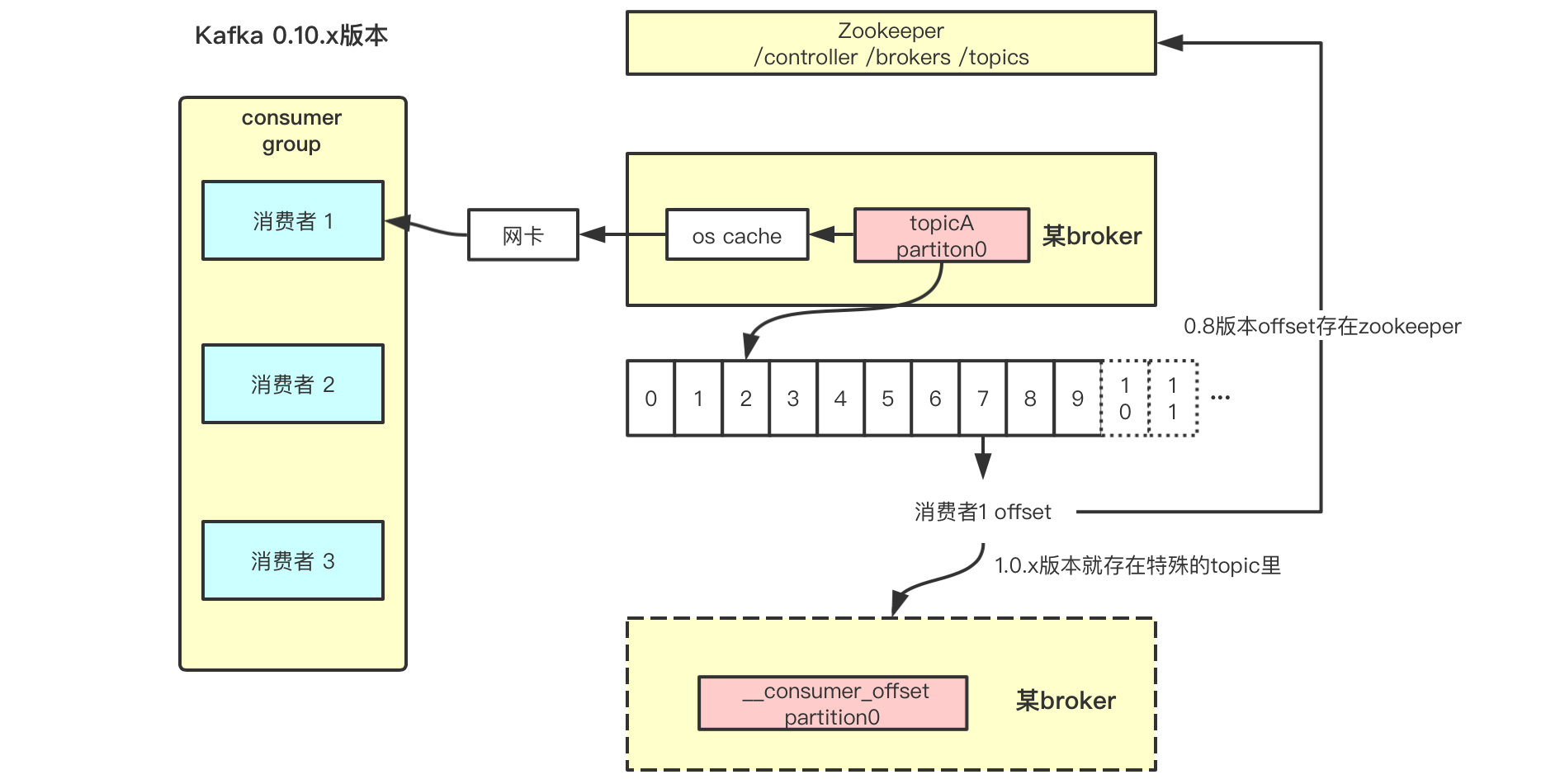
消费者消费数据,需要反序列化数据,且采用了零拷贝的技术,由于消费者和broker都在同一个操作系统下,一般都是linux,不涉及到linux到windows这种跨平台的数据读取,因此数据反序列化后读取到了os cache,然后发送到网关就直接被消费者消费,如下图。如果数据反序列化到os cache(理解为数据的内核态),再拷贝一次到用户态(这个状态的数据可以跨系统平台)再消费,在同一平台下这会是一次多余的拷贝,kafka中省略了这个动作,这大大提高了消费者读取数据的速度。
消费者消费某个leader分区的数据,会从消费者offset的下一个位置开始消费,如图所示上一次消费到了offset 7的位置,下一次消费就从offset 8的位置开始消费。在zookeeper 0.8版本前,消费者的offset都保存在zookeeper中的,后面考虑到多个消费者要和zookeeper通信获取offset会增加zookeeper的压力,从1.0.x开始,这些消费者的offset改保存到了__consumer_offset这个主题里,而它分布在多个broker,将压力就分摊了。
注意消费者能消费到的数据offset,需要小于这个分区的HW(高水印值),比如下图这个分区的HW是9,则offset 10开始的数据就不可以消费,后面将整理HW和LEO相关的知识。
代码相关
有了上面的原理,消费者的代码部分相对就好理解了,涉及到性能的优化,也会在代码中实现,具体参考代码注释。但是一般消费者是storm、spark streaming或者flink,又是另外的写法了。
package com.boe.consumer;
import com.alibaba.fastjson.JSONObject;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.*;
/**
* 自定义一个消费者,从指定的topic消费数据
*/
public class MyConsumer {
public static void main(String[] args) throws ExecutionException, InterruptedException {
//step1 配置消费者参数,也跟kafka性能有关
Properties props=new Properties();
//1 连接broker
props.put("bootstrap.servers","hadoop01:9092,hadoop02:9092,hadoop03:9092");
//2 指定key和value的反序列化
//还需要指定消费组id,否则报错
props.put("group.id","clyang");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//3 消费者给coordinator发送心跳的时间间隔
props.put("heartbeat.interval.ms",1000);
//4 coordinator认为多久没接受到心跳,就认为超时
props.put("session.timout.ms",10*1000);
//5 隔多久执行一次poll
props.put("max.poll.interval.ms",10*1000);
//6 一次poll返回多少条record,默认是500条
props.put("max.poll.records",1000);
//7 不要回收socket连接
//consumer跟broker的socket连接如果空闲超过了一定的时间,此时就会自动回收连接,
