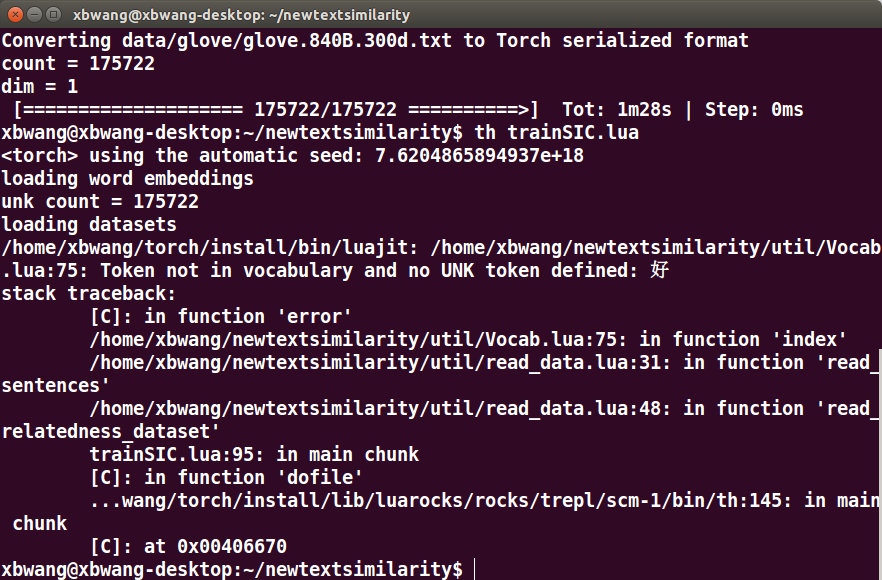
这是训练中文vocab做的句子相似度的程序:
/home/xbwang/torch/install/bin/luajit: /home/xbwang/newtextsimilarity/util/Vocab.lua:75: Token not in vocabulary and no UNK token defined: 好
在这一步时出现了报错,回去看vocab.lua的代码就能发现是因为在词库中没有相应词的向量
stack traceback:
[C]: in function 'error'
/home/xbwang/newtextsimilarity/util/Vocab.lua:75: in function 'index'
/home/xbwang/newtextsimilarity/util/read_data.lua:31: in function 'read_sentences'
/home/xbwang/newtextsimilarity/util/read_data.lua:48: in function 'read_relatedness_dataset'
trainSIC.lua:95: in main chunk
[C]: in function 'dofile'
...wang/torch/install/lib/luarocks/rocks/trepl/scm-1/bin/th:145: in main chunk
[C]: at 0x00406670
后面这几个错误其实都可以不用管,因为这些都是因为vocab.lua:75行报错后,其他调用程序出错。以后遇到这种情况,后面这些调用不用去看,看第一个出错的位置就好了,解决了那个错误后面的调用错误也都自然而然解决了。不过也可以从后面的这些地方看出调用了vocab.lua:75的都有哪些。