目录
一些说明
代码准备
说明
(1)本部分排序算法均为升序
(2)x.compareTo(y) 返回值若大于0则x比y大,若等于0则相等
(3)抽象算法
public static void sort(Comparable[] a){ //排序方法 } private static boolean less(Comparable v,Comparable w){ //当v小于w时返回true return v.compareTo(w) < 0; } private static void exch(Comparable[] a,int i,int j){ //交换数组中i与j的位置 }
(4)主要参考了知乎上两篇算法的总结:https://zhuanlan.zhihu.com/p/40695917和https://zhuanlan.zhihu.com/p/52884590,特别建议看一下动画演示过程;算法(普林斯顿版的)提供了模板方法以及网上的一些其他博客。
(5)所有源代码已发布的GitHub上:
(6)算法测试时的代码性能有多方面影响,因此最好使用标准算法模板比较,一开始在测试时采用自己写的代码,执行效率很低,有时原理上速度最快的算法竟然是最慢的,这就是代码实现时出现了问题。
(7)在测试时IDEA的断言是默认关闭的,需要手动打开,打开方法可以参考博客软件使用-IDEA Java中的解决方法。
排序算法总结
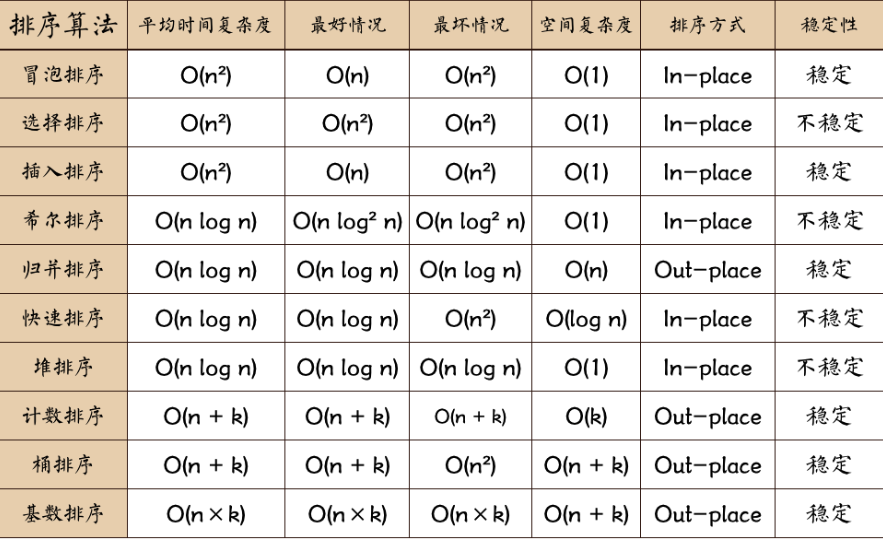
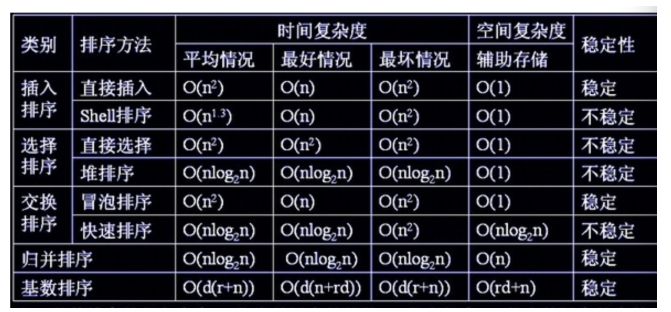
一些术语说明:
- n: 数据规模
- k: “桶”的个数
- In-place: 占用常数内存,不占用额外内存
- Out-place: 占用额外内存
- 稳定 :如果a原本在b前面,而a=b,排序之后a仍然在b的前面;
- 不稳定 :如果a原本在b的前面,而a=b,排序之后a可能会出现在b的后面;
- 内排序 :所有排序操作都在内存中完成;
- 外排序 :由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行;
代码准备
交换方法:
//采用异或能够提高运行效率 public static void swap(int[] arr, int i, int j) { arr[i] = arr[i] ^ arr[j]; arr[j] = arr[i] ^ arr[j]; arr[i] = arr[i] ^ arr[j]; }
//更一般的交换方法,此处没限定arr的类型为compareTo因为在比较方法中已经限定过了,object为父类不会影响的,但此时不可以简单异或了
//数组必须是可以比较的才有办法排序,对于不能直接比较的对象应该重写 compareTo方法使之可以比较。此处用private比较合适,因为交换只是一个内部使用的方法
private static void swap(Object[] arr, int i, int j) { Object t = arr[i]; arr[i] = arr[j]; arr[j] = t; }
测试辅助类:
这个代码最后还有改
public class SortTestHelper { //SortTestHelper不允许产生任何实例 private SortTestHelper(){}; // 生成有n个元素的随机数组,每个元素的随机范围为[rangeL, rangeR] // 全部都采用static是为了避免使用时还要再new SortTestHelper public static Integer[] generateRandomArray(int n,int rangeL,int rangeR){ // 维护代码的健壮性 assert rangeL <= rangeR; // 这里用了Integer是因为产生随机数组时需要Integer类型方法 Integer[] arr = new Integer[n]; // 生成随机数组 for (int i = 0; i < n; i++) { // Math.random()默认产生大于等于0.0且小于1.0之间的随机double型随机数 arr[i] = new Integer((int)(Math.random()*(rangeR-rangeL + 1)+ rangeL)); } return arr; } /** * 生成一个近乎有序的数组 * 首先生成一个含有[0...n-1]的完全有序数组, 之后随机交换swapTimes对数据 * swapTimes定义了数组的无序程度: * swapTimes == 0 时, 数组完全有序 * swapTimes 越大, 数组越趋向于无序 */ public static Integer[] generateNearlyOrderedArray(int n, int swapTimes){ Integer[] arr = new Integer[n]; // 产生一个有序的数组 for (int i = 0; i < n; i++) { arr[i] = new Integer(i); } for (int i = 0; i < swapTimes; i++) { // 产生两个随机数 int a = (int)(Math.random()*n); int b = (int)(Math.random()*n); //交换位置 int t = arr[a]; arr[a] = arr[b]; arr[b] = t; } return arr; } // 打印arr数组的所有内容 public static void printArray(Object[] arr){ for (int i = 0; i < arr.length; i++) { System.out.print(arr[i]+" "); } System.out.println(); } // 判断arr数组是否有序 public static boolean isSorted(Comparable[] arr){ for (int i = 0; i < arr.length; i++) { if (arr[i].compareTo(arr[i+1]) > 0) { return false; } } return true; } // 测试sortClassName所对应的排序算法排序arr数组所得到结果的正确性和算法运行时间 public static void testSort(String sortClassName, String sortName,Comparable[] arr){ // 通过java的反射机制,通过排序的类名,运行排序函数 try { // 通过sortClassName获得排序函数的Class对象 Class sortClass = Class.forName(sortClassName); // 通过排序函数的Class对象获得排序方法 Method sortMethod = sortClass.getMethod(sortName,new Class[]{Comparable[].class}); // 排序参数只有一个,是可比较数组arr Object[] params = new Object[]{arr}; // 获取当前系统时间 long startTime = System.currentTimeMillis(); // 调用排序函数 sortMethod.invoke(null,params); long endTime = System.currentTimeMillis(); //是否有序 assert isSorted( arr ); System.out.println( sortClass.getSimpleName()+ " : " + (endTime-startTime) + "ms" ); }catch (Exception e){ e.printStackTrace(); } } }
1 冒泡排序
算法思想:
两两比较找最值。先把最大的数放后面,依次比较相邻的两个数,将小数放前面,大数放后面,这样第一次遍历就可以使做大的数放在了后面;第二次继续从起始位置遍历,把较大的数放在了倒数第二个位置,后面以此类推。时间复杂度O(n^2)。
算法流程:
1. 两两交换,使得最大元素在最后面
2. 在剩下的元素中,重复1过程
代码实现:
public static void sort3(Comparable[] arr){ int n = arr.length; if (arr == null || n < 2){ return; } //最外层的循环控制结束位置 for (int i = n-1; i >0 ; i--) { //内层循环负责两两交换 for (int j = 0; j < i; j++) { if (arr[j].compareTo(arr[j+1]) > 0){ swap(arr,j,j+1); } } } }
优化点:
冒泡被认为是最低效的排序方式是因为不管列表是否有序,都需要遍历整个数组没有被排好的部分进行交换。但是如果在排序过程中没有交换发生,那么就意味着列表是有序的。这样也成为了冒泡排序的优点:当列表有序的时候可以立刻结束,对于几乎有序的列表排序其时间复杂度为O(n)。
优化代码:
public static void sort2(Comparable[] arr){ int n = arr.length; if (arr == null || n < 2){ return; } for (int i = 0; i < n; i++) { // 是否交换的标志 boolean swaped = false; for (int j = 0; j < n-1-i; j++) { if (arr[j].compareTo(arr[j+1]) > 0){ swap(arr,j,j+1); swaped = true; } } // 当没有交换发生时便结束循环 if (swaped == false){ break; } } }
2 选择排序
算法思想:首先,找到数组中最小的那个元素,其次,将它和数组的第一个元素交换位置(如果第一个元素就是最小元素那么它就和自己交换)。再次,在剩下的元素中找到最小的元素,将它与数组的第二个元素交换位置。如此往复,直到将整个数组排序。这种方法叫做选择排序,因为它在不断地选择剩余元素之中的最小者,其时间复杂度为O(n^2)。
算法流程:
1. 在所有元素中找到最小的元素,并与首元素交换
2. 在剩下的元素中,重复1过程
首先找到数组中最小的元素:
![]()
然后将最小元素与首元素交换
![]()
接着找次小的元素:
![]()
然后和第二个元素交换位置,接着依次类推即可。
![]()
代码实现:
//之所以用compare类型因为数组肯定是要比较的因此必须要是能够比较的类型,这也意味着自己构造的对象必须重写compareTo方法 public static void sort(Comparable[] arr){ if (arr == null || arr.length < 2) { return; } int n = arr.length; for (int i = 0; i < n - 1; i++) { //寻找[i,n)区间里的最小值的索引 int minIndex = i; for (int j = i+1; j < n; j++) { //使用compareTo方法比较 if (arr[j].compareTo(arr[minIndex]) < 0) { minIndex = j; } } swap(arr, i, minIndex); } }
3 插入排序
算法思想:
认为第一个数据是有序的,后面的数据与依次前面的比较,插入到合适的位置。最好情况为O(n)最坏情况为O(n^2)。选择排序的优点在于当前面有序时便可不用遍历即arr[j] < arr[j + 1](当升序排列时)
图示:
首先考虑第一个元素8,当只考虑第一个元素时8就是有序的,因此考虑下一个元素6,需要把6放在合适的位置,因为6比8小所以要和8互换位置
![]()
互换完位置后考虑下一个元素2,首先和8比较,比8小所以要互换位置
![]()
![]()
交换完后再和6比较,比6小继续交换位置,那么此时2,6,8三个元素都是有序的,接着依次类推即可。
![]()
算法流程:
1. 第一个元素有序,从第二个元素开始向前遍历,寻求插入的合适位置(待插入的位置比自己大,这里暗含不需要比较全部元素)
2. 重复1过程
代码实现:
public static void sort(Comparable[] arr){ if (arr == null || arr.length < 2){ return; } int n = arr.length; for (int i = 1; i < n; i++) { //arr[j].compareTo(arr[j-1]) < 0这个判断放在for上要比在for循环内部判断的效率要高很多,这样实现了提前跳出循环 for (int j = i; j > 0 && (arr[j].compareTo(arr[j-1]) < 0); j--) { swap(arr,j,j-1); } } }
优化点:
此时从理论上而言插入排序可以提前终止,即在最优情况下为O(n),但测试时有时会发现插入排序的效果反而要差一些。问题在于swap方法,在插入排序时需要不断的进行交换这样便涉及到了三次赋值操作这样在某些情况下反而比选择排序效果要差,因此要对交换进行优化,寻找内层是否也可以只进行一次赋值操作。图示如下:
首先考虑第一个元素即是有序的,然后考虑第二个元素
![]()
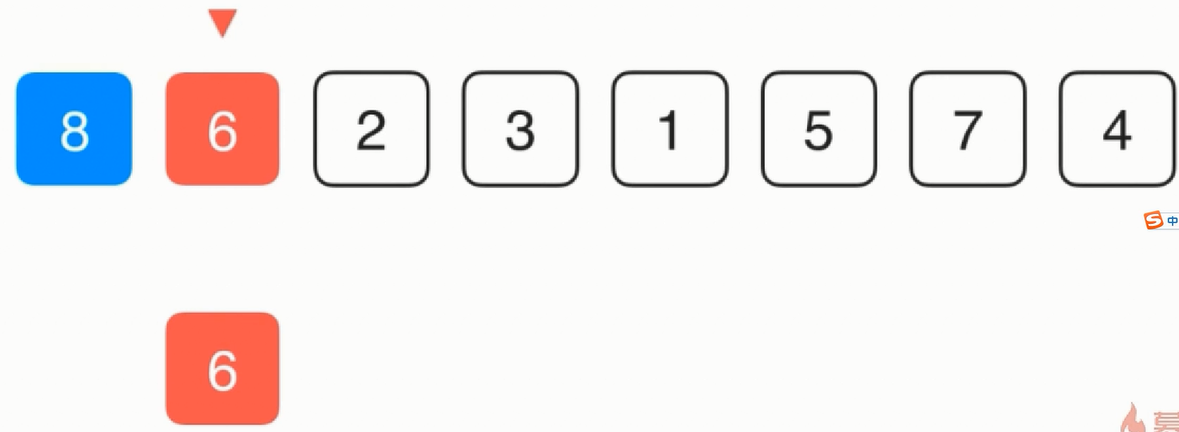
在第二个元素的时候不贸然进行交换而是先复制一份,然后考虑6是不是应该在当前的位置,方法就是和当前的位置的前一个位置比较,发现比它小
所以把8复制一份,然后考虑6是不是应该在前一个位置,因为此时是第0个位置,所以不用比较直接放即可。
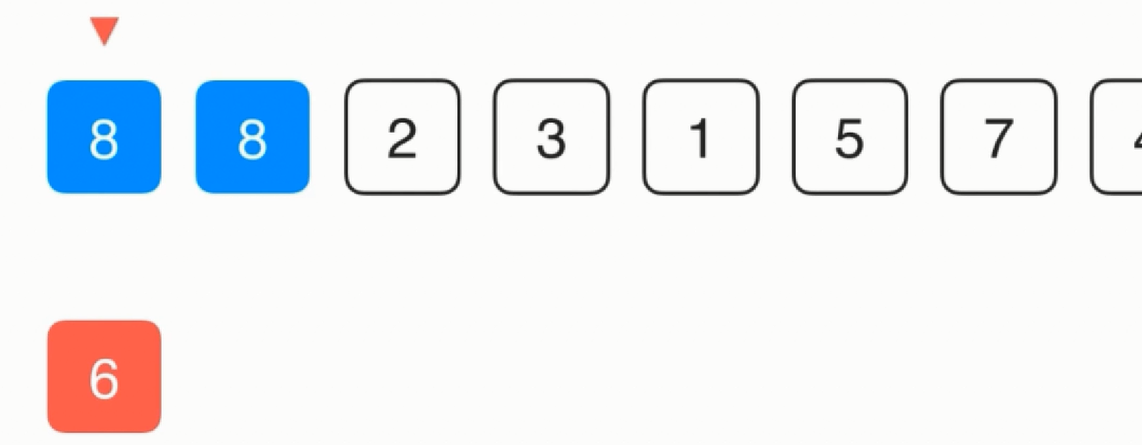
放置完后接着考察2,首先仍是把2复制一份,然后和8比较,比8小所以把8复制到2的位置,然后再和6比较
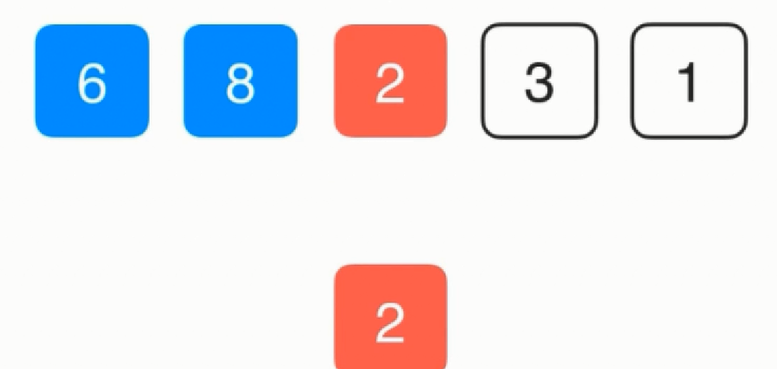
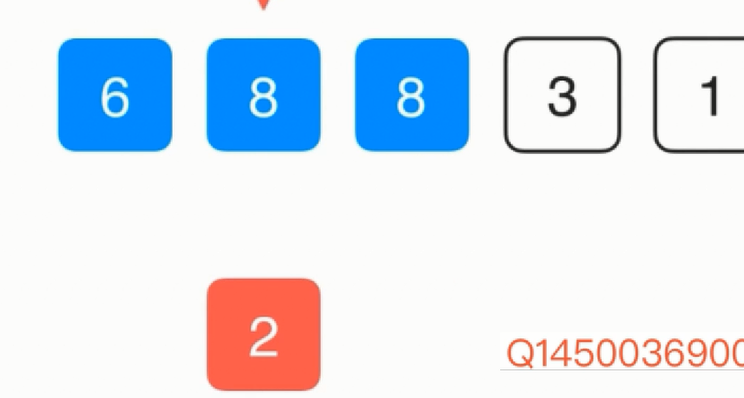
接着把6复制一份,同样6是第0个位置,所以直接把2放过去即可,同样的依次类推其他数据。
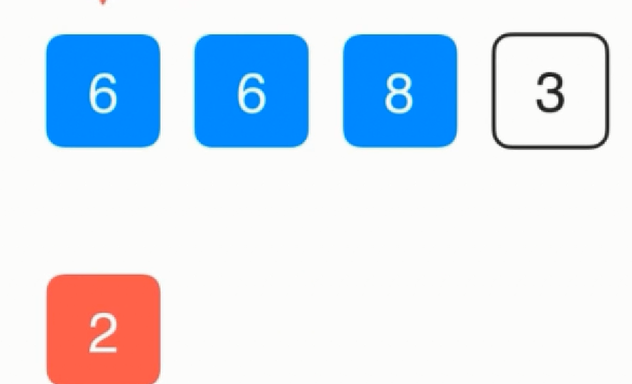
代码实现:
//之所以用compare类型因为数组肯定是要比较的因此必须要是能够比较的类型,这也意味着自己构造的对象必须重写compareTo方法 public static void sort(Comparable[] arr){ if (arr == null || arr.length < 2) { return; } for (int i = 0; i < arr.length; i++) { //先把要比较的元素复制一份 Comparable e = arr[i]; //从后向前遍历,遇到比e大的就把元素向后移动 int j = i; for (;j > 0 && arr[j-1].compareTo(e) > 0; j--) { arr[j] = arr[j-1]; } //在停止的位置处赋值e,这样内层循环就只有一次赋值操作 arr[j] = e; } }
小结:冒泡、选择、插入三者的关联
冒泡排序是效率最低的排序方式,即使增加了提前终止操作但这个提前终止的条件太严格了,没有发生交换时才可以有效。而插入排序的提前终止则比较宽泛,只要比满足前一个元素大就会终止,因此虽然二者的交换次数一样但是插入排序的比较次数少了很多,因此效率要比冒泡排序要高。选择排序则是从另一角度来优化冒泡排序:较少交换次数。选择排序时每次找到剩余元素中最小(最大)元素的索引,与未排序的最后一个元素交换位置,这样做不用像冒泡排序那样每次都两两交换比较,是的只需要执行O(n)次交换操作,O(n^2)次赋值操作,效率的确提高很多,这也是测试时有些情况下选择排序的速度要比插入排序速度快的原因。既然选择排序给出了优化赋值、交换操作的方法,那么也可以对插入排序进行赋值优化操作,这便形成了插入排序中给出的第二种排序算法。