//但是下次消费就要重新建立socket连接,这个建议设置为-1,不要去回收连接
props.put("connection.max.idle.ms",-1);
//8 设置自动提交offset
props.put("enable.auto.commit","true");//注意kafka版本,1.0.x是这么写
//9 多久自动提交offset
props.put("auto.commit.interval.ms",1000);
//10 设置consumer重启后,从分区最新的offset读取
//latest:如果分区下有提交的offset,从这个offset开始读取,否则从最新的数据开始读取
//earliest:如果分区下有提交的offset,从这个offset开始读取,否则从头开始读取
//none:如果分区下有提交的offset,从这个offset开始读取,只要有一个分区没有提交的offset,就报错
props.put("auto.offset.reset","latest");
//step2 创建一个消费者对象
KafkaConsumer<String,String> consumer=new KafkaConsumer<String, String>(props);
//step3 订阅主题
consumer.subscribe(Arrays.asList("topicA"));
//创建线程池,小池子大队列,只有核心线程,没有临时线程,工作队列是个阻塞式队列
ExecutorService threadPool= Executors.newFixedThreadPool(5);
//step4 不断消费数据,并对数据进行处理
try {
while(true){
//超时时间是3s
//新版本的kafka,这个poll方法将干很多事情
//如监听这个消费者跟多个topic的分区所在broker的通信,如有新的数据就会拉取过来,缓存数据、内存里更新offset
ConsumerRecords<String, String> consumerRecords = consumer.poll(3000);
for(ConsumerRecord<String, String> record:consumerRecords){
//1 写法1
//如果value是json格式,将其转换成JSON对象
//JSONObject json=JSONObject.parseObject(record.value());
//System.out.println("消费的消息是"+json.toJSONString()+",name为:"+json.getString("name"));
//2 写法2 可以放到线程池去消费
//实现Runnable接口
threadPool.submit(new ConsumerTask(record));
}
}
}catch (Exception e) {
e.printStackTrace();
System.out.println("消费消息失败");
consumer.close();
}
}
}
/**
* 如果实现Runnable接口,出现异常,需要在run方法进行捕获
*/
class ConsumerTask implements Runnable{
private ConsumerRecord<String, String> record;
public ConsumerTask(ConsumerRecord<String, String> record) {
this.record = record;
}
@Override
public void run() {
JSONObject json=JSONObject.parseObject(record.value());
