Python3高阶函数之迭代器、装饰器
列表生成式
推导式就是构建比较有规律的列表,生成器.
孩子,我现在有个需求,看列表[0, 1, 2, 3, 4, 5, 6, 7, 8, 9],我要求你把列表里的每个值加1,你怎么实现?你可能会想到2种方式
屌丝青年版
a=[0,1,2,3,4,5,6,7,8,9]
b=[]
for i in a:b.append(i+1)
print(b)
print(a)
# 输出结果为
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
普通青年版
a=[0,1,2,3,4,5,6,7,8,9]
a = map(lambda x: x + 1, a)
print(a)
for i in a:print(i,end="")
# 输出结果为
<map object at 0x00B78910>
12345678910
装b青年版
a=[0,1,2,3,4,5,6,7,8,9]
a=[i+1 for i in range(10)]
print(a)
# 输出结果为
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 这就叫做列表生成式
生成器
初始生成器
什么是生成器?这个概念比较模糊,各种文献都有不同的理解,但是核心基本相同。生成器的本质就是迭代器,在python社区中,大多数时候都把迭代器和生成器是做同一个概念。不是相同么?为什么还要创建生成器?生成器和迭代器也有不同,唯一的不同就是:迭代器都是Python给你提供的已经写好的工具或者通过数据转化得来的,(比如文件句柄,iter([1,2,3])。生成器是需要我们自己用python代码构建的工具。最大的区别也就如此了。
生成器的构建方式
在python中三种方式来创建生成器:
# 1. 通过生成器函数
# 2. 通过生成器推导式
# 3. Python内置函数或者模块提供(其实1,3)
生成器函数
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
要创建一个generator,有很多种方法,第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator:
def gen_func():
for i in range(1,5001):
yield f'{i}个包子'
ret = gen_func()
for i in range(200):
print(next(ret))
# yield from
def func1():
li1 = [1,2,3,4,5]
yield from li1 # 将li1列表变成迭代器返回
ret = func1()
print(next(ret))
print(next(ret))
print(next(ret))
生成器不但可以作用于for循环,还可以被
next()函数不断调用并返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值了。
同上面一样,可以使用isinstance()判断一个对象是否是Iterator对象:
生成器都是Iterator对象,但list,dict,str虽然是Iterable,却不是Iterator,把
list、dict、str等Iterable变成Iterator可以使用iter()函数:
你可能会问,为什么
list、dict、str等数据类型不是Iterator?
这是因为Python的
Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
小结
凡是可作用于for循环的对象都是Iterable类型.
凡是可作用于next()函数的对象都是Iterator类型,他们表示是一个惰性计算的序列:
集合数据类型如list,dict,str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
python的for循环本质就是用过不断调用next()函数实现的,例如:
for x in [1,2,3,4,5]:
pass
等价于
# 首先获得Iterator对象:
it = iter([1, 2, 3, 4, 5])
# 循环:
while True:
try:
# 获得下一个值:
x = next(it)
except StopIteration:
# 遇到StopIteration就退出循环
break
迭代器
可迭代对象定义
对于迭代器来说,我们更熟悉的应该是可迭代对象,之前无论是源码还是讲课中或多或少我们提到过可迭代对象这个词。之前为了便于大家理解可迭代对象,可能解释的不是很正确,所以今天我们正式的聊一聊什么是可迭代对象。从字面意思来说,我们先对其进行拆解:什么是对象?Python中一切皆对象,之前我们讲过的一个变量,一个列表,一个字符串,文件句柄,函数名等等都可称作一个对象,其实一个对象就是一个实例,就是一个实实在在的东西。那么什么叫迭代?其实我们在日常生活中经常遇到迭代这个词儿,更新迭代等等,迭代就是一个重复的过程,但是不能是单纯的重复(如果只是单纯的重复那么他与循环没有什么区别)每次重复都是基于上一次的结果而来。比如你爹生你,你生你爹,哦不对,你生你儿子,你儿子生你孙子等等,每一代都是不一样的;还有你使用过得app,微信,抖音等,隔一段时间就会基于上一次做一些更新,那么这就是迭代。可迭代对象从字面意思来说就是一个可以重复取值的实实在在的东西。
我们之前接触的可迭代对象有哪些?
str list tuple dic set range 文件句柄等, 那么int,bool 这些为什么不能称为可迭代对象尼? 虽然在字面意思这些看着不符合,但是我们要有一定的判断标准或者规则去判断该对象是不是可迭代对象.
