行人重识别综述:《Deep Learning for Person Re-identification: A Survey and Outlook》 2021
- 贡献点:
- 全面调研了近年来深度学习在Re-ID领域的进展,囊括了近几年三大视觉顶会上的大部分文章(如有遗漏,请谅解)。主要包括Closed-world Re-ID与Open-world Re-ID的研究进展,常用数据集和评价指标的概述,并分析了现有方法的不足和改进点。
- 展望:1) 一个新的评价指标mINP,用来评价找到最困难匹配行人所需要的代价;2) 一个强有力的AGW方法,在四种不同类型的Re-ID任务,包括12个数据集中取得了较好的效果;3) 从五个不同的方面讨论了未来Re-ID研究的重点和难点,仅供大家参考。
1、前言:
- Re-ID技术五大步骤:
- 1、数据采集,一般来源于监控摄像机的原始视频数据;
- 2、行人框生成,从视频数据中,通过人工方式或者行人检测或跟踪方式将行人从图中裁切出来,图像中行人将会占据大部分面积;
- 3、训练数据标注,包含相机标签和行人标签等其他信息;
- 4、重识别模型训练,设计模型(主要指深度学习模型),让它从训练数据中尽可能挖掘“如何识别不同行人的隐藏特征表达模式”;
- 5、行人检索,将训练好的模型应用到测试场景中,检验该模型的实际效果。
- 针对以上五个步骤的一些约束条件,本文将ReID技术分为 Closed-world 和Open-world 两大子集。Closed-world概括为大家常见的标注完整的有监督的行人重识别方法,Open-world概括为多模态数据,端到端的行人检索,无监督或半监督学习,噪声标注和一些Open-set的其他场景。
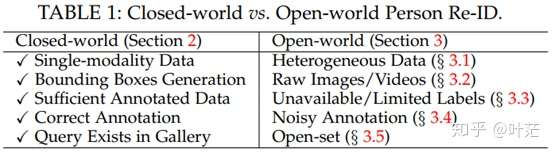
2、Closed-world Re-ID
- 一般包含以下假设:(1)通过图像或视频,可见光(RGB)摄像机捕捉行人;(2)行人由bounding boxes框出;(3)有足够多的被标注训练数据;(4)标注的数据标签通常都是正确的;(5)query person必须出现在gallery set 中。
- 根据方法设计流程,将其分为特征学习,度量学习和排序优化三个部分。研究人员的方法通常针对这三方面进行改进,侧重点不同。有的是提出了新颖的特征学习方法,有的提出有效的度量损失函数,也有的是在测试检索阶段进行优化。
- 在本章节末尾,还概括了现有的常用数据集和评价指标,以及现有SOTA的优缺点分析。
2.1 特征学习方法
- 全局特征学习,利用全身的全局图像来进行特征学习,常见的改进思路有Attention机制,多尺度融合等;
- 局部特征学习,利用局部图像区域(行人部件或者简单的垂直区域划分)来进行特征学习,并聚合生成最后的行人特征表示;
- 辅助特征学习,利用一些辅助信息来增强特征学习的效果,如语义信息(比如行人属性等)、视角信息(行人在图像中呈现的不同方位信息)、域信息(比如每一个摄像头下的数据表示一类域)、GAN生成的信息(比如生成行人图像)、数据增强等;
- 视频特征学习:利用一些视频数据提提取时序特征,并且融合多帧图像信息来构建行人特征表达
- 特定的网络设计:利用Re-ID任务的特性,设计一些细粒度,多尺度等相关的网络结构,使其更适用于Re-ID的场景。

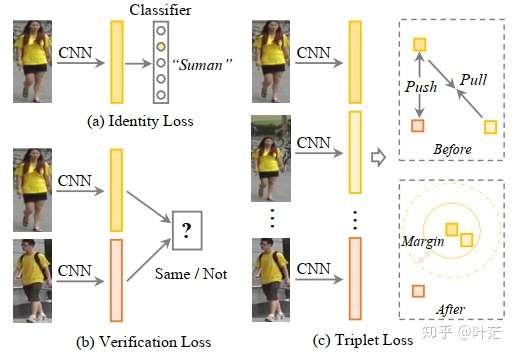
2.2 度量学习方法(损失函数)
- 早期的度量学习主要是设计不同类型的距离/相似度度量矩阵。深度学习时代,主要包括不同类型的损失函数的设计及采样策略的改进:
- Identity Loss: 将Re-ID的训练过程当成图像分类问题,同一个行人的不同图片当成一个类别,常见的有Softmax交叉熵损失函数;
