接下来了解了一下MapReduce中的shuffle,它就是map端产生输出到reduce端消化map端输出的全部过程。
map端

-
本地磁盘的文件如果有多份,会保存不同的block块到datanode,block块的个数决定了map任务数的个数,如图有3个block块,对应有3个map任务在执行,以第一为例,刚开始map方法会逐行读取block块信息,将当前行相对block块的字节偏移量和行内容作为key-value输入,将单词和出现的次数作为key-value输出,先保存在环形缓冲区中。
-
环形缓冲区默认是100M,当map输出往里存入的key-value对越来越多,达到缓冲区阈值80%,则会开始溢出(spill)写入到本次磁盘,会有一个专门的后台线程负责进行。如果写入到内存的速度比溢出写到磁盘的速度快,则会发生阻塞,即环形缓冲区达到100M时会阻塞写入,直到缓冲区内容全部写出到磁盘,才开始重新写入到缓冲区。另外环形缓冲区大小和阈值是可以设置的,通过mapreduce.task.io.sort.mb和mapreduce.map.sort.spill.percent可以进行修改。
-
写入到磁盘是有分区的,不同的key-value会写到对应的分区,这里有两个问题,分区如何确定数目以及如何知道键值对要放入到哪个分区。第一个问题是根据设定的reduce任务数确定的,其使用job的setNumReduceTasks方法指定,图中有三个分区代表设定的数目是3。另外落入分区前,job任务会有默认的分区器,使用(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks方法返回要落入的分区编号,这里reduce任务就是3,因此只能是0,1,2三个编号,对应图中白蓝红三个区域。
public class HashPartitioner<K2, V2> implements Partitioner<K2, V2> { public void configure(JobConf job) {} /** Use {@link Object#hashCode()} to partition. */ public int getPartition(K2 key, V2 value, int numReduceTasks) { return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; } } -
在溢出写到溢出文件前,内存中内容会越来越多,肯定不仅仅只有图中所示的一个单词保存在里面,一般一个分区会有多个不同的key组成,这样数据会在内存中先进行一次排序,按照字母顺序来排序后再写出到对应分区。
-
如果设置了combine(可选非必须动作),并且后面溢出文件数目满足combine的最小数目时,接下来会进行combine动作,即相同key的key-value对会和并,如图中(god,2),(bless,3)这种就是combine后的结果,如果没满足combine条件,则如图中第三个map的结果,保存多份的(god,1),(bless,1)。combine就是考虑到有些key会有很多的键值对,会导致数据很大占存储空间可能产生数据倾斜,因此先合并一次,不仅仅可以减少存储空间也可以减轻随后reduce任务的压力。combine的数目也可以通过mapreduce.map.combine.minspills来设定。
-