在python中,但凡内部含有__iter__方法的对象,都是可迭代对象
查看对象内部方法
我们可以通过dir()去判断一个对象具有什么方法
s1 = 'youmen'
print(dir(s1))
# 判断python中的一个对象是不是可迭代对象
print('__iter__' in dir(s1))
True
小结
从字面意思来说: 可迭代对象就是一个可以重复取值的实实在在的东西
从专业角度来首: 但凡内部含有'iter'方法的对象,都是可迭代对象
可迭代对象可以通过判断该对象是否有'iter'方法来判断
可迭代对象优点
可以直观的查看里面的数据
可迭代对象的缺点
- 占用内存
- 不能直接通过for循环,不能直接取值(索引,key)
那么这个缺点有人就提出质疑了,即使抛去索引,key以外,这些我可以通过for循环进行取值呀!对,他们都可以通过for循环进行取值,其实for循环在底层做了一个小小的转化,就是先将可迭代对象转化成迭代器,然后在进行取值的。
迭代器定义
从字面意思来说迭代器,是一个可以迭代取值的工具, 器: 在这里当做工具比较合适
从专业角度来说:迭代器是这样的对象:实现了无参数的__next__方法,返回序列中的下一个元素,如果没有元素了,那么抛出StopIteration异常.python中的迭代器还实现了__iter__方法,因此迭代器也可以迭代。 出自《流畅的python》
那么对于上面的解释有一些超前,和难以理解,不用过于纠结,我们简单来说:在python中,内部含有'Iter'方法并且含有'next'方法的对象就是迭代器。
判断该对象是否是迭代器
# 迭代器定义
# 字面意思: 更新迭代,器: 工具,可更新迭代的工具
# 专业角度: 内部含有"__iter__"方法并且含有"__next__"方法的对象就是迭代器
# 可以判断是否是迭代器: "__iter__" and "__next__" 在不在dir(对象)
with open('文件1',encoding='utf-8',mode='w') as f1:
print('__iter__' and '__next__' in dir(f1))
可迭代对象转换为迭代器
l1 = [1,2,3,4,5]
obj = iter(l1) # l1.__iter__()
print(next(obj))
# 列表迭代器取值, 一个next取对应的一个值,如果迭代器里面的值取完了,还要Next,就会报StopIteration的错误
print(next(obj))
print(obj)
# 1
# 2
# <list_iterator object at 0x000001BA17A2C400>
while模拟for的内部循环机制(面试)
l2 = [1,2,3,4,5]
obj=iter(l2)
for i in range(5):
print(next(obj))
l1 = [1,2,3,4,5]
obj = iter(l1)
while 1:
# 利用异常处理终止循环
try:
print(next(obj))
except StopIteration:
break
迭代器小结
# 迭代器定义
# 字面意思: 更新迭代,器: 工具,可更新迭代的工具
# 专业角度: 内部含有"__iter__"方法并且含有"__next__"方法的对象就是迭代器
# 可以判断是否是迭代器: "__iter__" and "__next__" 在不在dir(对象)
# 优点
# 1. 节省内存,(迭代器,迭代器在内存中相当于只占一个数据的空间;因为每次取值都上一条数据会在内存释放,加载当前的此条数据, 几百万个对象,8G内存可以承受的)
# 2. 惰性机制,(next一次就取一个值,绝不过多取值)
# 有一个迭代器模式可以很好的解释上面这两条: 迭代是数据处理的基石,扫描内存中放不下的数据时,我们要找到一种惰性获取数据的方式,即按需获取一个数据项,这就是迭代器模式.
# 缺点
# 1. 速度慢,不能直观的查看里面的数据
# 2. 不走回头路,只有全部取完才能取原来的值
可迭代对象与迭代器的对比
可迭代对象:
# 可迭代对象是一个操作方法比较多(比如列表,字典的增删改查,字符串的常用方法等), 比较直观,但是占用内存,而且不能直接通过循环迭代取值的一个数据集.
# 应用:
# 当你侧重于数据可以灵活处理,并且内存空间足够,将数据设置为可迭代对象是明确的选择.
迭代器
# 当你侧重于对于数据可以灵活处理,并且内存空间足够,将数据集设置为可迭代对象是明确的选择
# 是一个非常节省内存,可以记录值位置,可以直接通过循环+next方法取值,但是不直观,操作方法比较单一的数据集.
# 应用:
# 当你的数据量过大,大到足以撑爆你的内存或者你节省内存的首选因素时,将数据集设置为迭代器是一个不错的选择.
闭包
# 闭包定义
# 内层函数对外层函数非全局变量的引用(使用),就会形成闭包
# 闭包现象
# 被引用的非全局变量也称作自由变量,这个自由变量会与内层函数产生一个绑定关系.
# 自由变量不会再内存中消失
# 闭包的作用:
# 保存局部信息不被销毁,保证数据的安全性
# 闭包的应用
# 1. 可以保存一些非全局变量但是不易被销毁,改变的数据
# 2. 装饰器
def make_averager():
series = []
def averager(new_value):
series.append(new_value)
total = sum(series)
return total/len(series)
return averager
avg = make_averager()
print(avg(100))
print(avg(110))
print(avg(120))
装饰器
# 装饰器定义:
# 再不改变原被装饰的函数的源代码以及调用方式下,为其添加额外的功能.
初识装饰器
Example1
需求介绍: 你现在在xx科技有限公司的开发部分任职,领导给你一个业务需求让你完成,让你写代码测试小明同学写的代码执行效率
def index():
print("欢饮访问博客园主页")
版本一
import time
print(time.time())
# 此方法返回的是格林尼治时间,是此时此刻距离1970年1月1日0点0分0秒的时间秒数。也叫时间戳,他是一直变化的。所以要是计算shopping_car的执行效率就是在执行前后计算这个时间戳的时间,然后求差值即可。
def index():
time.sleep(1) # 模拟一下网络延迟以及代码的效率
print("欢饮访问博客园主页")
start_time = time.time()
index()
end_tiem = time.time()
print(f'此函数的执行效率是{end_tiem-start_time}')