- Verification Loss:将Re-ID的训练当成图像匹配问题,是否属于同一个行人来进行二分类学习,常见的有对比损失函数,二分类损失函数;
- Triplet Loss:将Re-ID的训练当成图像检索问题,同一个行人图片的特征距离要小于不同行人的特征距离,以及其各种改进;
- 训练策略的改进:自适应的采样方式(样本不均衡,难易程度)以及不同的权重分配策略
2.3 排序优化
- 用学习好的Re-ID特征得到初始的检索排序结果后,利用图片之间的相似性关系来进行初始的检索结果优化,主要包括重排序(re-ranking)和排序融合(rank fusion)等。

2.4 数据集和评价
- 主要包括现有的一些常用图像和视频数据集的概括,以及现有方法SOTA的一些总结和分析,希望综述里面的一些分析能够在大家进行模型设计时提供一些思路和帮助。具体分析详见原文。
- SOTA:state of the art缩写,指在该项研究任务中,目前最好/最先进的模型,或者目前最好的模型的结果/性能/表现。
3、Open-World Re-ID
- 由于常规的 Closed-world Re-ID 在有监督的实验场景中已经达到或接近瓶颈了,现在很多的研究都更偏向于 Open-World Re-ID 场景,也是当前Re-ID研究的热点。
- 根据Re-ID系统设计的五个步骤,本章节也从以下五个方面介绍:
- 1、多模态数据,所采集的数据不是单一的可见光模态;
- 2、端到端的行人检索(End-to-end Person Search),没有预先检测或跟踪好的行人图片/视频
- 3、无监督和半监督学习,标注数据有限或者无标注的新场景
- 4、噪声标注的数据,即使有标注,但是数据采集和标注过程中存在噪声或错误
- 5、一些其他Open-set场景,查询行人找不到,群体重识别,动态的多摄像头网络等
3.1 跨模态/多模态(异构)数据
- 基于深度图像Re-ID:旨在利用深度图信息的匹配(融合或跨模态匹配),在很多人机交互的室内场景应用中非常重要;
- 文本到图像Re-ID;旨在利用文字语言描述来搜索特定的行人图像,解决实际场景中查询行人图像缺失等问题;
- 可见光到红外Re-ID:旨在跨模态匹配白天的可见光图像到夜晚的红外行人图像,也有一些方法直接解决低照度的重识别任务;
- 跨分辨率Re-ID;不同高低分辨率行人图像匹配,旨在解决不同距离摄像头下行人分辨率差异巨大等问题
- 总体而言,异构的行人重识别问题需要解决的一大难题是不同模态数据之间的差异性问题
3.2 端到端Re-ID(End-to-end Person Search)
- 纯图像/视频的Re-ID;从原始raw 图像或者视频中直接检索出行人;
- 多摄像头跟踪的Re-ID;跨摄像头跟踪,也是很多产业化应用的重点。
3.3 半监督和无监督的Re-ID
-
为了缓解对标注数据的依赖,半监督和无监督/自监督现在成为了当前研究的热点,在CV顶会上呈爆炸之势。本文也主要分成两个部分:无监督Re-ID(不需要标注的源域)和无监督域自适应Re-ID(需要标注的源域数据或模型):
- 无监督Re-ID:主要包括一些跨摄像头标签估计(聚类或图匹配等)的方法,以及一些其他监督信息挖掘的方法(如local patch相似性等);
- 无监督域自适应Re-ID:包括一些目标域图像数据生成和一些目标域监督信息挖掘等方式。
-
考虑到无监督学习也是现在研究的热点,本文也对现有的SOTA做了一个简单的总结和分析,可以看到现在的无监督学习方法已经是效果惊人了,未来可期。如下表所示:
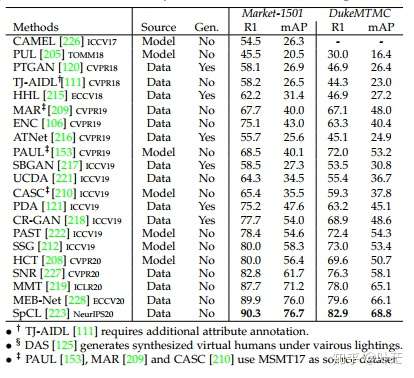