如果设置了compress(可选非必须动作),还会继续对合并后的数据进行一次压缩,最后再保存到磁盘溢出文件里去。压缩可以通过在main方法的Configuration对象中设置,设定后将在map输出,reduce输出和文件输出到hdfs都会压缩。
//开启map输出进行压缩的功能 configuration.set("mapreduce.map.output.compress", "true"); //设置map输出的压缩算法是:BZip2Codec,它是hadoop默认支持的压缩算法,且支持切分 configuration.set("mapreduce.map.output.compress.codec", "org.apache.hadoop.io.compress.BZip2Codec"); //开启job输出压缩功能 configuration.set("mapreduce.output.fileoutputformat.compress", "true"); //指定job输出使用的压缩算法 configuration.set("mapreduce.output.fileoutputformat.compress.codec", "org.apache.hadoop.io.compress.BZip2Codec"); -
最后针对多个溢出写的磁盘文件最后做一次合并操作,将其合并到一个大的溢出文件,如图所示。可以看到第三个map计算节点由于溢出文件没达到3,因此前面combine不进行,依然保存多份(god,1),(bless,1)。
reduce端
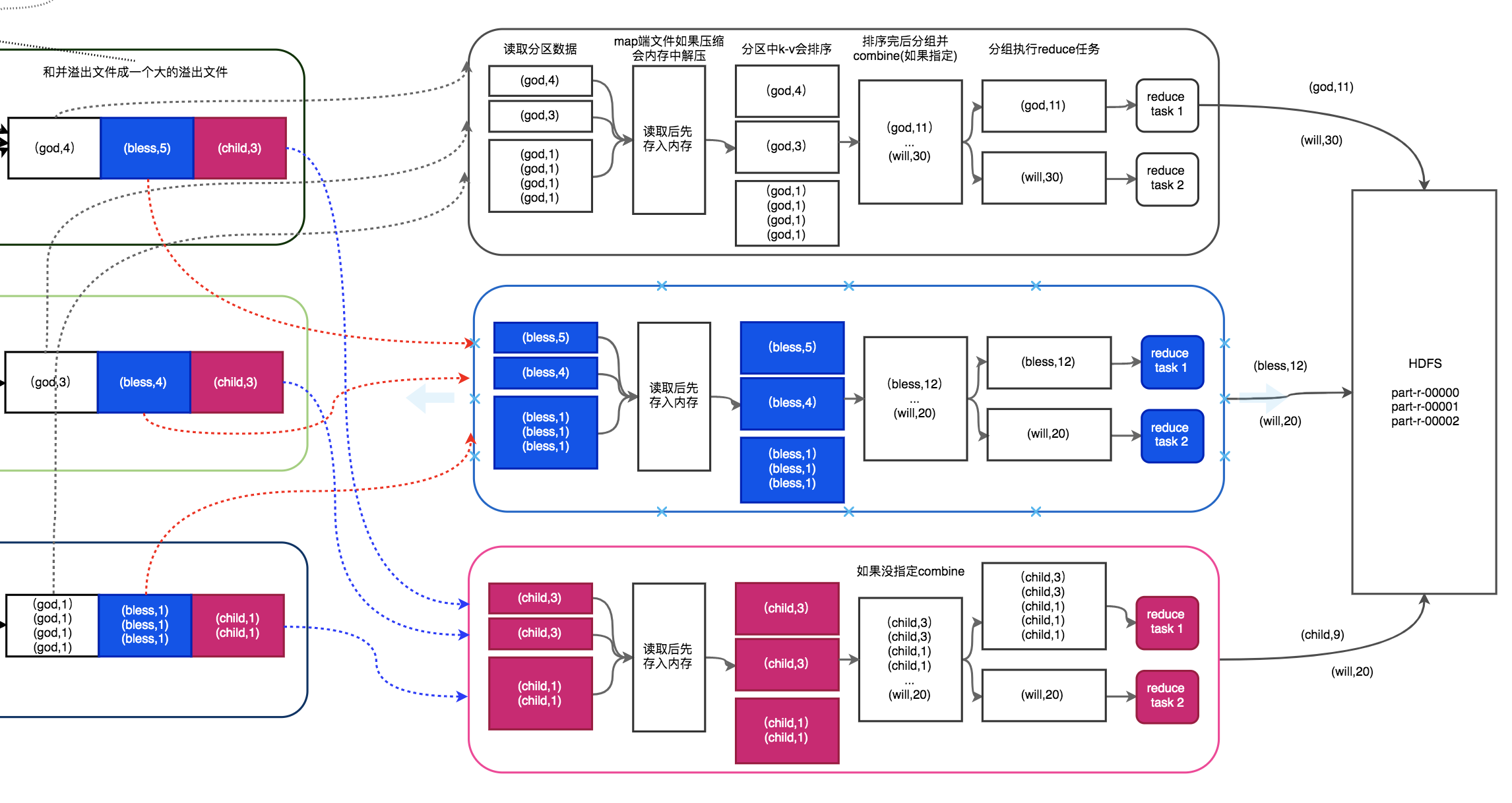
- reduce端会根据分区位置,当map计算节点任务执行完成后,通过http从map端取出属于自己的那一份分区数据,如图所示。
- 跟map端类似的是,这里如果获取的map数据比较小则会保存在jvm内存中,当数据比较大达到内存的阈值(默认0.66)或者map输出的数的阈值(默认1000)时,也会开始写入到本地磁盘。可以通过mapreduce.reduce.shuffle.input.buffer.percent设定内存阈值,通过mapreduce.reduce.merge.inmen.threshold来设定map数阈值。
- map中数据如果有压缩会在写出磁盘前会进行解压缩,同样一个分区中获得的map信息不仅仅只有god一个单词,还会有其他的单词,这里也会进行一次排序,为什么map中排序了这里还需要排序呢,因此这里得到的map是来自多个map task产生的数据,单个map是排序好了,但是合到一起了顺序还不是完全有序的,只是相对来说有序一些,reduce端对一个相对有序的数据进行排序类似插入排序也会减轻排序压力。
- 同样若job中指定了combine,排序完后还会进行combine的动作,即将同名key的value和并。参考图中reduce 计算节点1,如果没指定就不会进行combine的动作,依然保存多份键值对,参考图中reduce计算节点3。
- 这样就开始写入一份溢出文件到磁盘,不断循环写直到写完,写完后会并大的溢出文件,默认一次和并10个。
- 和并完后分组,根据分组结果执行reduce task分组任务。
- 最后写出reduce结果到hdfs,如果设置了压缩这里也会生效。
整体效果shuffle图如下。

以上是对shuffle的理解,后续再修改完善。
参考博文
(1)《hadoop核心技术卷》