System.out.println("消费的消息是"+json.toJSONString()+",消息的分区为:"+record.partition()+",消息的offse为:"+record.offset());
}
}
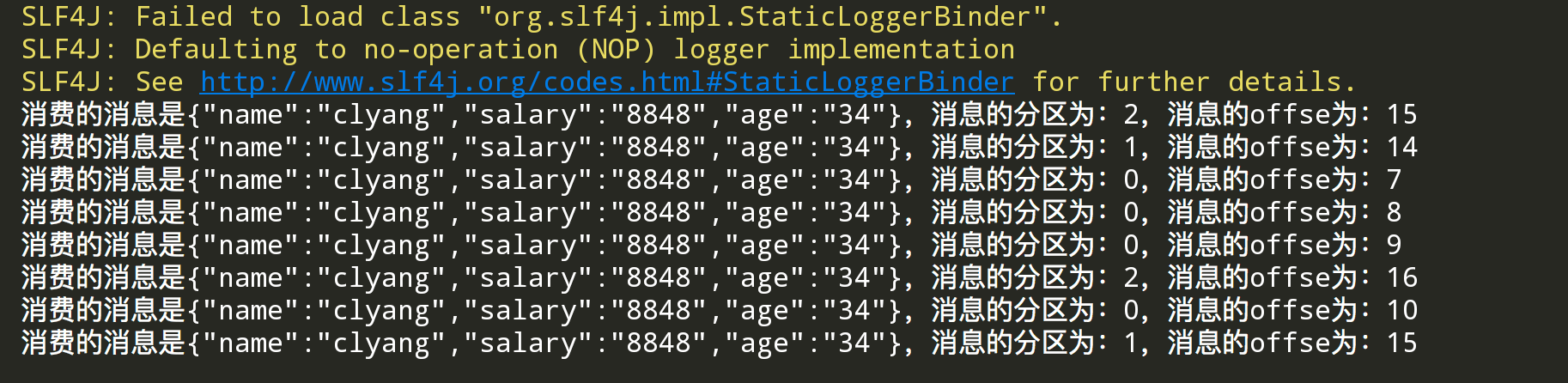
执行后,控制台显示消费成功,并且从消息的offset变化可以看出,每生产一条数据,同一个分区的消息,其offset都会加1。
分区器
kafka中也可以自定义分区器,根据key的不同,实现数据写入到指定分区的效果,下面简单的实现一个,实现以下效果。
-
key为"china",发给0号分区
-
key为"usa",发给1号分区
-
key为"korea",发给2号分区
以下是代码部分,类似MapReduce的自定义分区器,它需要实现一个kafka提供的接口Partitioner,实现里面的partition方法 。
package com.boe.partitioner;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import java.util.List;
import java.util.Map;
/**
* 自定义分区器
*/
public class MyPartitioner implements Partitioner {
//初始化值
int partitionNum;
/**
* 主要重写这个方法,假设有topic country三个分区,producer将key为china、usa和korea的消息分开存储到不同的分区,否则都放到0号分区
* @param topic 要使用自定义分区的topic
* @param key 消息key
* @param keyBytes 消息key序列化字节数组
* @param value 消息value
* @param valueBytes 消息value序列化字节数组
* @param cluster 集群元信息
* @return
*/
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
String keyStr=(String) key;
//获取分区信息
List<PartitionInfo> partitionInfoList=cluster.availablePartitionsForTopic("country");
int partitionInfoListSize=partitionInfoList.size();
//判断是否有三个分区
if(partitionInfoListSize==3){
switch (keyStr){
case "china":
partitionNum=0;
break;
case "usa":
partitionNum=1;
break;
case "korea":
partitionNum=2;
break;
default:
partitionNum=0;
break;
}
}
//返回分区序号
return partitionNum;
}
@Override
public void close() {
//资源的清理工作在这里执行
System.out.println("-----分区结束-----");
}
@Override
public void configure(Map<String, ?> configs) {
//资源的初始化工作在这里执行
partitionNum=0;
}
}
实现了自定义分区器,需要在上面生产者producer的代码中,添加分区器到props文件中,才能生效!
