并发之Striped64(累加器)
对于该类的实现思想:
Striped64是在java8中添加用来支持累加器的并发组件,它可以在并发环境下使用来做某种计数,Striped64的设计思路是在竞争激烈的时候尽量分散竞争,在实现上,Striped64维护了一个base Count和一个Cell数组,计数线程会首先试图更新base变量,如果成功则退出计数,否则会认为当前竞争是很激烈的,那么就会通过Cell数组来分散计数,Striped64根据线程来计算哈希,然后将不同的线程分散到不同的Cell数组的index上,然后这个线程的计数内容就会保存在该Cell的位置上面,基于这种设计,最后的总计数需要结合base以及散落在Cell数组中的计数内容。这种设计思路类似于java7的ConcurrentHashMap实现,也就是所谓的分段锁算法,ConcurrentHashMap会将记录根据key的hashCode来分散到不同的segment上,线程想要操作某个记录只需要锁住这个记录对应着的segment就可以了,而其他segment并不会被锁住,其他线程任然可以去操作其他的segment,这样就显著提高了并发度,虽然如此,java8中的ConcurrentHashMap实现已经抛弃了java7中分段锁的设计,而采用更为轻量级的CAS来协调并发,效率更佳。
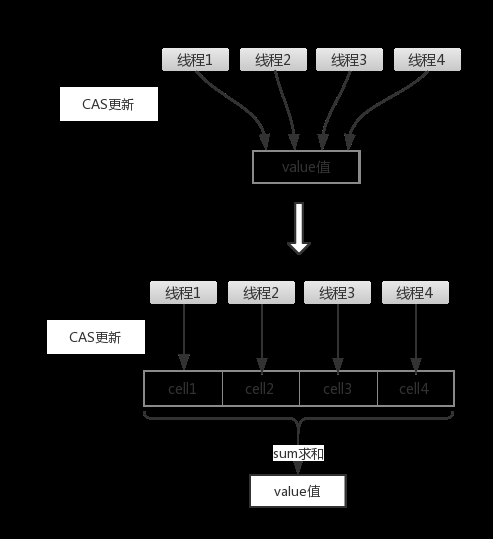
为了更加清楚的明确我上面的阐述,请看下面的图示:

/**
* cell表,容量为2的次幂
*/
transient volatile Cell[] cells;
/**
* 基础值,在更新操作时基于CAS无锁技术实现原子更新
*/
transient volatile long base;
/**
* 自旋锁 用于保护创建或者扩展Cell表。
*/
transient volatile int cellsBusy;
在这里讲下为什么要使用自旋锁:本人理解,自旋锁的一个最大特点或者最佳的使用场景就是要求线程持有锁的时间较短,那么在累加器中这种场景最为符合了;至于什么是自旋锁,在接下来会讲到;
让我们来看看Cell这个类;它被Contended修饰,目的是为了防止变量的伪共享;
@sun.misc.Contended static final class Cell {
//保存要累加的值
volatile long value;
Cell(long x) { value = x; }
//使用Unsafe类的cas来更新value的值
final boolean cas(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long valueOffset;
// 获取value值在Cell对象中的偏移量,以便迅速定位
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> ak = Cell.class;
valueOffset = UNSAFE.objectFieldOffset
(ak.getDeclaredField("value"));
} catch (Exception e) {
throw new Error(e);
}
}
}
在LongAdder类中,当我们调用public void add(long x)方法进行累加的时候,看看都做了些什么:
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||(a = as[getProbe() & m]) == null ||!(uncontended = a.cas(v = a.value, v + x))){
//调用Striped64的方法
longAccumulate(x, null, uncontended);
}
}
}
1 (as=cells)!=null;数组不为空;如果并发量不大,那么就不需要数组的操作或者协助,此时数组一定为null;但是此时数组不为空,那么一定存在竞争;
2 !casBase(b = base, b + x);表示CAS更新操作;如果一个线程去CAS失败,那么表示正在有一个线程正在CAS操作,表示竞争激烈;
在条件1和条件2成立的情况下,表明当前线程的CAS更新操作失败;或者cell数组不为空;
uncontended表示线程对cell数组中的元素操作是否不存在竞争,不存在返回true;
3 默认情况下不存在竞争;
4 看第二个判断为什么还有判断as==null呢,因为上述的第一个判断是||的情况,有可能CAS失败,但是数组还没有初始化;
5 as == null 表示数组没有初始化
6 m = as.length - 1<0表示数组的长度为0
