一、DNN 简介
DNN一共可以分为三层。
- 输入层(input layer)
- 隐藏层(hidden layer)
- 输出层(output layer)

DNN的前向传播即由输入经过一些列激活函数得到最终的输出
在对DNN参数求解的时候,通过反向传播,以及链式法则求得。
二、Tensorflow下的DNN实现
1、实现功能简介:
本文摘自Kaggle的一篇房价预测题目,找了一篇比较全的,当作自己的Tensorflow入门。链接:
https://www.kaggle.com/zoupet/neural-network-model-for-house-prices-tensorflow
数据和题目可以在文章开头的地址找的。
主要是给定了一个区域的房子价格以及房子特征,要预测一下房价。
2、挑选数据
1 # 为了使得代码在 python2 或者3下都运行,加的 __future__包。如果是python3,下面的包可以不加。 2 from __future__ import absolute_import 3 from __future__ import division 4 from __future__ import print_function 5 6 import itertools 7 8 import pandas as pd 9 import numpy as np 10 import matplotlib.pyplot as plt 11 from pylab import rcParams 12 import matplotlib 13 14 from sklearn.model_selection import train_test_split 15 16 # scaler, put the value range from min to max 17 from sklearn.preprocessing import MinMaxScaler 18 19 import tensorflow as tf 20 21 # 定义多少条记录会被当作log。 22 tf.logging.set_verbosity(tf.logging.INFO) 23 24 # InteractiveSession 与 Session的区别是不用每一次执行命令时,前面都加一个session。可以自己查一下 25 sess = tf.InteractiveSession() 26 27 # 文件目录 28 path_train = '/Users/adrian.wu/Desktop/learn/kaggle/price/data/all/train.csv' 29 30 ''' 31 首先只用数字特征进行预测,去除掉其它特征,比如类别等 32 ''' 33 train = pd.read_csv(path_train) 34 35 print('所有特征下,矩阵纬度:', train.shape) 36 37 # 挑选出只是数字类型的特征 38 train = train.select_dtypes(exclude=['object']) 39 print('数字类型特征矩阵的纬度:', train.shape) 40 41 # 去掉没用的特征Id 42 train.drop('Id', axis=1, inplace=True) 43 44 # 处理缺失值,简单的填充0 45 train.fillna(0, inplace=True) 46 47 print(" 特征:", list(train.columns)) 48 49 ''' 50 用Isolation Forest去掉异常值 51 ''' 52 from sklearn.ensemble import IsolationForest 53 54 clf = IsolationForest(max_samples=100, random_state=42) 55 clf.fit(train) 56 57 y_noano = clf.predict(train) 58 print(y_noano) 59 y_noano = pd.DataFrame(y_noano, columns=['Top']) 60 # y_noano[y_noano['Top'] == 1].index.values, 等于1的不是异常值,-1为异常值 61 62 train = train.iloc[y_noano[y_noano['Top'] == 1].index.values] 63 train.reset_index(drop=True, inplace=True) 64 65 print("异常值数量:", y_noano[y_noano['Top'] == -1].shape[0]) 66 print("正常数据数量:", train.shape[0])
3、特征预处理
1 ''' 2 特征预处理 3 ''' 4 import warnings 5 6 warnings.filterwarnings('ignore') 7 8 # 得到特征名字,并存为list类型 9 col_train = list(train.columns) 10 col_train_bis = list(train.columns) 11 12 # 去除要预测的值,SalePrice 13 col_train_bis.remove('SalePrice') 14 15 # 用numpy转为可操作的矩阵 16 mat_train = np.mat(train) 17 18 mat_y = np.array(train.SalePrice).reshape((1314, 1)) 19 20 # 归一化方法,把所有特征归一化到0~1之间 21 prepro_y = MinMaxScaler() 22 prepro_y.fit(mat_y) 23 24 prepro = MinMaxScaler() 25 prepro.fit(mat_train) 26 27 # 将处理过后的数据转为DataFrame 28 train = pd.DataFrame(prepro.transform(mat_train), columns=col_train)
4、train test数据集合处理
1 ''' 2 train test集合数据处理 3 ''' 4 5 # 把列都列出来 6 COLUMNS = col_train 7 FEATURES = col_train_bis 8 LABEL = "SalePrice" 9 10 # 暂且理解将DataFrame的数据转为对应的输入值,因此要指定一列列的值。 11 feature_cols = [tf.contrib.layers.real_valued_column(k) for k in FEATURES] 12 13 # 得到Feature 和 预测值 14 training_set = train[COLUMNS] 15 prediction_set = train.SalePrice 16 17 # 将Train test 分为2:1分 18 x_train, x_test, y_train, y_test = train_test_split(training_set[FEATURES], prediction_set, test_size=0.33, 19 random_state=42) 20 # 整合特征和预测值,对train集 21 y_train = pd.DataFrame(y_train, columns=[LABEL]) 22 training_set = pd.DataFrame(x_train, columns=FEATURES).merge(y_train, left_index=True, right_index=True) 23 24 # 整合特征和预测值,对test集 25 y_test = pd.DataFrame(y_test, columns=[LABEL]) 26 testing_set = pd.DataFrame(x_test, columns=FEATURES).merge(y_test, left_index=True, right_index=True) 27 28 # 打log的,可以忽略 29 tf.logging.set_verbosity(tf.logging.ERROR)