测试效果:
这个图是有问题的

4 希尔排序
算法由来:
对于大规模乱序数组插入排序很慢,因为它只会交换相邻的元素,因此元素只能一点一点地从数组的一端移动到另一端(这也是因为插入排序本质上还是对冒泡排序的改进)。例如,如果主键最小的元素正好在数组的尽头,要将它揶到正确的位置就要N-1次移动。希尔排序为了加快速度改进了插入排序,交换不相邻的元素以对数组的局部进行排序,并最终用插入排序将局部有序的数组排序。希尔排序是对插入排序的改进。
算法思想:
使数组中任意间隔为h的元素都是有序的。这样的数组被称为h有序数组。换句话说,一个h有序数组就是h个互相独立的有序数组编织在一起组成的一个数组在进行排序时,如果h很大,我们就能将元素移动到很远的地方,为实现更小的h有序创造方便。用这种方式,对于任意以1结尾的h序列,我们都能够将数组排序。这就是希尔排序。如果对这点不清楚可以在网上搜索一些图。关键是要明白性能的好坏也是与h相关的,不同长度的数组要选择不同的h。
算法图例:
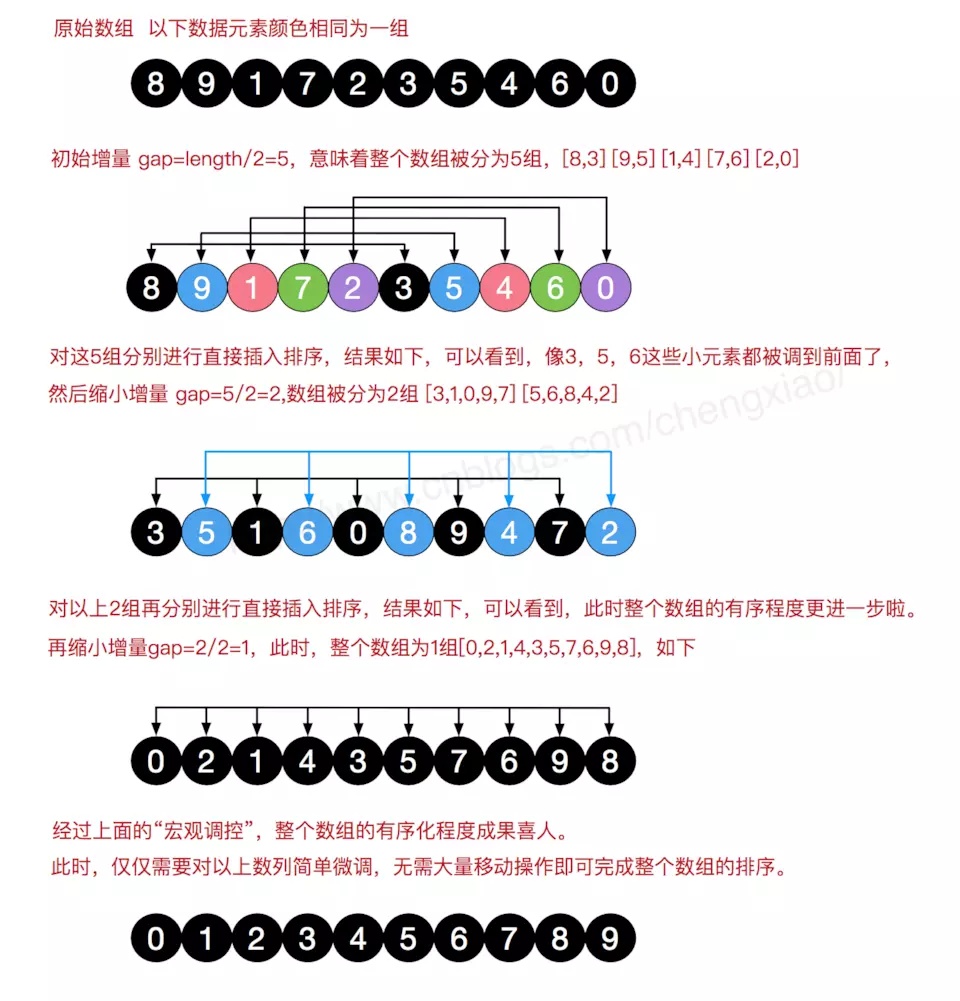
注:在进行插入排序时并不是第一组遍历完再遍历第二组的,而是同时对分组进行遍历进行插入排序。既然在前面插入改进算法中已经把交换改进为了赋值操作,那么在这里也要把这种方法使用上。
算法流程:
1. 以间隔h进行插入排序
2. 缩小h继续插入排序,直至h为1
代码实现:
public static void sort2(Comparable[] arr){ int N = arr.length; int h = 1; //根据数组的长度设定间隔,这里间隔是按照数学计算出来的公式设定的,使其能够达到最优。 while (h < N/3){ h = 3 * h + 1; } //以间隔h进行插入排序,这里用大于等于1进行判断,效率要快很多 while (h >= 1){ //以间隔h进行插入排序 for (int i = h; i < N; i++) { for (int j = i;j >= h &&(arr[j].compareTo(arr[j-h]) < 0) ; j -=h) { swap(arr,j,j-h); } } h/=3; } }
上面是算法一书中给出的模板方法,但是我们还可以进行优化改进。既然希尔排序是把大数据量的线性表分为小数据量的线性表,进行插入排序,那么完全可以使用前面的优化交换方法的思路,再优化一下swap方法
public static void sort3(Comparable[] arr){ int N = arr.length; int h = 1; //生成合适的h while (h < N/3){ h = 3 * h + 1; } //以间隔h进行插入排序 while (h >= 1){ for (int i = h; i < N; i++) { Comparable temp = arr[i]; int j = i; for (; j >= h &&(temp.compareTo(arr[j-h]) < 0) ; j -=h) { arr[j] = arr[j-h]; } arr[j] = temp; } h/=3; } }
5 归并排序
算法思想:
希尔排序中的思路是把大数组分为小数组进行插入排序,归并排序也是借鉴了这个思路:把一个大数组拆成两个小数组,每个小组有序了,再进行合并。但归并排序把拆分进行了升华:分治思想。
分治思想:
假如给定8个元素的数列,一般情况下冒泡排序需要比较8轮,每轮把一个元素移动到数列一端,时间复杂度是O(n^2)。但如果采用分治的思想,每次拆成两部分,这样logn轮后便不可再拆分了。那么时间复杂度为:T[n]=2T[n/2]+O(n),经过属性计算可以得到其时间复杂度为O(nlogn)。这样可以清楚的看到采用分治思想后其时间复杂度大幅度下降了。
递归算法时间复杂度:
T[n]=aT[n/b]+f(n)。T[n]:原数组;a:原数组被拆成了a个小数组;T[n/b]:每个小数组的规模是n/b;f(n):递归返回原数组的时间复杂度。
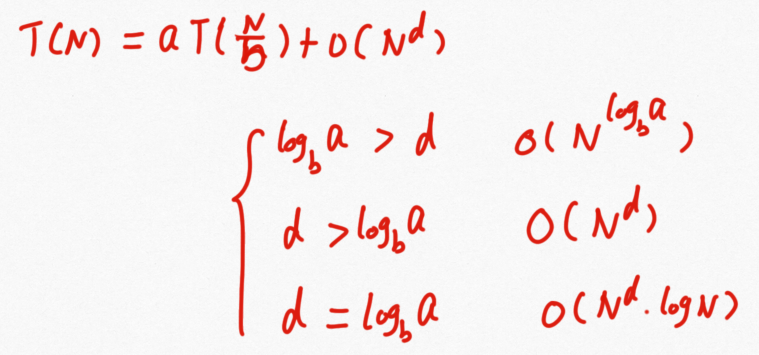
以归并排序为例,每次是评价拆分成2部分,因此a=b=2,拆分后还有一步合并的操作,其时间复杂度为O(n)。对于a、b取不同值的时候其时间复杂度也不同,比较好的是取a=b=2,这也是为什么快速排序中要避免拆分不平衡的情况发生,当极端情况下其时间复杂度为O(n^2)。
代码实现:
归并排序涉及到了一个基础思想:递归。如何把大数组拆成小数组?希尔排序的答案是利用for循环,调整间隔,归并排序的答案则是利用递归进行拆分。合并的时候同样也是按照递归的方式进行合并。
//递归拆分合并 private static void mergeSort(Comparable[] arr,int left,int r){ if (left >= r){ return; } //不断进行拆分 int mid = left + (r - left)/2; mergeSort(arr,left,mid); mergeSort(arr,mid+1,r); //拆分完后进行合并 merge(arr,left,mid,r); }
希尔排序在合并的时候实质上是对原数组进行操作的,合并的过程就是排序的过程。