3.4 噪声鲁棒的Re-ID
- 主要针对标注数据或者数据采集中产生的一些噪声或错误等,方法包括:
- Partial Re-ID:解决行人图像区域部分被遮挡的行人重识别问题;(例如换装)
- Noise Sample:主要针对行人图像或视频中检测、跟踪产生的错误或偏差
- Noise Label:主要针对行人标签标注产生的错误
3.5 Open-set Re-ID and Beyond
- 主要针对一些其他开放场景进行一些探讨,如
- 1)gallery set 中query 行人没有出现的场景;
- 2)Group Re-ID:行人群体匹配的问题;
- 3)动态的多摄像头网络匹配等问题
4、展望
4.1 新的评价指标mINP
- 考虑到实际场景中,目标人物具有隐匿性,很多时候要找到其困难目标都非常难,给侦查工作带来麻烦。mINP主要目的是为了衡量Re-ID算法用来找到最难匹配样本所要付出的代价,
- 其计算方式跟mAP一样非常简单,应该还是对评价Re-ID效果有一定补充作用。简单来讲,排名倒数第一的正确样本位置越靠后,人工排查干预的代价越大,mINP的值越小。这里感谢Fast-ReID(https://github.com/JDAI-CV/fast-reid )项目对我们评价指标和方法的集成。
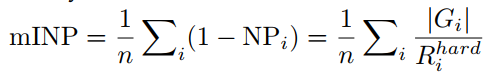
4.2 新的基准方法AGW
- 主要是在@罗浩 的Bag of tricks(感谢)上做的一些改进,主要包括:
- 1)Non-local注意力机制的融合;(自注意力机制)
- 2)Generalized-mean (GeM) Pooling的细粒度特征提取;(广义均值池化)
- 相比于最大池化(对输入样本取均值),平均池化(对输入样本取最大值),GeM包含可学习的参数p,对输入样本先求p次幂,然后取均值,在进行p次开方。GeM目前已经成为了图像检索池化操作的主流使用方法
- 3)加权正则化的三元组损失(Weighted Regularization Triplet (WRT) loss):
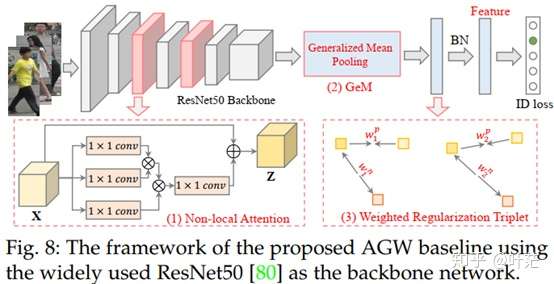
- 在审稿人的建议下,我们在四种不同类型的任务(图像Re-ID, 视频Re-ID,跨模态红外Re-ID和Partial Re-ID)的12个数据集上均对我们提出的新指标mINP和AGW方法进行了测评,在大多数情况下,我们的方法都能够取得比较好的效果。具体的实验结果和分析可以参考我们的论文和补充材料,希望我们的方法和评价指标能对大家有一些帮助。
4.3 对未来一些研究方向的思考
- 这一部分也是紧扣前面提出的五个步骤,针对五个步骤未来亟待解决的关键问题或者热点问题进行归纳。由于每个人理解上的认知偏差,这里的建议仅供大家参考:
- 不可控的数据采集:不确定多种模态混合的Re-ID,而不是固定的模态设置;换装的Re-ID,2020年已经有好几个新的数据集;
- 减少人工标注依赖:人机交互的主动学习,选择性的标注;从虚拟数据进行学习(Learning from virtual data),如何解决虚拟数据中的domain gap;
- 面向Re-ID通用网络设计:Domain Generalized Re-ID,如何设计一种在未知场景中也表现优异的模型,如何利用自动化机器学习来设计针对Re-ID任务的网络模型;
- 动态的模型更新:如何以小的代价将学习好的网络模型微调至新摄像头场景中;如何高效的利用新采集的数据(Newly Arriving Data)来更新之前已训练好的模型;
- 高效的模型部署:轻量型快速的行人重识别算法设计,自适应的针对不同类型的硬件配置(小型的移动手机和大型服务器)调整模型。