7 (a = as[getProbe() & m]);获取当前线程的ThreadLocalRandomProb(当前本地线程探测值)然后对cell数组的长度取余数,该值为null,说明这个地方从来没有过线程做累加;
8 !(uncontended = a.cas(v = a.value, v + x));表示线程对cell数组中的某一个变量的值得CAS更新失败,那么这个位置存在竞争或者冲突;uncontended默认为true,不存在冲突
上述中5、6表示数组没有初始化
上述中7表示将当前线程散列到cell数组中的位置没有其他线程做过累加
上述中的8表示产生了冲突,uncontended=false;
上述四个条件成立一个就会进入 longAccumulate(x, null, uncontended);方法中
第一步:进入longAccumulate()方法表示此事存在竞争,或者并发很激烈;
1) 线程第一次进入该方法,那么ThreadLocalRandomProb(当前本地线程探测值)的值为0,那么第一次强制初始化;然后获取该线程的ThreadLocalRandomProb,即在Cell数组中的位置;并且第一次初始化数组,而且线程在该位置上没有存在竞争,那么设置uncontended=true
int h; if ((h = getProbe()) == 0) { ThreadLocalRandom.current(); // force initialization h = getProbe(); wasUncontended = true; }
2) 此时设置该位置上的线程要对数据进行更新,设置cas更新成功与否的标志;如果CAS成功表示false;
//cas冲突标志,表示当前线程hash到的Cells数组的位置,做cas累加操作时与其它线程发生了冲突,cas失败;collide=true代表有冲突,collide=false代表无冲突 boolean collide = false;
高并发下计数功能最好的数据结构就是LongAdder与DoubleAdder,低并发下效率也非常优秀,这是我见过的java并发包中设计的最为巧妙的类,从软硬件方面将java并发累加操作优化到了极致,所以应该我们应该弄清楚它的每一行代码为什么要这样做,它俩的实现大同小异,下面以LongAdder类为例介绍下它的实现。
Striped64类
public class LongAdder extends Striped64 implements Serializable
LongAdder继承了Striped64类,来实现累加功能的,它是实现高并发累加的工具类;
Striped64的设计核心思路就是通过内部的分散计算来避免竞争。
Striped64内部包含一个base和一个Cell[] cells数组,又叫hash表。
没有竞争的情况下,要累加的数通过cas累加到base上;如果有竞争的话,会将要累加的数累加到Cells数组中的某个cell元素里面。所以整个Striped64的值为sum=base+∑[0~n]cells。
Striped64内部三个重要的成员变量:
/**
* 存放Cell的hash表,大小为2的幂。
*/
transient volatile Cell[] cells;
/**
* 基础值,
* 1. 在没有竞争时会更新这个值;
* 2. 在cells初始化的过程中,cells处于不可用的状态,这时候也会尝试将通过cas操作值累加到base。
*/
transient volatile long base;
/**
* 自旋锁,通过CAS操作加锁,用于保护创建或者扩展Cell表。
*/
transient volatile int cellsBusy;
成员变量cells
cells数组是LongAdder高性能实现的必杀器:
AtomicInteger只有一个value,所有线程累加都要通过cas竞争value这一个变量,高并发下线程争用非常严重;
而LongAdder则有两个值用于累加,一个是base,它的作用类似于AtomicInteger里面的value,在没有竞争的情况不会用到cells数组,它为null,这时使用base做累加,有了竞争后cells数组就上场了,第一次初始化长度为2,以后每次扩容都是变为原来的两倍,直到cells数组的长度大于等于当前服务器cpu的数量为止就不在扩容(想下为什么到超过cpu数量的时候就不再扩容);每个线程会通过线程对cells[threadLocalRandomProbe%cells.length]位置的Cell对象中的value做累加,这样相当于将线程绑定到了cells中的某个cell对象上;
成员变量cellsBusy
cellsBusy,它有两个值0 或1,它的作用是当要修改cells数组时加锁,防止多线程同时修改cells数组,0为无锁,1为加锁,加锁的状况有三种
1. cells数组初始化的时候;
2. cells数组扩容的时候;