版本一分析
# 虽然完成了需求,但是完成的是一个测试其他函数的执行效率的功能,如果让你测试一下其他人员的函数效率?我还全得复制,重复代码太多,我们可以用函数,函数就是以功能为导向,减少重复代码,好我们继续整改.
版本二
def index():
time.sleep(1)
print("欢饮访问博客园主页")
def home(name):
time.sleep(2)
print(f'欢迎访问{name}主页')
def inner(func):
start_time = time.time()
func()
end_tiem = time.time()
print(f'此函数的执行效率是{end_tiem - start_time}')
inner(index)
# 这样我将index函数的函数名作为参数传递给inner函数,然后再inner函数里面执行index函数,这样就动态传参了,但是执行方式改变了,不符合封闭原则
版本三
# 将原函数的调用方式不改变
def index():
time.sleep(1)
print("欢饮访问博客园主页")
def home(name):
time.sleep(2)
print(f'欢迎访问{name}主页')
def timmer(func):
def inner():
start_time = time.time()
func()
end_tiem = time.time()
print(f'此函数的执行效率是{end_tiem - start_time}')
return inner
index = timmer(index)
index()
# 版本三就是最简单的一个装饰器,在不改变原函数的源码以及调用方式的前提下,为其增加额外的功能,测试执行效率
# 装饰器一定要在代码的最上面
def timmer(func):
def inner():
start_time = time.time()
func()
end_tiem = time.time()
print(f'此函数的执行效率是{end_tiem - start_time}')
return inner
# 为了省略每次我们调用函数时候写index = timmer(index)可以使用下面这种方式
# @装饰器名, 语法糖
# @timmer = index = timer(index)
@timmer
def index():
time.sleep(1)
print("欢饮访问博客园主页")
@timmer
def home(name):
time.sleep(2)
print(f'欢迎访问{name}主页')
index()
带返回值的装饰器
def timmer(func):
def inner():
start_time = time.time()
result = func()
func()
end_tiem = time.time()
print(f'此函数的执行效率是{end_tiem - start_time}')
return result
return inner
@timmer
def index():
time.sleep(1)
return 6666
print("欢饮访问博客园主页")
@timmer
def home(name):
time.sleep(2)
print(f'欢迎访问{name}主页')
ret = index()
print(ret)
# 1588496241.6084275
# 此函数的执行效率是2.0007846355438232
# 6666
被装饰函数带参数的装饰器
def timmer(func):
def inner(*args,**kwargs):
start_time = time.time()
result = func(*args,**kwargs)
end_tiem = time.time()
print(f'此函数的执行效率是{end_tiem - start_time}')
return result
return inner
@timmer
def index(name):
time.sleep(1)
return 6666
print("欢饮访问博客园主页")
@timmer
def home(name):
time.sleep(2)
print(f'欢迎访问{name}主页')
# ret = index('幽梦')
# print(ret)
@timmer
def demo1(name,age):
time.sleep(0.5)
print(f'欢迎{age}岁{name}登录日记页面')
demo1('幽梦',18)
Example2
你是一家视频网站的后端开发工程师,你们网站有以下几个版块
def home():
print("---首页----")
def america():
print("----欧美专区----")
def japan():
print("----日韩专区----")
def henan():
print("----河南专区----")
视频刚上线初期,为了吸引用户,你们采取了免费政策,所有视频免费观看,迅速吸引了一大批用户,免费一段时间后,每天巨大的带宽费用公司承受不了了,所以准备对比较受欢迎的几个版块收费,其中包括“欧美” 和 “河南”专区,你拿到这个需求后,想了想,想收费得先让其进行用户认证,认证通过后,再判定这个用户是否是VIP付费会员就可以了,是VIP就让看,不是VIP就不让看就行了呗。 你觉得这个需求很是简单,因为要对多个版块进行认证,那应该把认证功能提取出来单独写个模块,然后每个版块里调用 就可以了,与是你轻轻的就实现了下面的功能 。
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
user_status = False # 用户登录了就把这个改成True
def login():
_username = "alice" # 假装这是DB里存的用户信息
_password = "123" # 假装这是DB里存的用户信息
global user_status
if user_status == False:
username = input("user:")
password = input("pasword:")
if username == _username and password == _password:
print("welcome login....")
user_status = True
else:
print("wrong username or password!")
else:
print("用户已登录,验证通过...")