package com.boe.producer;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
/**
* 定义一个生产者,将消息发送出去
*/
public class MyProducer {
public static void main(String[] args) throws InterruptedException, ExecutionException {
//step1 配置参数,这些跟优化kafka性能有关系
Properties props=new Properties();
//1 连接broker
props.put("bootstrap.servers","hadoop01:9092,hadoop02:9092,hadoop03:9092");
//2 key和value序列化
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//3 acks
// -1 代表所有处于isr列表中的follower partition都会同步写入消息成功
// 0 代表消息只要发送出去就行,其他不管
// 1 代表发送消息到leader partition写入成功就可以
props.put("acks","-1");
//4 重试次数
props.put("retries",3);//大部分问题,设置这个就可以解决,生产环境可以设置多些 5-10次
// 5 隔多久重试一次
props.put("retry.backoff.ms",2000);
//6 如果要提升kafka的吞吐量,可以指定压缩类型
props.put("compression.type","none");
//7 缓冲区大小,默认是32M
props.put("buffer.size",33554432);
//8 一个批次batch的大小,默认是16k,需要根据一条消息的大小去调整
props.put("batch.size",323840);//设置为32k
//9 如果一个batch没满,达到如下的时间也会发送出去
props.put("linger.ms",200);
//10 一条消息最大的大小,默认是1M,生产环境中一般会修改变大,否则会报错
props.put("max.request.size",1048576);
//11 一条消息发送出去后,多久还没收到响应,就认为是超时
props.put("request.timeout.ms",5000);
//12 使用自定义分区器
props.put("partitioner.class","com.boe.partitioner.MyPartitioner");
//step2 创建生产者对象
KafkaProducer<String,String> producer=new KafkaProducer<String, String>(props);
//step3 使用消息的封装形式
//自定义分区测试用的,可以看到自定了key,以下每条消息发送两次
//ProducerRecord<String,String> record=new ProducerRecord<String,String>("country","china","{'name':'china','population','14'}");
//ProducerRecord<String,String> record=new ProducerRecord<String,String>("country","usa","{'name':'usa','population','3'}");
//ProducerRecord<String,String> record=new ProducerRecord<String,String>("country","korea","{'name':'korea','population','1'}");
//step4 调用生产者对象的send方法发送消息,有异步和同步两种选择
//1 异步发送,一般使用异步
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception==null){
System.out.println("消息发送到分区"+metadata.partition()+"成功");
}else{
System.out.println("消息发送失败");
//TODO 写入到redis
}
}
});
Thread.sleep(10*1000);
//2 同步发送,需要等待一条消息发送完成,才能发送下一条消息
//RecordMetadata recordMetadata = producer.send(record).get();
//System.out.println("发送到的分区是:"+recordMetadata.partition());
//step5 关闭连接
producer.close();
}
}
为了验证分区器的效果,先创建一个测试的topic。
# 三个分区,三个replica,topic名为country
[root@hadoop01 /home/software/kafka-2/bin]# sh kafka-topics.sh --create --zookeeper hadoop01:2181 --replication-factor 3 --partitions 3 --topic country
Created topic "country".
然后上面生产者代码执行发送消息,每发送一条使用kafka shell查看一次结果,发现数据都发送到了指定的分区。最后每个分区,都是2条消息,实现分区的效果。
# key="china"->分区0 key="usa"->分区1 key="korea"->分区2
[root@hadoop01 /home/software/kafka-2/bin]# sh kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list hadoop01:9092 --topic country
country:2:2
country:1:2
country:0:2
以上,理解不一定正确,但学习就是一个不断了解和纠错的过程。
参考博文:
(1)《Apache Kafka实战》
(2)http://kafka.apache.org/documentation.html#producerconfigs 生产者配置说明
(3)http://kafka.apache.org/documentation.html#consumerconfigs 消费者配置说明
(4)https://www.cnblogs.com/youngchaolin/p/12535704.html controller获取元数据