3. 如果cells数组中某个元素为null,给这个位置创建新的Cell对象的时候;
成员变量base
它有两个作用:
1. 在开始没有竞争的情况下,将累加值累加到base
2. 在cells初始化的过程中,cells不可用,这时会尝试将值累加到base上;
Cell内部类
//为提高性能,使用注解@sun.misc.Contended,用来避免伪共享,
@sun.misc.Contended static final class Cell {
//用来保存要累加的值
volatile long value;
Cell(long x) { value = x; }
//使用UNSAFE类的cas来更新value值
final boolean cas(long cmp, long val) {
returnUNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);
}
private static final sun.misc.Unsafe UNSAFE;
//value在Cell类中存储位置的偏移量;
private static final long valueOffset;
//这个静态方法用于获取偏移量
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> ak = Cell.class;
valueOffset = UNSAFE.objectFieldOffset
(ak.getDeclaredField("value"));
} catch (Exception e) {
throw new Error(e);
}
}
}
这个类很简单,final类型,内部有一个value值,使用cas来更新它的值;Cell类唯一需要注意的地方就是Cell类的注解@sun.misc.Contended。
伪共享
要理解Contended注解的作用,要先弄清楚什么是伪共享,会有什么影响,如何解决伪共享。
缓存行cache line
要理解伪共享先要弄清楚什么是cache line,cpu的缓存系统中是以缓存行(cache line)为单位存储的,缓存行是2的整数幂个连续字节,一般为32-256个字节。最常见的缓存行大小是64个字节,cache line是cache和memory之间数据传输的最小单元。
大多数现代cpu都one-die了L1和L2cache。对于L1 cache,大多是write though的;L2 cache则是write back的,不会立即写回memory,这就会导致cache和memory的内容的不一致;另外,对于mp(multi processors)的环境,由于cache是cpu私有的,不同cpu的cache的内容也存在不一致的问题,因此很多mp的的计算架构,不论是ccnuma还是smp都实现了cache coherence的机制,即不同cpu的cache一致性机制。
Write-through(直写模式)在数据更新时,同时写入缓存Cache和后端存储。
此模式的优点是操作简单;缺点是因为数据修改需要同时写入存储,数据写入速度较慢。
Write-back(回写模式)在数据更新时只写入缓存Cache。只在数据被替换出缓存时,
被修改的缓存数据才会被写到后端存储。此模式的优点是数据写入速度快,因为不需要写存储;
缺点是一旦更新后的数据未被写入存储时出现系统掉电的情况,数据将无法找回
cache coherence的一种实现是通过cache-snooping协议,每个cpu通过对bus的snoop实现对其它cpu读写cache的监控:
当cpu1要写cache时,其它cpu就会检查自己cache中对应的cache line,如果是dirty的,就write back到memory,并且会将cpu1的相关cache line刷新;如果不是dirty的,就invalidate该cache line.
当cpu1要读cache时,其它cpu就会将自己cache中对应的cache line中标记为dirty的部分write back到memory,并且会将cpu1的相关cache line刷新。
所以,提高cpu的cache hit rate,减少cache和memory之间的数据传输,将会提高系统的性能。
因此,在程序和二进制对象的内存分配中保持cache line aligned就十分重要,如果不保证cache line对齐,出现多个cpu中并行运行的进程或者线程同时读写同一个cache line的情况的概率就会很大。这时cpu的cache和memory之间会反复出现write back和refresh情况,这种情形就叫做cache thrashing。
为了有效的避免cache thrashing,通常有以下两种途径:
对于heap的分配,很多系统在malloc调用中实现了强制的alignment.