def home():
print("---首页----")
def america():
login() # 执行前加上验证
print("----欧美专区----")
def japan():
print("----日韩专区----")
def henan():
login() # 执行前加上验证
print("----河南专区----")
home()
america()
henan()
此时你信心满满的把这个代码提交给你的TEAM LEADER审核,没成想,没过5分钟,代码就被打回来了, TEAM LEADER给你反馈是,我现在有很多模块需要加认证模块,你的代码虽然实现了功能,但是需要更改需要加认证的各个模块的代码,这直接违反了软件开发中的一个原则“开放-封闭”原则,简单来说,它规定已经实现的功能代码不允许被修改,但可以被扩展,即:
封闭:已实现的功能代码块是封闭的
开放:对现有功能的扩展开放
这个原则你还是第一次听说,我擦,再次感受了自己这个野生程序员与正规军的差距,BUT ANYWAY,老大要求的这个怎么实现呢?如何在不改原有功能代码的情况下加上认证功能呢?你一时想不出思路,只好带着这个问题回家继续憋,媳妇不在家,去隔壁老王家串门了,你正好落的清静,一不小心就想到了解决方案,不改源代码可以呀,
你师从沙河金角大王时,记得他教过你,高阶函数,就是把一个函数当做一个参数传给另外一个函数,当时大王说,有一天,你会用到它的,没想到这时这个知识点突然从脑子 里蹦出来了,我只需要写个认证方法,每次调用 需要验证的功能 时,直接 把这个功能 的函数名当做一个参数 传给 我的验证模块不就行了么,哈哈,机智如我,如是你啪啪啪改写了之前的代码
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
user_status = False # 用户登录了就把这个改成True
def login(func): # 把要执行的模块从这里传进来
_username = "alex" # 假装这是DB里存的用户信息
_password = "abc!23" # 假装这是DB里存的用户信息
global user_status
if user_status == False:
username = input("user:")
password = input("pasword:")
if username == _username and password == _password:
print("welcome login....")
user_status = True
else:
print("wrong username or password!")
if user_status == True:
func() # 看这里看这里,只要验证通过了,就调用相应功能
def home():
print("---首页----")
def america():
# login() #执行前加上验证
print("----欧美专区----")
def japan():
print("----日韩专区----")
def henan():
# login() #执行前加上验证
print("----河南专区----")
home()
login(america) #需要验证就调用 login,把需要验证的功能 当做一个参数传给login
# home()
# america()
login(henan)
你很开心,终于实现了老板的要求,不改变原功能代码的前提下,给功能加上了验证,此时,媳妇回来了,后面还跟着老王,你两家关系 非常 好,老王经常来串门,老王也是码农,你跟他分享了你写的代码,兴奋的等他看完 夸奖你NB,没成想,老王看后,并没有夸你,抱起你的儿子,笑笑说,你这个代码还是改改吧, 要不然会被开除的,WHAT? 会开除,明明实现了功能 呀, 老王讲,没错,你功能 是实现了,但是你又犯了一个大忌,什么大忌?
你改变了调用方式呀, 想一想,现在没每个需要认证的模块,都必须调用你的login()方法,并把自己的函数名传给你,人家之前可不是这么调用 的, 试想,如果 有100个模块需要认证,那这100个模块都得更改调用方式,这么多模块肯定不止是一个人写的,让每个人再去修改调用方式 才能加上认证,你会被骂死的。。。
你觉得老王说的对,但问题是,如何即不改变原功能代码,又不改变原有调用方式,还能加上认证呢? 你苦思了一会,还是想不出,老王在逗你的儿子玩,你说,老王呀,快给我点思路 ,实在想不出来,老王背对着你问,
老王:学过匿名函数没有?
你:学过学过,就是lambda嘛
老王:那lambda与正常函数的区别是什么?
你:最直接的区别是,正常函数定义时需要写名字,但lambda不需要
老王:没错,那lambda定好后,为了多次调用 ,可否也给它命个名?
你:可以呀,可以写成plus = lambda x:x+1类似这样,以后再调用plus就可以了,但这样不就失去了lambda的意义了,明明人家叫匿名函数呀,你起了名字有什么用呢?
老王:我不是要跟你讨论它的意义 ,我想通过这个让你明白一个事实
说着,老王拿起你儿子的画板,在上面写了以下代码:
def plus(n):
return n + 1
plus2 = lambda x: x + 1
老王: 上面这两种写法是不是代表 同样的意思?
你:是的
老王:我给lambda x:x+1 起了个名字叫plus2,是不是相当于def plus2(x) ?
你:我擦,你别说,还真是,但老王呀,你想说明什么呢?
老王: 没啥,只想告诉你,给函数赋值变量名就像def func_name 是一样的效果,如下面的plus(n)函数,你调用时可以用plus名,还可以再起个其它名字,如
calc = plus
calc(n)
你之前写的下面这段调用 认证的代码
home()
login(america) #需要验证就调用 login,把需要验证的功能 当做一个参数传给login
# home()
# america()
login(henan)
你之所改变了调用方式,是因为用户每次调用时需要执行login(henan),类似的。其实稍一改就可以了呀
home()
america = login(america)
henan = login(henan)
这样你,其它人调用henan时,其实相当于调用了login(henan), 通过login里的验证后,就会自动调用henan功能。
你:我擦,还真是唉。。。,老王,还是你nb。。。不过,等等, 我这样写了好,那用户调用时,应该是下面这个样子
home()
america = login(america) # 你在这里相当于把america这个函数替换了
henan = login(henan)
# 那用户调用时依然写
america()
但问题在于,还不等用户调用 ,你的america = login(america)就会先自己把america执行了呀。。。。,你应该等我用户调用 的时候 再执行才对呀,不信我试给你看。。。
老王:哈哈,你说的没错,这样搞会出现这个问题? 但你想想有没有解决办法 呢?