5、DNN网络
1 ''' 2 快速创建一个DNN网络, 3 optimizer = tf.train.GradientDescentOptimizer( learning_rate= 0.1 )) 可以自己选优化方式 4 激活函数为relu 5 都有哪些feature 6 隐藏层的神经元个数,递减,200,100,50,25,12个 7 ''' 8 9 regressor = tf.contrib.learn.DNNRegressor(feature_columns=feature_cols, 10 activation_fn=tf.nn.relu, 11 hidden_units=[200, 100, 50, 25, 12]) 12 13 training_set.reset_index(drop=True, inplace=True) 14 15 16 # 定义一个函数用来train网络 17 def input_fn(data_set, pred=False): 18 if pred == False: 19 feature_cols = {k: tf.constant(data_set[k].values) for k in FEATURES} 20 labels = tf.constant(data_set[LABEL].values) 21 22 return feature_cols, labels 23 24 if pred == True: 25 feature_cols = {k: tf.constant(data_set[k].values) for k in FEATURES} 26 27 return feature_cols 28 29 30 # trainDNN网络 31 regressor.fit(input_fn=lambda: input_fn(training_set), steps=2000) 32 33 # 估计测试集 34 ev = regressor.evaluate(input_fn=lambda: input_fn(testing_set), steps=1) 35 loss_score = ev["loss"] 36 print("test集的损失为: {0:f}".format(loss_score))
6、Adagrad优化器
看了下代码。这里的优化器用的是Adagrad。形式大致和SGD差不多,在其基础通过对梯度的迭代相加,对学习率进行了更新,从而控制学习率。
学习率随着梯度的和会逐渐变小。
1、迭代公式
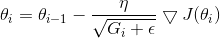
eta也就是分子项是初始学习率。G为梯度迭代和,G旁边长的很像E的那一项是一个小常数,防止分母为0。
由上式可得到,G越大,学习率越小。
三、Tensorflow一步一步搭建一个简单DNN
1、创建网络
1 import tensorflow as tf 2 from numpy.random import RandomState 3 from sklearn.model_selection import train_test_split 4 5 batch_size = 8 6 7 # 定义网络 8 w1 = tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1)) 9 b1 = tf.Variable(tf.zeros([1, 3], name="bias1")) 10 b2 = tf.Variable(tf.zeros([1], name="bias2")) 11 w2 = tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1)) 12 13 x = tf.placeholder(tf.float32, shape=(None, 2), name='x-input') 14 y_ = tf.placeholder(tf.float32, shape=(None, 1), name='y-input') 15 a = tf.matmul(x, w1) + b1 16 17 # 这里一定不要写成 tf.sigmoid 18 y_last = tf.nn.sigmoid(tf.matmul(a, w2) + b2)
2、定义损失函数
1 # 损失与准确率 2 loss = tf.losses.sigmoid_cross_entropy(y_, y_last) 3 train_step = tf.train.AdamOptimizer(0.07).minimize(loss) 4 5 correct_prediction = tf.equal(tf.round(y_last), y_) 6 acc = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
3、造数据
# 造数据,X为二维数据例如:[[0.1, 0.8]], 当X的第一项和第二项相加 < 1 时 Y为1, 当X的第一项和第二项相加 >= 1时为 0 rdm = RandomState(1) data_set_size = 128000 X = rdm.rand(data_set_size, 2) Y = [[int(x1 + x2 < 1)] for (x1, x2) in X] X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3)
4、训练与测试
with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op) STEPS = 7000 for i in range(0, 8900 - batch_size, batch_size): start = i sess.run(train_step, feed_dict={x: X_train[start: start + batch_size], y_: y_train[start: start + batch_size]}) if i % 800 == 0: # 计算所有数据的交叉熵 total_cross_entropy = sess.run(loss, feed_dict={x: X, y_: Y}) # 输出交叉熵之和 # print("After %d training step(s),cross entropy on all data is %g" % (i, total_cross_entropy)) acc_ = sess.run(acc, feed_dict={x: X_test, y_: y_test}) print("accuracy on test data is ", acc_) test = sess.run(y_last, feed_dict={x: X_test, y_: y_test})
5、结果
accuracy on test data is 0.96091145