对于stack的分配,很多编译器提供了stack aligned的选项。
当然,如果在编译器指定了stack aligned,程序的尺寸将会变大,会占用更多的内存。因此,这中间的取舍需要仔细考虑;
为了解决这个问题在jdk1.6会采用long padding的方式,就是在防止被伪共享的变量的前后加上7个long类型的变量,如下所示:
public class VolatileLongPadding {
volatile long p0, p1, p2, p3, p4, p5, p6;
volatile long v = 0L;
volatile long q0, q1, q2, q3, q4, q5, q6;
}
jdk1.7的某个版本后会优化掉long padding,为了解决这个问题,在jdk1.8中加入了@sun.misc.Contended;
LongAdder
前面说了一大堆,现在终于进入到正题了。
LongAdder –>add方法
add方法是LongAdder累加的方法,传入的参数x为要累加的值;
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
/**
* 如果一下两种条件则继续执行if内的语句
* 1. cells数组不为null(不存在争用的时候,cells数组一定为null,一旦对base的cas操作失败,才会初始化cells数组)
* 2. 如果cells数组为null,如果casBase执行成功,则直接返回,如果casBase方法执行失败(casBase失败,说明第一次争用冲突产生,需要对cells数组初始化)进入if内;
* casBase方法很简单,就是通过UNSAFE类的cas设置成员变量base的值为base+要累加的值
* casBase执行成功的前提是无竞争,这时候cells数组还没有用到为null,可见在无竞争的情况下是类似于AtomticInteger处理方式,使用cas做累加。
*/
if ((as = cells) != null || !casBase(b = base, b + x)) {
//uncontended判断cells数组中,当前线程要做cas累加操作的某个元素是否#不#存在争用,如果cas失败则存在争用;uncontended=false代表存在争用,uncontended=true代表不存在争用。
boolean uncontended = true;
/**
*1. as == null : cells数组未被初始化,成立则直接进入if执行cell初始化
*2. (m = as.length - 1) < 0: cells数组的长度为0
*条件1与2都代表cells数组没有被初始化成功,初始化成功的cells数组长度为2;
*3. (a = as[getProbe() & m]) == null :如果cells被初始化,且它的长度不为0,则通过getProbe方法获取当前线程Thread的threadLocalRandomProbe变量的值,初始为0,然后执行threadLocalRandomProbe&(cells.length-1 ),相当于m%cells.length;如果cells[threadLocalRandomProbe%cells.length]的位置为null,这说明这个位置从来没有线程做过累加,需要进入if继续执行,在这个位置创建一个新的Cell对象;
*4. !(uncontended = a.cas(v = a.value, v + x)):尝试对cells[threadLocalRandomProbe%cells.length]位置的Cell对象中的value值做累加操作,并返回操作结果,如果失败了则进入if,重新计算一个threadLocalRandomProbe;
如果进入if语句执行longAccumulate方法,有三种情况
1. 前两个条件代表cells没有初始化,
2. 第三个条件指当前线程hash到的cells数组中的位置还没有其它线程做过累加操作,
3. 第四个条件代表产生了冲突,uncontended=false
**/
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
longAccumulate方法
三个参数第一个为要累加的值,第二个为null,第三个为wasUncontended表示调用方法之前的add方法是否未发生竞争;
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
//获取当前线程的threadLocalRandomProbe值作为hash值,如果当前线程的threadLocalRandomProbe为0,说明当前线程是第一次进入该方法,则强制设置线程的threadLocalRandomProbe为ThreadLocalRandom类的成员静态私有变量probeGenerator的值,后面会详细将hash值的生成;
//另外需要注意,如果threadLocalRandomProbe=0,代表新的线程开始参与cell争用的情况
//1.当前线程之前还没有参与过cells争用(也许cells数组还没初始化,进到当前方法来就是为了初始化cells数组后争用的),是第一次执行base的cas累加操作失败;
//2.或者是在执行add方法时,对cells某个位置的Cell的cas操作第一次失败,则将wasUncontended设置为false,那么这里会将其重新置为true;第一次执行操作失败;
//凡是参与了cell争用操作的线程threadLocalRandomProbe都不为0;
int h;
if ((h = getProbe()) == 0) {
//初始化ThreadLocalRandom;