你:我擦,你指的思路呀,大哥。。。我哪知道 下一步怎么走。。。
老王:算了,估计你也想不出来。。。 学过嵌套函数没有?
你:yes,然后呢?
老王:想实现一开始你写的america = login(america)不触发你函数的执行,只需要在这个login里面再定义一层函数,第一次调用america = login(america)只调用到外层login,这个login虽然会执行,但不会触发认证了,因为认证的所有代码被封装在login里层的新定义 的函数里了,login只返回 里层函数的函数名,这样下次再执行america()时, 就会调用里层函数啦。。。
你:。。。。。。什么? 什么个意思,我蒙逼了。。。
老王:还是给你看代码吧。。
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
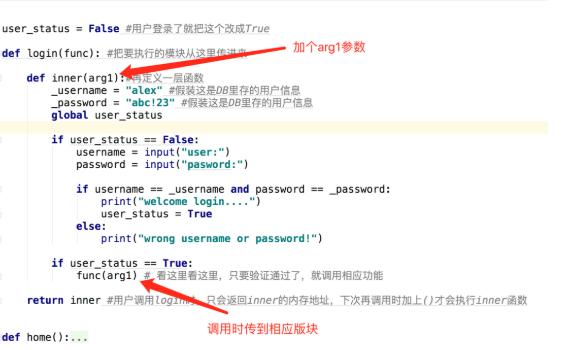
def login(func): # 把要执行的模块从这里传进来
def inner(): # 再定义一层函数
_username = "youmen" # 假装这是DB里存的用户信息
_password = "123" # 假装这是DB里存的用户信息
global user_status
if user_status == False:
username = input("user:")
password = input("pasword:")
if username == _username and password == _password:
print("welcome login....")
user_status = True
else:
print("wrong username or password!")
if user_status == True:
func() # 看这里看这里,只要验证通过了,就调用相应功能
return inner # 用户调用login时,只会返回inner的内存地址,下次再调用时加上()才会执行inner函数
此时你仔细着了老王写的代码 ,感觉老王真不是一般人呀,连这种奇淫巧技都能想出来。。。,心中默默感谢上天赐你一个大牛邻居。
你: 老王呀,你这个姿势很nb呀,你独创的?
此时你媳妇噗嗤的笑出声来,你也不知道 她笑个球。。。
老王:呵呵, 这不是我独创的呀当然 ,这是开发中一个常用的玩法,叫语法糖,官方名称“装饰器”,其实上面的写法,还可以更简单
可以把下面代码去掉
america = login(america) #你在这里相当于把america这个函数替换了
只在你要装饰的函数上面加上下面代码
@login
def america():
# login() #执行前加上验证
print("----欧美专区----")
def japan():
print("----日韩专区----")
@login
def henan():
# login() #执行前加上验证
print("----河南专区----")
效果是一样的。
你开心的玩着老王教你的新姿势 ,玩着玩着就手贱给你的“河南专区”版块 加了个参数,然后,结果 出错了。。。
你:老王,老王,怎么传个参数就不行了呢?
老王:那必然呀,你调用henan时,其实是相当于调用的login,你的henan第一次调用时henan = login(henan), login就返回了inner的内存地址,第2次用户自己调用henan("3p"),实际上相当于调用的时inner,但你的inner定义时并没有设置参数,但你给他传了个参数,所以自然就报错了呀
你:但是我的 版块需要传参数呀,你不让我传不行呀。。。
老王:没说不让你传,稍做改动便可。。
老王:你再试试就好了 。
你: 果然好使,大神就是大神呀。 。。 不过,如果有多个参数呢?
老王:。。。。老弟,你不要什么都让我教你吧,非固定参数你没学过么? *args,**kwargs...
你:噢 。。。还能这么搞?,nb,我再试试。
你身陷这种新玩法中无法自拔,竟没注意到老王已经离开,你媳妇告诉你说为了不打扰你加班,今晚带孩子去跟她姐妹住 ,你觉得媳妇真体贴,最终,你终于搞定了所有需求,完全遵循开放-封闭原则,最终代码如下 。
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
user_status = False # 用户登录了就把这个改成True
def login(func): # 把要执行的模块从这里传进来
def inner(*args, **kwargs): # 再定义一层函数
_username = "youmen" # 假装这是DB里存的用户信息
_password = "!23" # 假装这是DB里存的用户信息
global user_status
if user_status == False:
username = input("user:")
password = input("pasword:")
if username == _username and password == _password:
print("welcome login....")
user_status = True
else:
print("wrong username or password!")