// 将arr[left...mid]和arr[mid+1...r]两部分进行归并 private static void merge(Comparable[] arr, int left, int mid, int r) { int i = left,j = mid+1; //先把两部分的数据都复制到一个数组中 for (int k = left; k <= r; k++) { aux[k] = arr[k]; } //在辅助数组中以i,j进行遍历,依据大小进行赋值操作修改原数组 for (int k = left; k <= r; k++) { if (i > mid){ arr[k] = aux[j++]; }else if (j > r){ arr[k] = aux[i++]; }else if (aux[i].compareTo(aux[j]) > 0){ arr[k] = aux[j++]; }else { arr[k] = aux[i++]; } } }
算法的主体部分:
// 声明一个辅助数组 private static Comparable[] aux; //希尔排序的算法 public static void sort(Comparable[] arr){ //因为辅助数组要一直用,因为定义为类属性,便不用每次在递归方法中定义了 aux = new Comparable[arr.length]; mergeSort(arr,0,arr.length-1); }
自底向上的归并:
从左到由右进行遍历归并,每遍历一次间隔加倍,直至间隔为数组长度的一半,将两个数组归并
//使用自底向上的归并只不过是把递归换成for循环 public static void sort2(Comparable[] arr){ int N = arr.length; aux = new Comparable[N]; for (int size = 1; size < N; size += size) { //每次从左向右以size为间隔进行归并的,因此left每次移动的是2倍的size for (int i = 0; i < N-size; i += size+size) { //对 arr[i...i+sz-1] 和 arr[i+sz...i+2*sz-1] 进行归并,若为奇数则可能会超出数组索引,因此取最小值 merge(arr,i,i+size-1,Math.min(i+size+size-1,N-1)); } } }
对于自顶向下的充分的利用了数组检索特性,对于自底向上的则没有利用数组位置检索则对于底层为链表结构的排序速度更快。
优化点:
对于归并算法还可以进行优化,可以嵌套其他的排序算法使性能更好;还可以加入是否需要merge的判断
/** * 对归并排序进行优化: * 1:对于小规模数组使用插入排序 * 2:对于对于arr[mid] <= arr[mid+1]的情况,不进行merge,这样做对于近乎有序的数组非常有效,但是对于一般情况有一定的性能损失 */
public static void mergeSort2(Comparable[] arr,int left,int r){ //优化点1:对于小规模数组使用插入排序 if (r - left <= 15){ //没有写这种类型的插入排序 //InsertionSort.sort(arr,left,r); return; } int mid = left+(r-left)/2; mergeSort2(arr,left,mid); mergeSort2(arr,mid+1,r); //优化点2:不再直接merge,而是要先判断一下 if (arr[mid].compareTo(arr[mid+1]) > 0){ merge(arr,left,mid,r); } }
注:有一个方法是原地归并,这个算法是提高了时间复杂度来降低空间复杂度,这个方法可以不用太考虑。
6 快速排序
算法思想:
快速排序则是在归并的基础上进行了改进:简单的粗暴的平均分成两份-->选取一个基准,分成两份。不断的把份数缩小,这样我只需要有一个想好如何拆分就可以了,不用再考虑拆完后的归并了。
一开始设定一个元素为v,进行比较,对于元素的移动采用的是双指针交换完成的。
切分操作:
j指向的是小于v的最后一个元素

交换时则是把大于v的第一个元素与待交换的元素进行交换的。
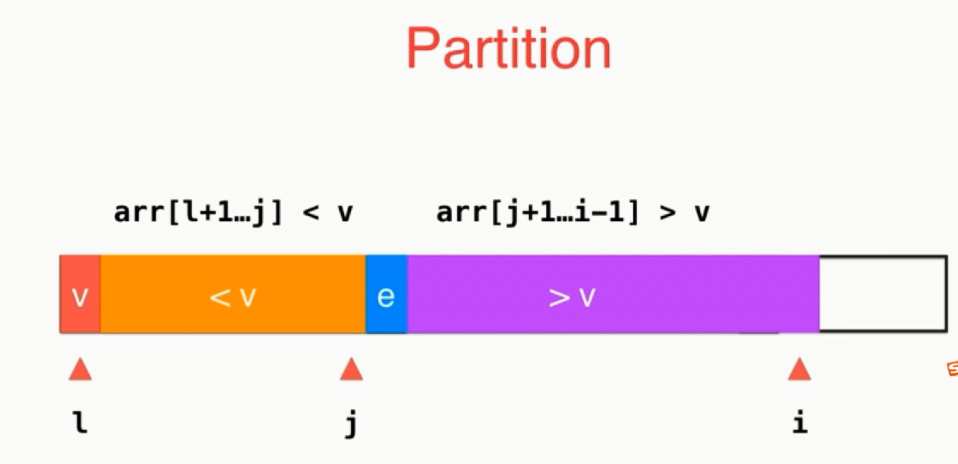
当遍历完成后需要交换v与j的位置。
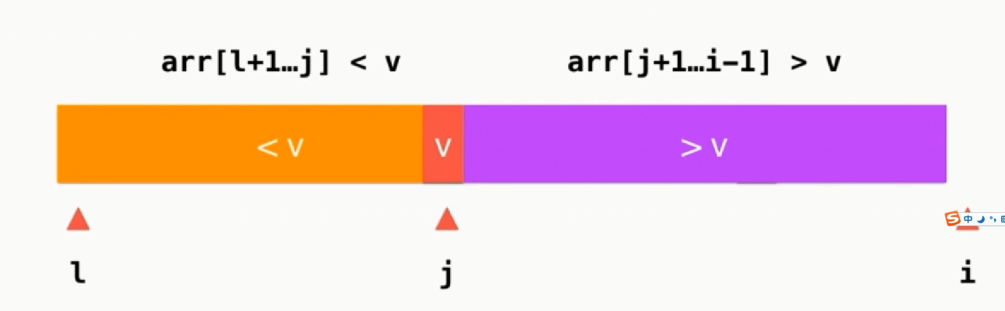
代码实现:
public static void sort(Comparable[] arr){ if (arr == null || arr.length <= 1){ return; } sort(arr,0,arr.length-1); } // 对arr[left...r]部分进行partition操作 // 返回p, 使得arr[left...p-1] < arr[p] ; arr[p+1...r] >= arr[p] private static int partition(Comparable[] arr,int left,int r){ Comparable v = arr[left]; int j = left; for (int i = left+1; i <= r; i++) { if (arr[i].compareTo(v) < 0){ //应该与大于等于v的第一个元素交换位置 j++; swap(arr,j,i); } } //把基准元素放中间 swap(arr,left,j); return j; } //使用分治的方法进行拆分 private static void sort(Comparable[] arr, int left, int r) { if (left >= r){ return; } int p = partition(arr,left,r); //p其实已经有序了,不用再考虑了 sort(arr,left,p-1); sort(arr,p+1,r); }