ThreadLocalRandom.current(); // force initialization
//将h设置为0x9e3779b9
h = getProbe();
//设置未竞争标记为true
wasUncontended = true;
}
//cas冲突标志,表示当前线程hash到的Cells数组的位置,做cas累加操作时与其它线程发生了冲突,cas失败;collide=true代表有冲突,collide=false代表无冲突
boolean collide = false;
for (;;) {
Cell[] as; Cell a; int n; long v;
//这个主干if有三个分支
//1.主分支一:处理cells数组已经正常初始化了的情况(这个if分支处理add方法的四个条件中的3和4)
//2.主分支二:处理cells数组没有初始化或者长度为0的情况;(这个分支处理add方法的四个条件中的1和2)
//3.主分支三:处理如果cell数组没有初始化,并且其它线程正在执行对cells数组初始化的操作,及cellbusy=1;则尝试将累加值通过cas累加到base上
//先看主分支一
if ((as = cells) != null && (n = as.length) > 0) {
/**
*内部小分支一:这个是处理add方法内部if分支的条件3:如果被hash到的位置为null,说明没有线程在这个位置设置过值,没有竞争,可以直接使用,则用x值作为初始值创建一个新的Cell对象,对cells数组使用cellsBusy加锁,然后将这个Cell对象放到cells[m%cells.length]位置上
*/
if ((a = as[(n - 1) & h]) == null) {
//cellsBusy == 0 代表当前没有线程cells数组做修改
if (cellsBusy == 0) {
//将要累加的x值作为初始值创建一个新的Cell对象,
Cell r = new Cell(x);
//如果cellsBusy=0无锁,则通过cas将cellsBusy设置为1加锁
if (cellsBusy == 0 && casCellsBusy()) {
//标记Cell是否创建成功并放入到cells数组被hash的位置上
boolean created = false;
try {
Cell[] rs; int m, j;
//再次检查cells数组不为null,且长度不为空,且hash到的位置的Cell为null
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
//将新的cell设置到该位置
rs[j] = r;
created = true;
}
} finally {
//去掉锁
cellsBusy = 0;
}
//生成成功,跳出循环
if (created)
break;
//如果created为false,说明上面指定的cells数组的位置cells[m%cells.length]已经有其它线程设置了cell了,继续执行循环。
continue;
}
}
//如果执行的当前行,代表cellsBusy=1,有线程正在更改cells数组,代表产生了冲突,将collide设置为false
collide = false;
/**
*内部小分支二:如果add方法中条件4的通过cas设置cells[m%cells.length]位置的Cell对象中的value值设置为v+x失败,说明已经发生竞争,将wasUncontended设置为true,跳出内部的if判断,最后重新计算一个新的probe,然后重新执行循环;
*/
} else if (!wasUncontended)
//设置未竞争标志位true,继续执行,后面会算一个新的probe值,然后重新执行循环。
wasUncontended = true;
/**
*内部小分支三:新的争用线程参与争用的情况:处理刚进入当前方法时threadLocalRandomProbe=0的情况,也就是当前线程第一次参与cell争用的cas失败,这里会尝试将x值加到cells[m%cells.length]的value ,如果成功直接退出
*/
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;
/**
*内部小分支四:分支3处理新的线程争用执行失败了,这时如果cells数组的长度已经到了最大值(大于等于cup数量),或者是当前cells已经做了扩容,则将collide设置为false,后面重新计算prob的值
else if (n >= NCPU || cells != as)
collide = false;
/**
*内部小分支五:如果发生了冲突collide=false,则设置其为true;会在最后重新计算hash值后,进入下一次for循环
*/
else if (!collide)
//设置冲突标志,表示发生了冲突,需要再次生成hash,重试。 如果下次重试任然走到了改分支此时collide=true,!collide条件不成立,则走后一个分支
collide = true;
/**
*内部小分支六:扩容cells数组,新参与cell争用的线程两次均失败,且符合库容条件,会执行该分支
*/
else if (cellsBusy == 0 && casCellsBusy()) {
try {
//检查cells是否已经被扩容
if (cells == as) { // Expand table unless stale
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
//为当前线程重新计算hash值
h = advanceProbe(h);