if user_status == True:
func(*args, **kwargs) # 看这里看这里,只要验证通过了,就调用相应功能
return inner # 用户调用login时,只会返回inner的内存地址,下次再调用时加上()才会执行inner函数
def home():
print("---首页----")
@login
def america():
# login() #执行前加上验证
print("----欧美专区----")
def japan():
print("----日韩专区----")
# @login
def henan(style):
'''
:param style: 喜欢看什么类型的,就传进来
:return:
'''
# login() #执行前加上验证
print("----河南专区----")
home()
# america = login(america) #你在这里相当于把america这个函数替换了
henan = login(henan)
# #那用户调用时依然写
america()
henan("3p")
第二2天早上,产品经理又提了新的需求,要允许用户选择用qqweiboweixin认证,此时的你,已深谙装饰器各种装逼技巧,轻松的就实现了新的需求。
user_status = False #用户登录了就把这个改成True
def login(auth_type): #把要执行的模块从这里传进来
def auth(func):
def inner(*args,**kwargs):#再定义一层函数
if auth_type == "qq":
_username = "youmen" #假装这是DB里存的用户信息
_password = "!23" #假装这是DB里存的用户信息
global user_status
if user_status == False:
username = input("user:")
password = input("pasword:")
if username == _username and password == _password:
print("welcome login....")
user_status = True
else:
print("wrong username or password!")
if user_status == True:
return func(*args,**kwargs) # 看这里看这里,只要验证通过了,就调用相应功能
else:
print("only support qq ")
return inner #用户调用login时,只会返回inner的内存地址,下次再调用时加上()才会执行inner函数
return auth
def home():
print("---首页----")
@login('qq')
def america():
#login() #执行前加上验证
print("----欧美专区----")
def japan():
print("----日韩专区----")
@login('weibo')
def henan(style):
'''
:param style: 喜欢看什么类型的,就传进来
:return:
'''
#login() #执行前加上验证
print("----河南专区----")
home()
# america = login(america) #你在这里相当于把america这个函数替换了
#henan = login(henan)
# #那用户调用时依然写
america()
# henan("3p")
装饰器应用
# 装饰器应用: 登录认证
内置函数
函数就是以功能为导向,一个函数封装一个功能,那么Python将一些常用的功能(比如len)给我们封装成了一个一个的函数,供我们使用,他们不仅效率高(底层都是用C语言写的),而且是拿来即用,避免重复早轮子,那么这些函数就称为内置函数,到目前为止python给我们提供的内置函数一共是68个。
# sep输出信息以什么为分割
print(1,2,3,4,sep='^')
# end下一行输出不换行
print(1,end=' ')
print(2)
print(3)
# 1 2
# 3
abs
# abs() 返回绝对值
print(abs(-1234))
# 1234
sum
# sum: 求出可迭代对象所有对象的和
print(sum([1,23,4,5]))
min
# min: 求最小值
print(min([1,2,3])) # 返回此序列最小值
ret = min([1,2,-5,],key=abs) # 按照绝对值的大小,返回此序列最小值
print(ret)
reversed
# reversed()将一个序列翻转, 返回翻转序列的迭代器
ret = reversed([4,2,3423,1234,234])
print(list(ret))
# [234, 1234, 3423, 2, 4]
zip
# zip()拉链方法: 函数用于将可迭代对象作为参数,将对象中对应的元素打包成一个个元组
# 然后将这些元组组成的内容,如果各个迭代器的元素个数不一致,则按照长度最短的返回.
list1 = [1,2,3]
list2 = ['a','b','c']
list3 = [11,22,33]
for i in zip(list1,list2,list3):
print(i)
(1, 'a', 11)
(2, 'b', 22)
(3, 'c', 33)
sorted
# sorted排序算法
# 语法: sorted(iterable,key=None,reverse=False)
# iterable: 可迭代对象
# key: 排序规则(排序函数),在sotted内部会将可迭代对象的每一个元素传递给这个函数的参数,根据函数运算结果进行排序
# reverse: 是否是倒序,True倒叙,False正序
list1 = [1,6,5,4,5]
list2 = sorted(list1)
print(list2)
list3 = sorted(list1,reverse=True)
print(list3)
# [1, 4, 5, 5, 6]
# [6, 5, 5, 4, 1]
# 按照年龄对学生信息进行排序
lst = [{'id':1,'name':'alex','age':18},
{'id':2,'name':'wusir','age':17},
{'id':3,'name':'taibai','age':16},]
print(sorted(lst,key=lambda e:e['age']))
filter
# 语法: filter(function,iterable)
# function: 用来筛选的函数,在filter中会自动的把iterable中的元素传递给function,然后根据function返回的True或False来判断是否保留此项数据
# iterable: 可迭代对象
lst = [{'id':1,'name':'alex','age':18},
{'id':2,'name':'wusir','age':17},
{'id':3,'name':'taibai','age':16},]
ls = filter(lambda e:e['age'] > 17,lst)
print(list(ls))
map
# 映射函数
# 语法: map(function,iterable)可以对可迭代对象中的每一个元素映射,分别取执行function
# 计算列表中每个元素的平方,返回新列表
list1 = [1,2,3,4,5]
def func(s):
return s*s
mp = map(func,list1)
print(list(mp))
print(list(map(lambda s:s*s,list1)))
# [1, 4, 9, 16, 25]
# 计算两个列表相同位置元素的和
list1 = [1,2,3,4,5]
list2 = [1,2,3,4,5]
print(list(map(lambda x,y:x+y,list1,list2)))
# [2, 4, 6, 8, 10]
reduce
# reduce在python2是内置函数,python3编程模块
# reduce的使用方式
# reduce(函数名,可迭代对象)
from functools import reduce
def func(x,y):
return x*y
ret = reduce(func,[3,4,5,6])
print(ret)
# 匿名函数版
result = reduce(lambda x,y:x*10+y,[1,2,3,4])
print(result)
