NCBI淘汰序列GI - 使用Accession.Version代替!
截至2016年9月,被称为“GI”的整数序列标识符将不再包括在NCBI支持的序列记录的GenBank,GenPept和FASTA格式中。FASTA标题将进一步简化,以便仅报告国际序列数据库协作(INSDC)和NCBI参考序列(RefSeq)项目管理的登录的序列登录号和记录标题。 当NCBI进行此转换时,我们鼓励具有依赖于GI的工作流的任何用户开始计划使用accession.version标识符。2016年9月之后,任何完全依赖于地理标志的过程将不再像预期的那样发挥作用。
GI号自GenBank版本81.0(1994年2月)以来一直在使用,作为登录号的附加标识符,以稳定地参考序列记录的特定版本。版本跟踪在1997年作为整数后缀添加到登记号中,该后缀随着对记录中的序列数据的每次更新而增加。例如,“ AC020606.7 ”表示记录的序列内容自第一次发布以来已更新六次。因此,已经以冗余方式通过GI和登录版本提供序列版本化信息。在过去十年中,NCBI继续以快速增长的速度接收新的或更新的序列的提交。为了回应这一点,我们不得不开发使用accession.version信息的新数据存储解决方案,而不是GI信息,以跟踪更新。缺乏GI的序列的当前实例包括WGS和TSA项目中的未注释重叠群。这导致我们传送版本信息不一致的情况。
考虑到数据提交数量的持续增加和记录提交的日益不一致,现在是我们采取下一步,删除旧的冗余GI标识符并保留序列版本的单一标识符的时候了,可读的accession.version。这种改变将简化跟踪序列的过程,而没有任何功能的损失。这种变化还将通过促进使用accession.version作为优选序列标识符来简化科学通信。因此,在接下来的几个月中,我们将不再将GI分配给越来越多的新序列。具有现有GI的序列记录将以某些表示格式保留它们,例如ASN.1和5列特征表格格式,但GI值将不再以其他表示格式显示,包括GenBank平面文件和FASTA格式。将继续支持接受GI作为输入的NCBI服务,并且NCBI将向当前不支持它们的所有服务添加对accession.version标识符的支持。
这种转换到停止分配和报告GI首先在2013年12月的GenBank 199.0版本说明中描述,并在最近的GenBank更新中描述。有关背景信息,请参见当前GenBank发行说明的第1.4.1节:ftp : //ftp.ncbi.nih.gov/genbank/gbrel.txt
由INSDC和所有NCBI RefSeq记录交换的所有序列记录的FASTA显示也将更改为仅报告accession.version和记录标题。这将提高与NCBI提供的其他文件类型(包括GFF3,Gene和dbSNP下载文件)的兼容性。基于用户请求,已经对来自重新设计的基因组FTP位点的数据进行了该FASTA格式改变,以具有GFF3和FASTA格式的单一一致的序列标识符。请参阅此更改的以前公告:http://www.ncbi.nlm.nih.gov/news/08-26-2014-new-genomes-FTP-live/ ..此时,我们计划继续提供来自非INSDC和非RefSeq源的序列的FASTA显示中的数据库源信息,包括:SwissProt,PDB结构,PIR和专利序列。
2016年9月之后,这些更改将开始出现在平面文件和FASTA格式序列数据,NCBI编程实用程序结果以及GenBank和RefSeq全面FTP版本的NCBI Web视图中。
实施例1:INSDC核苷酸记录 - 在下面的样品记录中,核苷酸序列AF123456被分配GI为6633795,并且从其编码区特征翻译的蛋白质被分配GI为6633796:
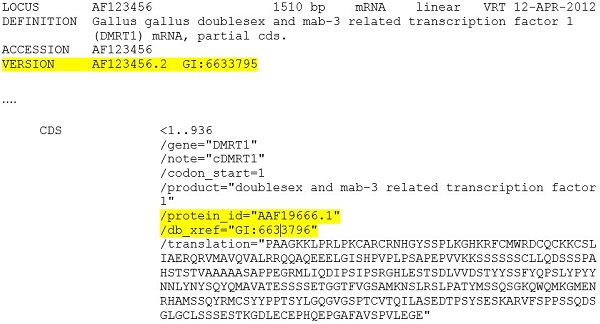
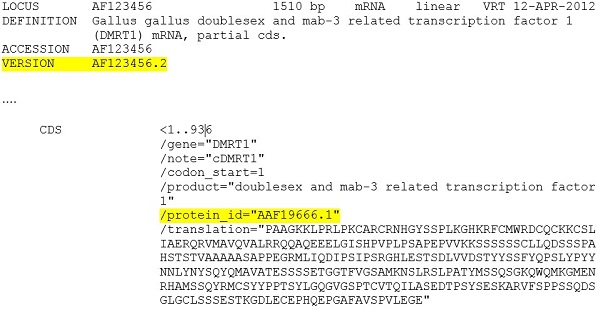
2016年9月之后,accession.version将是序列版本的唯一指示符。VERSION行上的GI值和编码区特征的GI / db_xref限定符将不再可见。
实施例2:GenPept蛋白质记录 - 当前记录显示包括VERSION行中的GI。注意,GenPept格式的编码区特征从未包括GI值的显示。

2016年9月后,VERSION行将不包含GI值:

示例3:对FASTA格式的更改:GI和数据库源值将从FASTA头中删除 - 在大多数资源中,当前的FASTA显示当前包括GI和数据库源信息(例如,GenBank的'gb'), '。下游分析工具通常需要首先处理FASTA标题行以将序列标识符部分简化为登录版本或GI。复杂的FASTA序列标识符以黄色突出显示:

2016年9月之后,将在FASTA标题中提供一个简单的序列ID用于核苷酸和蛋白质记录
