The First Pig Program
环境:
Hadoop-1.1.2
pig-0.11.1
linux系统为CentOS6.4
jdk1.6
在伪分布式下模式下运行
启动:pig 或 pig –x mapreduce
启动后会看到这样的界面就表示启动成功了

我们来运行一个例子
输入数据student.txt如下
201000101:ZhangLong:Man:20:Computer
201000102:WangLi:Women:19:Software
201000103:LiuHua:Women:18:Compuer
201000104:LiXiao:Man:19:DataStructer
201000105:WuDa:Man:19:System
201000106:HuaKe:Man:19:ComputerSystem
将student.txt上传到HDFS文件系统上面的input目录下面
查看fs –ls /input
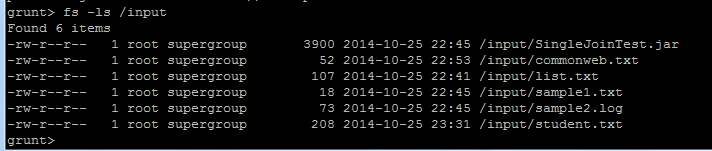
最下面一个就是student.txt
运行方式一
--加载数据(注意“=”左右两边要空格)
grunt>> A = load '/input/student.txt' using PigStorage(':') as (sno:chararray, sname:chararray, ssex:chararray, sage:int, sdept:chararray);
--从A中选出Student相应的字段(注意“=”左右两边要空格)
grunt>> B = foreach A generate sname, sage;
--将B中的内容输出到屏幕上
grunt>> dump B;
--将B的内容输出到HDFS文件系统的文件中
grunt>> store B into '/output/result.txt';
grunt>> fs –cat /output/result.txt/part-m-00000
结果如下:
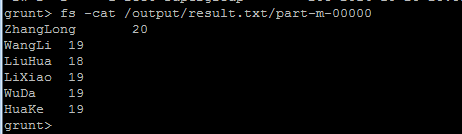
可见第一个pig运行成功了
运行方式二
创建一个script.pig文件,将上面执行的语句都放进去,
A = load '/input/student.txt' using PigStorage(':') as (sno:chararray, sname:chararray, ssex:chararray, sage:int, sdept:chararray);
B = foreach A generate sname, sage;
dump B;
store B into '/result1.txt';
然后存储在linux系统本地,然后到该同级目录下,运行pig script.pig
照样成功