ElasticSearch 前传
网上流传的故事是:多年前,一个叫作 Shay Banon 的刚结婚不久的失业开发者,由于妻子要去伦敦学习厨师,他便跟着也去了。在他找工作的过程中,为了给妻子构建一个食谱的搜索引擎,他开始构建一个早期版本的 Lucene。
直接基于 Lucene 工作会比较困难,所以 Shay 开始抽象 Lucene 代码以便 Java 程序员可以在应用中添加搜索功能。他发布了第一个开源项目,叫作“Compass”。
后来 Shay 找到一份工作,这份工作处在高性能和内存数据网格的分布式环境中,因此高性能的、实时的、分布式的搜索引擎也是理所当然需要的。然后他决定重写 Compass 库使其成为一个独立的服务叫作 Elasticsearch。
第一个公开版本发布于 2010 年 2 月
2017 年 3 月发布 ElasticSearch5.5
2020 年 11 月发布 ElasticSearch7.10。
ElasticSearch 简介
Elasticsearch(ES)是一个基于 Lucene 构建的开源、分布式、RESTful 接口全文搜索引擎,是目前全球最受欢迎的全文搜索引擎。
Elasticsearch 的优点
横向可扩展性:只需要增加一台服务器,做一点儿配置,启动一下 Elasticsearch 进程就可以并入集群。
分片机制提供更好的分布性:同一个索引分成多个分片(sharding),这点类似于 HDFS 的块机制;分而治之的方式可提升处理效率。
高可用:提供复制(replica)机制,一个分片可以设置多个复制,使得某台服务器在宕机的情况下,集群仍旧可以照常运行,并会把服务器宕机丢失的数据信息复制恢复到其他可用节点上。
使用简单:只需一条命令就可以下载文件,然后很快就能搭建一个站内搜索引擎。
什么是全文搜索?
全文搜索是指计算机搜索程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,搜索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户。
这个过程类似于通过字典中的搜索字表查字的过程,Lucene 是目前全球使用最广的全文搜索引擎开源库。
Lucene 介绍
Lucene 是 Apache 软件基金会中一个开放源代码的全文搜索引擎工具包,是一个全文搜索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。
Lucene 的目的是为软件开发人员提供一个简单易用的工具包,以方便在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文搜索引擎。
说到底,Lucene 就是一个 jar 包。
Lucene 倒排索引
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。
由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。
搜索引擎的关键步骤就是建立倒排索引,倒排索引一般表示为一个关键词,然后是它的频度(出现的次数)、位置(出现在哪一篇文章或网页中,及有关的日期,作者等信息)
倒排索引示例
Lucene 使用的是倒排文件索引结构,下面用例子介绍该结构及相应的生成算法。
假设有两篇文章 1 和文章 2。
文章 1 的内容为:Tom lives in Guangzhou,I live inGuangzhou too.
文章 2 的内容为:He once lived in Shanghai.
1.取得关键词
由于Lucene是基于关键词索引和查询的,首先我们要取得这两篇文章的关键词。
在 Lucene 中获取关键字由 Analyzer 类完成。经过上面处理后,得到如下结果:
文章 1 的所有关键词为:[tom] [live] [guangzhou] [i] [live][guangzhou]
文章 2 的所有关键词为:[he] [live] [shanghai]
2.建立倒排索引
上面的对应关系是:“文章号”对“文章中所有关键词”。倒排索引把这个关系倒过来,变成:“关键词”对“拥有该关键词的所有文章号”,再加上“出现频率”和“出现位置”信息。
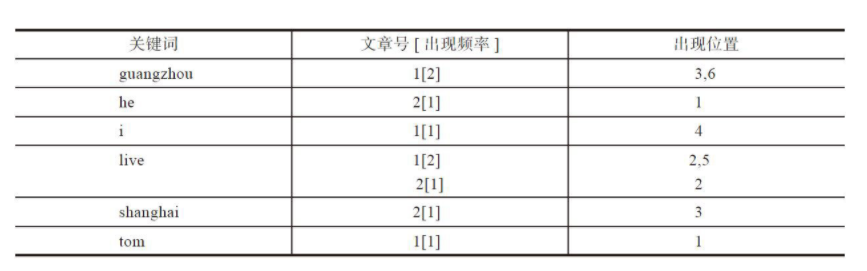
以 live 这行为例,我们说明一下该结构:live 在文章 1 中出现了 2 次,那么“2,5”就表示 live 在文章 1 中出现的两个位置;在文章 2 中出现了一次,剩下的“2”就表示 live 是文章 2 中的第 2 个关键字。
以上就是 Lucene 索引结构中最核心的部分。我们注意到关键字是按字符顺序排列的,因此 Lucene 可以用二元搜索算法快速定位关键词。
每天学习一点点,每天进步一点点。