//这个大的分支处理add方法中的条件1与条件2成立的情况,如果cell表还未初始化或者长度为0,先尝试获取cellsBusy锁。
}else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try { // Initialize table
//初始化cells数组,初始容量为2,并将x值通过hash&1,放到0个或第1个位置上
if (cells == as) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
//解锁
cellsBusy = 0;
}
//如果init为true说明初始化成功,跳出循环
if (init)
break;
}
/**
*如果以上操作都失败了,则尝试将值累加到base上;
*/
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break; // Fall back on using base
}
}
关于hash的生成
hash是LongAdder定位当前线程应该将值累加到cells数组哪个位置上的,所以hash的算法是非常重要的,下面就来看看它的实现。
java的Thread类里面有一个成员变量
@sun.misc.Contended("tlr")
int threadLocalRandomProbe;
threadLocalRandomProbe这个变量的值就是LongAdder用来hash定位Cells数组位置的,平时线程的这个变量一般用不到,它的值一直都是0。
在LongAdder的父类Striped64里通过getProbe方法获取当前线程threadLocalRandomProbe的值:
static final int getProbe() {
//PROBE是threadLocalRandomProbe变量在Thread类里面的偏移量,所以下面语句获取的就是threadLocalRandomProbe的值;
return UNSAFE.getInt(Thread.currentThread(), PROBE);
}
threadLocalRandomProbe的初始化
线程对LongAdder的累加操作,在没有进入longAccumulate方法前,threadLocalRandomProbe一直都是0,当发生争用后才会进入longAccumulate方法中,进入该方法第一件事就是判断threadLocalRandomProbe是否为0,如果为0,则将其设置为0x9e3779b9
int h;
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current();
h = getProbe();
//设置未竞争标记为true
wasUncontended = true;
}
重点在这行ThreadLocalRandom.current();
public static ThreadLocalRandom current() {
if (UNSAFE.getInt(Thread.currentThread(), PROBE) == 0)
localInit();
return instance;
}
在current方法中判断如果probe的值为0,则执行locaInit()方法,将当前线程的probe设置为非0的值,该方法实现如下:
static final void localInit() {
//private static final AtomicInteger probeGenerator =
new AtomicInteger();
//private static final int PROBE_INCREMENT = 0x9e3779b9;
int p = probeGenerator.addAndGet(PROBE_INCREMENT);
//prob不能为0
int probe = (p == 0) ? 1 : p; // skip 0
long seed = mix64(seeder.getAndAdd(SEEDER_INCREMENT));
//获取当前线程
Thread t = Thread.currentThread();
UNSAFE.putLong(t, SEED, seed);
//将probe的值更新为probeGenerator的值
UNSAFE.putInt(t, PROBE, probe);
}
probeGenerator 是static 类型的AtomicInteger类,每执行一次localInit()方法,都会将probeGenerator 累加一次0x9e3779b9这个值;,0x9e3779b9这个数字的得来是 2^32 除以一个常数,这个常数就是传说中的黄金比例 1.6180339887;然后将当前线程的threadLocalRandomProbe设置为probeGenerator 的值,如果probeGenerator 为0,这取1;
threadLocalRandomProbe重新生成
就是将prob的值左右移位 、异或操作三次
static final int advanceProbe(int probe) {
probe ^= probe << 13; // xorshift
probe ^= probe >>> 17;
probe ^= probe << 5;
UNSAFE.putInt(Thread.currentThread(), PROBE, probe);
return probe;
}
probe从=1开始反复执行10次,结果如下:
1
270369
67634689
-1647531835
307599695
-1896278063
745495504
632435482
435756210
2005365029
-1378868364