# reduce的作用是先把列表中前两个元素取出计算一个值后临时保存着, 接下来用这个临时保存的值和列表第三个元素进行计算,求出新的值将最开始临时保存的值覆盖,然后用这个新的临时值和列表的第四个元素计算,依此类推.
eval
执行字符串类型的代码,并返回最终结果
# eval 剥去字符串的外表运算里面的代码,公司一般不用,容易被黑客劫持替换成危险的脚本
s1 = '1+3'
print(s1)
print(eval(s1))
exec
# 执行字符串里面的代码
msg = '''
for i in range(10):
print(i)
'''
print(exec(msg))
hash
# hash: 获取一个对象(可哈希对象: int,str,bool,tuple)的哈希值
print(hash('1234'))
# -5939173262231693622
help
# help: 函数用于查看函数或模块用途的详细说明
print(help(list))
callable
# callable: 判断一个对象是否能调用,如果返回True,object仍然可能调用失败, 但如果返回False,调用对象object绝对不会成功
name = 'youmen'
def func():
pass
print(callable(name))
print(callable(func))
round
print(round(7/2))
print(round(3.14152))
bytes
# bytes: 用于不同编码之间的转化
s = 'youmen'
name = s.encode('utf-8')
print(name)
name2 = bytes(s,encoding='utf-8')
print(name2)
# b'youmen'
# b'youmen'
# ord: 输入字符找该字符编码的位置
print(ord('a'))
# chr 输入位置数字找到对应的字符
print(chr(97))
repr
# repr: 返回一个对象的string形式(原形毕露)
# %r 原封不动的写出来
name = 'zhou'
print('我叫%r'%name)
# repr: 返回一个对象的string形式
print(repr('{"name":"youmen"}'))
print('{"name":"youmen"}')
all and any
# all: 可迭代对象中,全都是True才是True
# any: 可迭代对象中,有一个True就是True
print(all([1,2,True,0,True]))
print(any([1,'',0]))
软件开发规范
开发规范是什么?
你现在包括之前写的一些程序,所谓的'项目',都是在一个py文件下完成的,代码量撑死也就几百行,你认为没问题,挺好。但是真正的后端开发的项目,系统等,少则几万行代码,多则十几万,几十万行代码,你全都放在一个py文件中行么?当然你可以说,只要能实现功能即可。咱们举个例子,如果你的衣物只有三四件,那么你随便堆在橱柜里,没问题,咋都能找到,也不显得特别乱,但是如果你的衣物,有三四十件的时候,你在都堆在橱柜里,可想而知,你找你穿过三天的袜子,最终从你的大衣口袋里翻出来了,这是什么感觉和心情......
软件开发,规范你的项目目录结构,代码规范,遵循PEP8规范等等,让你更加清晰滴,合理滴开发。
那么接下来我们以博客园系统的作业举例,将我们之前在一个py文件中的所有代码,整合成规范的开发。
为什么要设计好目录结构?
"设计项目目录结构",就和"代码编码风格"一样,属于个人风格问题。对于这种风格上的规范,一直都存在两种态度:
- 一类同学认为,这种个人风格问题"无关紧要"。理由是能让程序work就好,风格问题根本不是问题。
- 另一类同学认为,规范化能更好的控制程序结构,让程序具有更高的可读性。
我是比较偏向于后者的,因为我是前一类同学思想行为下的直接受害者。我曾经维护过一个非常不好读的项目,其实现的逻辑并不复杂,但是却耗费了我非常长的时间去理解它想表达的意思。从此我个人对于提高项目可读性、可维护性的要求就很高了。"项目目录结构"其实也是属于"可读性和可维护性"的范畴,我们设计一个层次清晰的目录结构,就是为了达到以下两点:
- 可读性高: 不熟悉这个项目的代码的人,一眼就能看懂目录结构,知道程序启动脚本是哪个,测试目录在哪儿,配置文件在哪儿等等。从而非常快速的了解这个项目。
- 可维护性高: 定义好组织规则后,维护者就能很明确地知道,新增的哪个文件和代码应该放在什么目录之下。这个好处是,随着时间的推移,代码/配置的规模增加,项目结构不会混乱,仍然能够组织良好。
所以,我认为,保持一个层次清晰的目录结构是有必要的。更何况组织一个良好的工程目录,其实是一件很简单的事儿。
目录组织方式
关于如何组织一个较好的Python工程目录结构,已经有一些得到了共识的目录结构。在Stackoverflow的这个问题上,能看到大家对Python目录结构的讨论。
这里面说的已经很好了,我也不打算重新造轮子列举各种不同的方式,这里面我说一下我的理解和体会。
假设你的项目名为foo, 我比较建议的最方便快捷目录结构这样就足够了:
Foo/
|-- bin/
| |-- foo
|
|-- foo/
| |-- tests/
| | |-- __init__.py
| | |-- test_main.py
| |
| |-- __init__.py