快速排序也是可以优化的,首先每次使用数组中的第一个元素,当整个数组基本上有序时那么快速排序耗时非常大。其次还可以根据前面的优化方法采用将几个排序算法融合在一起的思想,比如当数据量少时选择插入排序算法
1. 对小规模数据使用插入排序
//优化:当数据量小时使用插入排序 private static void sort2(Comparable[] arr, int left, int r) { // 对于小规模数组, 使用插入排序 if( r - left <= 15 ){ InsertionSort.sort(arr, left, r); return; } int p = partition(arr,left,r); //p其实已经有序了,不用再考虑了 sort2(arr,left,p-1); sort2(arr,p+1,r); }
2.使用随机数值进行作为标定点
//优化:选取一个随机值作为标定点 private static void sort3(Comparable[] arr, int left, int r) { if (left >= r){ return; } //把首元素随机的和其他元素进行交换 swap(arr,left,(int)(Math.random()*(r-left+1))+left); int p = partition(arr,left,r); //p其实已经有序了,不用再考虑了 sort3(arr,left,p-1); sort3(arr,p+1,r); }
双路快排:
当数组中有大量的重复元素时,再次采用上面部分的算法,整个的拆分就变得极度不平衡,那么就会退化成O(n^2)级别的算法,图示如下:

为了解决上述问题需要换一种思路解决:之前是在数组的一端放置大于v和小于v的元素,现在分别放置在数组的两端,i与j分别从两端进行扫描

如果i遇到的元素时小于v的便继续前进直至遇到是大于等于v的,同理也使用于j索引
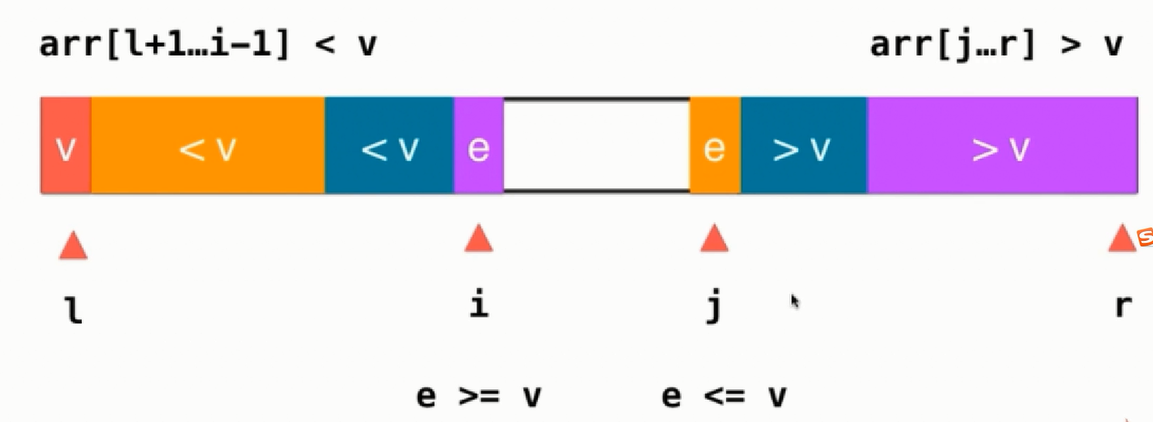
然后把i、j索引交换位置,即可
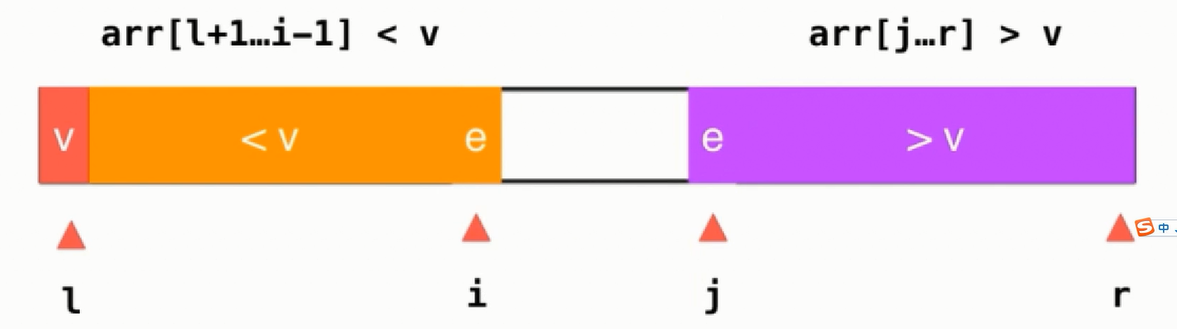
然后继续移动i与j直至两个指针相遇,那么最后表示的元素如下:
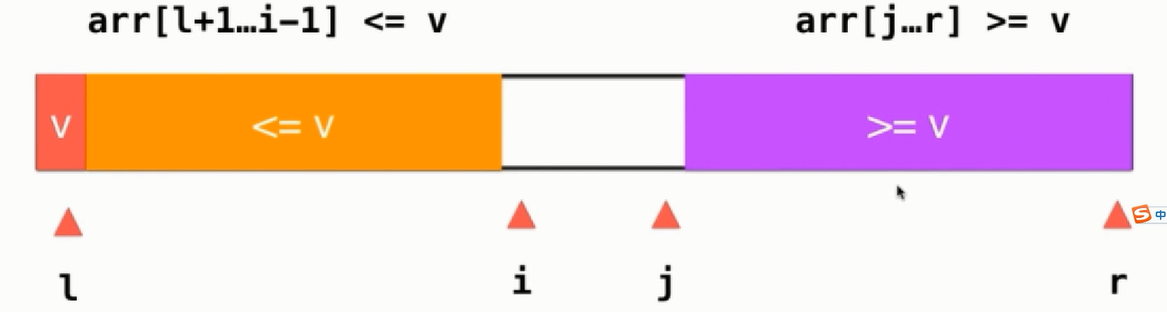
根据上面的判断条件,即使i与j指向的元素都与v相等,也会进行交换,这样其实是把等于v的元素分散到了两部分中,这样便可以避免大量重复元素等于v时造成拆分不平衡的情况。
代码实现:
//双路排序的拆分 private static int partition2(Comparable[] arr,int left,int r){ Comparable v = arr[left]; int i = left+1,j = r; while (true){ //这里有一个地方要注意的就是不要添加等号,以为加上等号就可以少交换一次,但正是因为少交换了一次,就可能会造成拆分的不平衡 //这样做的后果是效率反而低了 while (i <= r && arr[i].compareTo(v) < 0){ i++; } while (j > left && arr[j].compareTo(v) > 0){ j--; } if (i > j){ break; } //交换i与j位置处的元素值 swap(arr,i,j); i++; j--; } //把基准元素放入合适的位置 swap(arr,left,j); return j; }
三路快排:
三路排序是把数组分为三部分:小于v、等于v、大于v部分如下图所示:
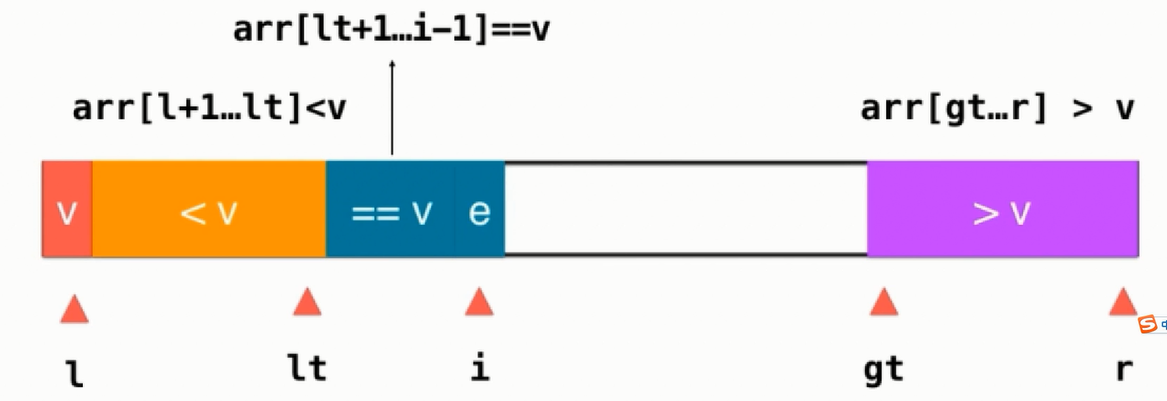
对于i处的元素则有大于、等于、小于三种情况考虑,当为等于v时,直接把元素纳入等于v的部分,并把i++即可。
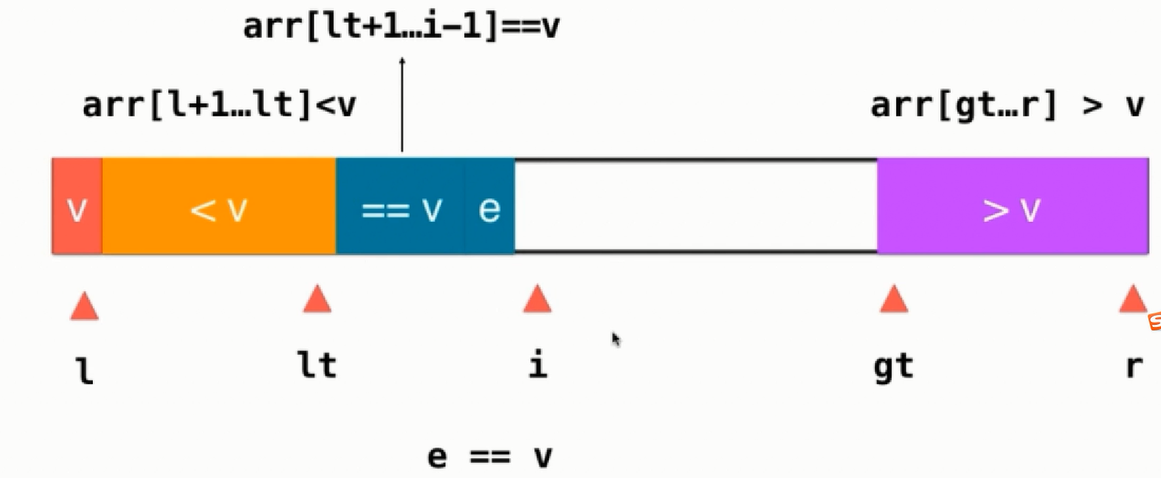
当i处的元素小于v时则把该元素与等于v的第一个元素交换即可,然后维护下lt和i索引即可:

当大于v时,则需要和索引为gt-1处的元素交换,然后维护gt索引,此时不要让i索引自增:

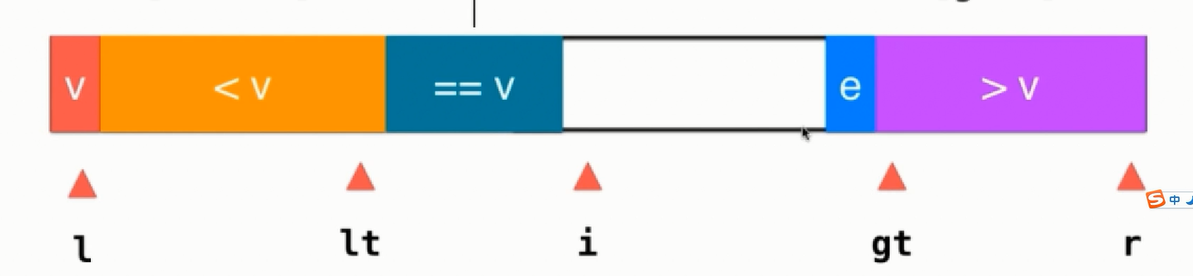
当遍历完数组后最终的情况如下图所示,当i与gt重合时便终止了

终止后还有一步操作即交换v的位置,只需要把v与lt的位置交换即可,最终如下图所示:
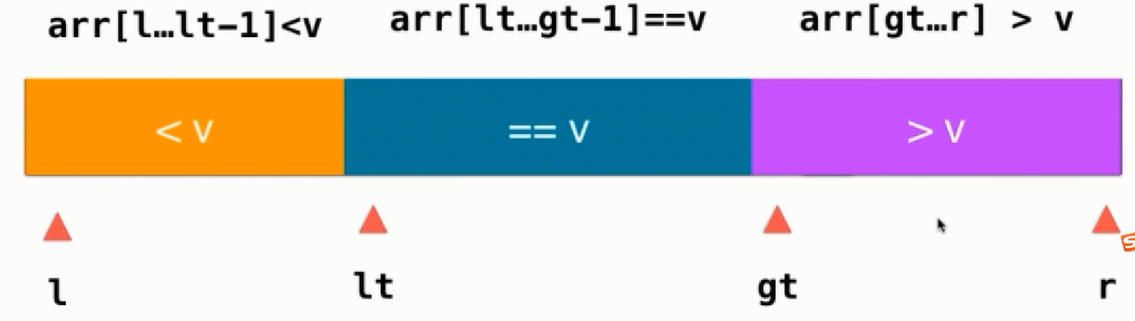
代码实现:
让这个l固定不动,就要一数剧的初始值设置的复杂,这里可以借用上面的的图理解,给出算法一书中的参考代码:
private static void partition3(Comparable[] arr,int left,int r){ if(r <= left){ return; } Comparable v = arr[left]; //arr[left+1...lt-1] < v arr[lt...i) == v arr[gt...r] > v int lt = left,i = left+1,gt = r; while (i <= gt){ int cmp = arr[i].compareTo(v); if (cmp < 0){ swap(arr,lt++,i++); }else if (cmp > 0){ //因为gt位置处的值并不确定,因此换过来后i的值不自增,需要再对i处的值判断一次 swap(arr,i,gt--); }else { i++; } } partition3(arr,left,lt-1); partition3(arr,gt+1,r); }
上面的代码和图例,其思路是一样的,只不过区间设置的不同而已,当有大量重复的v时也不用频繁的交换,降低了时间复杂度。下面给出对照图中演示的代码:
//主方法 public static void sort(Comparable[] arr){ int n = arr.length; sort(arr, 0, n-1); } //对于三路排序,中间的v值将会是一个区间,这样在返回值时不容易返回,因此不再单独对拆分做一个函数,而是使用递归 private static void sort(Comparable[] arr, int left, int r) { //对于小规模数组使用插入排序 if (r - left <= 15){ InsertionSort.sort(arr,left,r); return;+ } // 后面的就是partition部分 // 随机在arr[left...r]的范围中, 选择一个数值作为标定点pivot swap( arr, left, (int)(Math.random()*(r-left+1)) + left); Comparable v = arr[left]; int lt = left; // 初始为空的 arr[left+1...lt] < v int gt = r + 1; // 初始为空的 arr[gt...r] > v int i = left +1; // 初始为空的 arr[lt+1...i) == v while (i < gt){ if (arr[i].compareTo(v) < 0){ swap(arr,i,lt+1); i++; lt++; }else if (arr[i].compareTo(v) > 0){ swap(arr,i,gt-1); gt--; }else { //相等时的情况 i++; } } swap( arr, left, lt ); //递归对两部分进行排序 sort(arr, left, lt-1); sort(arr, gt, r); }
小结:
1.对于快速排序的理解,不要纠结于一开始的初始位置如何,而是先认为已经排成了一个区间后,再去分析。
2.虽然快速排序和归并排序都是O(nlogn)级别的算法,但是相对而言快速排序还是比较快一点的。归并排序和快速排序都应用了分治算法的思想:将原问题分解为多个小问题,最后小问题解决了原问题也就解决了。
7 堆排序
关于堆的介绍可以参考博客:https://i-beta.cnblogs.com/posts/edit;postId=12101145
从上面的堆的构造中可以发现,最大堆或最小堆当取出后的元素就是按照从大到小排列的,这样就相当于排序了,考虑算法如下:
// 对整个arr数组使用堆排序 // 将所有的元素依次添加到堆中, 在将所有元素从堆中依次取出来, 即完成了排序 // 无论是创建堆的过程, 还是从堆中依次取出元素的过程, 时间复杂度均为O(nlogn),因此整个堆排序的整体时间复杂度为O(nlogn) public static void sort(Comparable[] arr){ int n = arr.length; MaxHeap<Comparable> maxHeap = new MaxHeap<Comparable>(n); for( int i = 0 ; i < n ; i ++ ){ maxHeap.insert(arr[i]); } // 依次取出根节点元素,即按照从大到小的顺序排列 for( int i = n-1 ; i >= 0 ; i -- ){ arr[i] = maxHeap.extractMax(); } }
原地堆排序:
在前面的是借用了另外一个数组data 进行heapify过程生成了一个最大堆,但对于数组而言还是无序的,那么如何将数组安装从递增的顺序排序?将一个数组进行hepify过程其结果如下图所示,那么数组中的第一个元素应该是最大的元素,那么就应该和数组中最后一个元素交换即v和w应互换。

当交换后,v便是在正确的位置上了,但是因为和w交换了所以前面已经不再是最大堆了

那么对w继续进行下沉操作前面的那么橙色部分就会又变成一个最大堆,那么可以继续进行上面的操作,即把剩下的最大堆中的首元素v和w交换位置。

因为在数组中一般都是从0开始索引的,前面一直考虑的都是从1开始的索引,这里给出从0开始的索引性质:
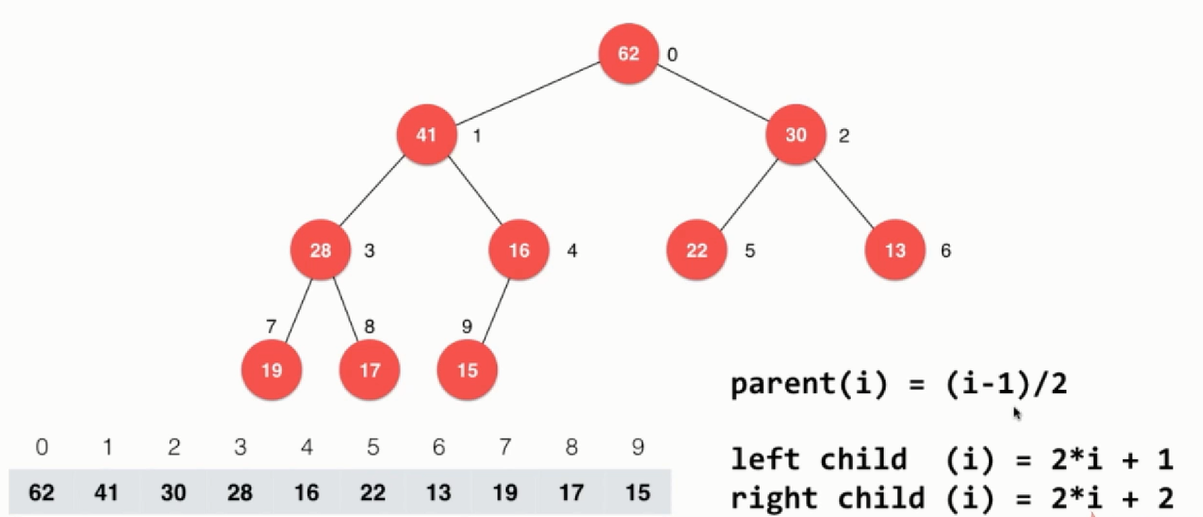
那么此时非叶子节点的索引为:(count - 1)/2,对于整个部分代码如下:
public static void sort(Comparable[] arr){ int n = arr.length; // 注意,此时我们的堆是从0开始索引的,从(最后一个元素的索引-1)/2开始,最后一个元素的索引 = n-1,在算法一书中给的示例代码堆索引是从1开始的 // 第一个非叶子节点的序号为(n-1)/2 for( int i = (n-1)/2 ; i >= 0 ; i -- ){ shiftDown(arr, n, i); } // 进行交换把数组中的首元素和最后一个元素交换 for( int i = n-1; i > 0 ; i-- ){ swap( arr, 0, i); shiftDown(arr, i, 0); } }
注:目前比较认可的堆排序就是原地堆排序
8 索引堆
前面讲的基于数组的堆其本质就是改变了元素的索引号,虽然仍然是一个数组但是可以看作是一个堆。但是当存的不再是元素而是字符串,或者字符串特别长时那么整个交换操作就会特别浪费时间这一就会导致性能的下降。更为重要的一点是无法降索引序号和数据建立起关系,比如索引为7的数据其实在建立堆的过程中是在变化的,假设这个索引就是数据的id值,这样构建堆肯定是不合适的。
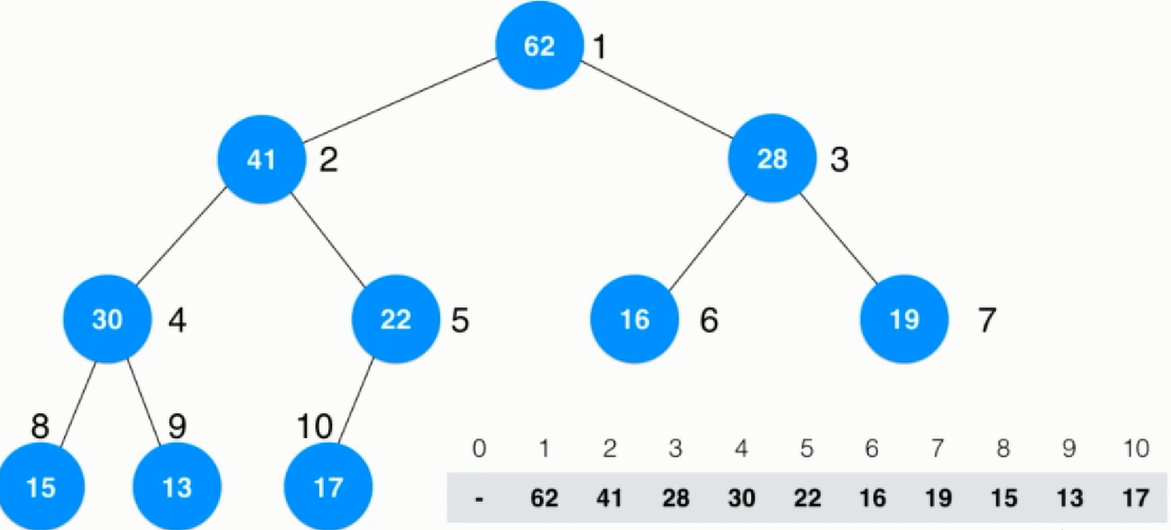
为了解决前面提到的问题,提出了索引堆,在为交换前索引堆如下所示:
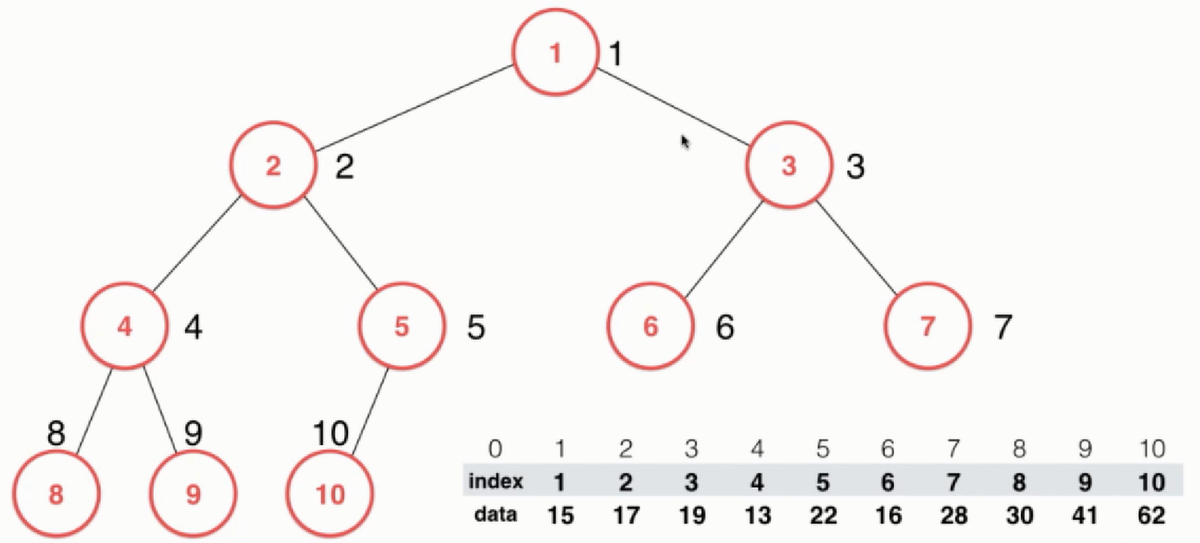
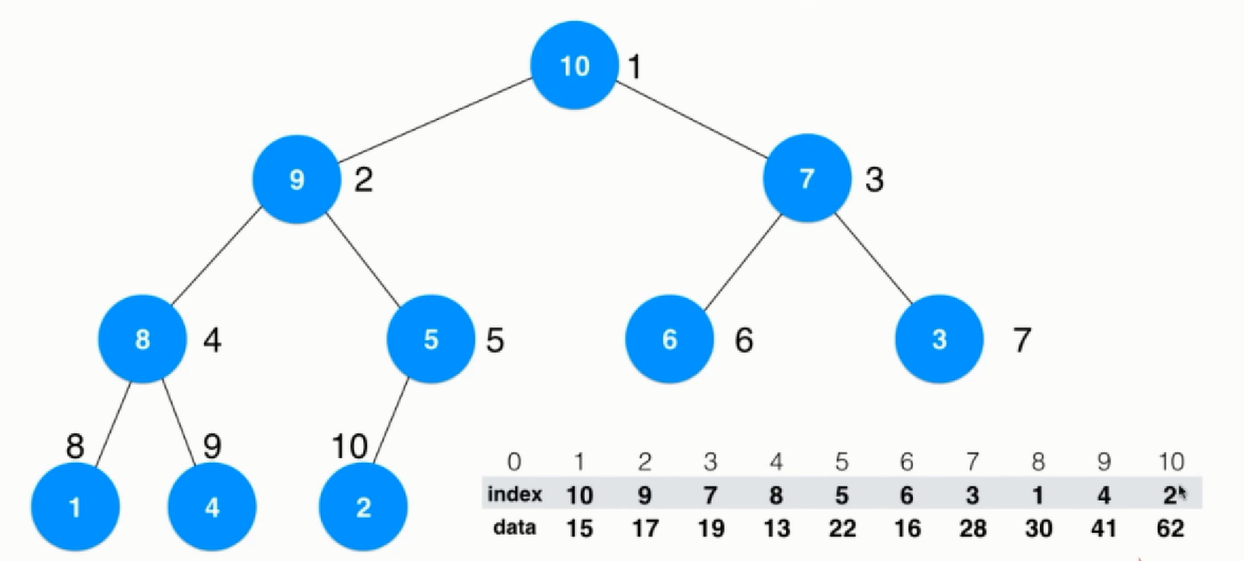
在交换中比较的还是data数据不过在堆中保存的却是索引,这样相当于data的内容没有发生变化,只是index发生了变化。这样比如想改变系统进程为7的数据,便可以直接根据最上面的序号找到数据28进行修改了。
因为在算法一书中并未对索引堆有过多的介绍,因此这里先空着。
计数排序
算法思想:
把数组元素作为数组的下标,然后用一个临时数组统计元素出现的次数,然后再把临时数组统计的数据从小到大汇总起来,此时汇总起来是数据是有序的。因为额外数组的大小是由原数组中最大值和最小值的差决定的,因此计数排序只适用于元素值较为集中的情况,若集合中存在最大最小元素值相差甚远的情况,则计数排序开销较大、性能较差。
代码实现:
public static void sort(Integer[] arr){ if (arr == null || arr.length < 2){ return; } int N = arr.length; // 获取最大值,最小值 int min = arr[0],max = arr[0]; for (int i = 1; i < N; i++) { if (arr[i] < min){ min = arr[i]; } if (arr[i] > max){ max = arr[i]; } } int[] aux = new int[max-min+1];//遍历原数组,把数字出现的次数存入辅助数组中 for (int i = 0; i < N; i++) { aux[arr[i]-min]++; } int index = 0,i = 0; while (index < N && i < aux.length ){ if (aux[i] != 0){ arr[index++] = i+min; //每存入一次,次数便减1 aux[i]--; }else { i++; } } }
优化点:
上面的排序算法是有很大的缺陷,比如举出一个实际例子:考试成绩排序,遇到相同分数的则按照原表格中的顺序排序。按照上面的排序算法是无法做到的,因为我们只知道有两个95的,具体谁在前,谁在后并没有记录。
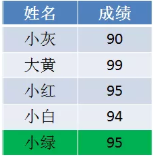
优化方法:
在计数数组中,记录的次数的时候需要再加上前面的次数,这样其实就相当于把顺序记录下来了。

然后遍历原数组,开辟一个新数组用来保存存放的结果,依据次数和原数组的大小,把其存放在对应的位置。因为次数代表排名,次数是递减的,所以原数组的遍历是应该是倒序遍历的。
注:主要参考了程序员小灰的博客,但是在测试时发现这篇博客中给出的代码是有问题的,因为面试的时候计数、桶、基数排序不是重点因此这里的代码先放一放,后面有时间了再加上。
不足:计数排序对于double类型的数据是无能为力的,对于这一点的改进,引出了桶排序。
桶排序
算法思想:
因为小数无法和下标对于,因此引入桶的概念(本质就是一个小数组),每个桶中装载一定的区间范围的数据,这个范围怎么确定方式有很多种。给出一种思路:最后一个桶只包含最大值,其余个桶的区间按照比例确定。
区间跨度 = (最大值-最小值)/ (桶的数量 - 1)

然后把原始数据放入对应放入每个桶中,每个桶的内部再进行排序(每个桶的内部既可以递归使用桶排序也可以使用其他排序算法)
基数排序
算法思想:
先以个位数的大小来对数据进行排序,接着以十位数的大小来多数进行排序,接着以百位数的大小一直持续下去。对于某一位的排序则是采用的桶排序的思路,由于某一位数的大小范围为0-9,所以我们需要10个桶,然后把具有相同数值的数放进同一个桶里,之后再把桶里的数按照0号桶到9号桶的顺序取出来,这样一趟下来,按照某位数的排序就完成了。
对于这个可以参考:https://zhuanlan.zhihu.com/p/57088609
9 排序算法总结
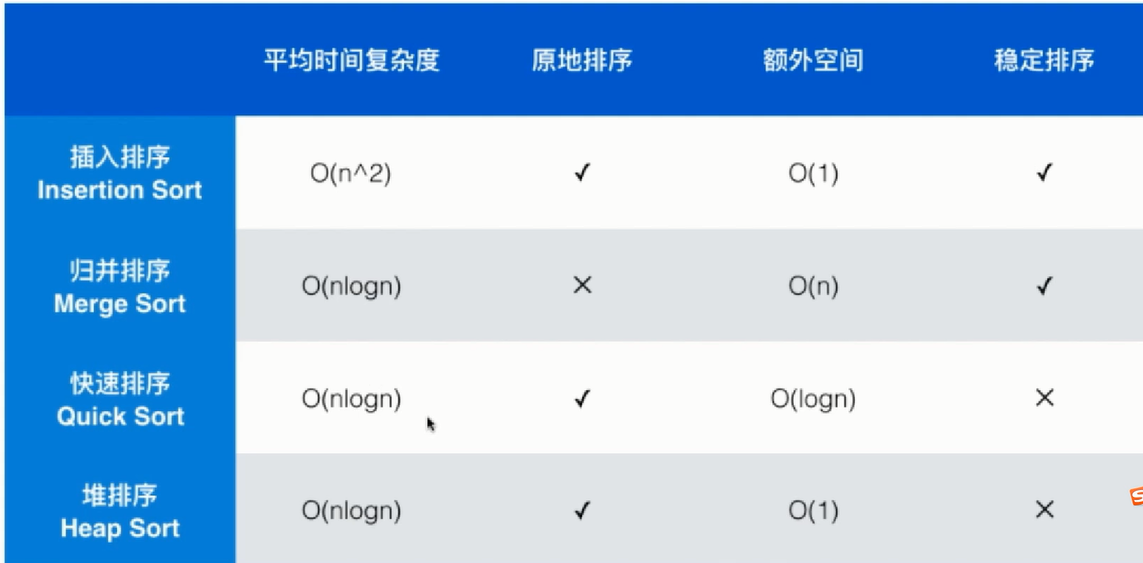
目前还不存在一种时间复杂度为O(nlogn),原地排序,空间复杂度为O(1),并且是稳定的排序算法。
此处的排序算法并未总结完,只是一些比较经典的算法,还有在特定题目中的一些排序算法如:计数排序,桶排序等在此处并未作总结,可以后面添加上。
0