| |-- main.py
|
|-- docs/
| |-- conf.py
| |-- abc.rst
|
|-- setup.py
|-- requirements.txt
|-- README
需要解释一下
# 1. bin/`: 存放项目的一些可执行文件,当然你可以起名`script/`之类的也行。
# 2. `foo/`: 存放项目的所有源代码。(1) 源代码中的所有模块、包都应该放在此目录。不要置于顶层目录。(2) 其子目录`tests/`存放单元测试代码; (3) 程序的入口最好命名为`main.py`。
# 3. `docs/`: 存放一些文档。
# 4. `setup.py`: 安装、部署、打包的脚本。
# 5. `requirements.txt`: 存放软件依赖的外部Python包列表。
# 6. `README`: 项目说明文件。
除此之外,有一些方案给出了更加多的内容。比如
LICENSE.txt,ChangeLog.txt文件等,我没有列在这里,因为这些东西主要是项目开源的时候需要用到。如果你想写一个开源软件,目录该如何组织,可以参考这篇文章。
下面,再简单讲一下我对这些目录的理解和个人要求吧
关于README的内容
这个我觉得是每个项目都应该有的一个文件,目的是能简要描述该项目的信息,让读者快速了解这个项目。
它需要说明以下几个事项:
- 软件定位,软件的基本功能。
- 运行代码的方法: 安装环境、启动命令等。
- 简要的使用说明。
- 代码目录结构说明,更详细点可以说明软件的基本原理。
- 常见问题说明。
我觉得有以上几点是比较好的一个README。在软件开发初期,由于开发过程中以上内容可能不明确或者发生变化,并不是一定要在一开始就将所有信息都补全。但是在项目完结的时候,是需要撰写这样的一个文档的。
可以参考Redis源码中Readme的写法,这里面简洁但是清晰的描述了Redis功能和源码结构。
关于requirements.txt和setup.py
setup.py
一般来说,用setup.py来管理代码的打包、安装、部署问题。业界标准的写法是用Python流行的打包工具setuptools来管理这些事情。这种方式普遍应用于开源项目中。不过这里的核心思想不是用标准化的工具来解决这些问题,而是说,一个项目一定要有一个安装部署工具,能快速便捷的在一台新机器上将环境装好、代码部署好和将程序运行起来。
这个我是踩过坑的。
我刚开始接触Python写项目的时候,安装环境、部署代码、运行程序这个过程全是手动完成,遇到过以下问题:
- 安装环境时经常忘了最近又添加了一个新的Python包,结果一到线上运行,程序就出错了。
- Python包的版本依赖问题,有时候我们程序中使用的是一个版本的Python包,但是官方的已经是最新的包了,通过手动安装就可能装错了。
- 如果依赖的包很多的话,一个一个安装这些依赖是很费时的事情。
- 新同学开始写项目的时候,将程序跑起来非常麻烦,因为可能经常忘了要怎么安装各种依赖。
setup.py可以将这些事情自动化起来,提高效率、减少出错的概率。"复杂的东西自动化,能自动化的东西一定要自动化。"是一个非常好的习惯。
setuptools的文档比较庞大,刚接触的话,可能不太好找到切入点。学习技术的方式就是看他人是怎么用的,可以参考一下Python的一个Web框架,flask是如何写的: setup.py
当然,简单点自己写个安装脚本(deploy.sh)替代setup.py也未尝不可。
requirements.txt
这个文件存在的目的是:
- 方便开发者维护软件的包依赖。将开发过程中新增的包添加进这个列表中,避免在
setup.py安装依赖时漏掉软件包。 - 方便读者明确项目使用了哪些Python包。
这个文件的格式是每一行包含一个包依赖的说明,通常是flask>=0.10这种格式,要求是这个格式能被pip识别,这样就可以简单的通过 pip install -r requirements.txt来把所有Python包依赖都装好了。具体格式说明: 点这里。
关于配置文件的使用方法
注意,在上面的目录结构中,没有将
conf.py放在源码目录下,而是放在docs/目录下。
很多项目对配置文件的使用做法是:
- 配置文件写在一个或多个python文件中,比如此处的conf.py。
- 项目中哪个模块用到这个配置文件就直接通过
import conf这种形式来在代码中使用配置。
这种做法我不太赞同:
- 这让单元测试变得困难(因为模块内部依赖了外部配置)
- 另一方面配置文件作为用户控制程序的接口,应当可以由用户自由指定该文件的路径。
- 程序组件可复用性太差,因为这种贯穿所有模块的代码硬编码方式,使得大部分模块都依赖
conf.py这个文件。
所以,我认为配置的使用,更好的方式是,
- 模块的配置都是可以灵活配置的,不受外部配置文件的影响。
- 程序的配置也是可以灵活控制的。
能够佐证这个思想的是,用过nginx和mysql的同学都知道,nginx、mysql这些程序都可以自由的指定用户配置。
所以,不应当在代码中直接import conf来使用配置文件。上面目录结构中的conf.py,是给出的一个配置样例,不是在写死在程序中直接引用的配置文件。可以通过给main.py启动参数指定配置路径的方式来让程序读取配置内容。当然,这里的conf.py你可以换个类似的名字,比如settings.py。或者你也可以使用其他格式的内容来编写配置文件,比如settings.yaml之类的。