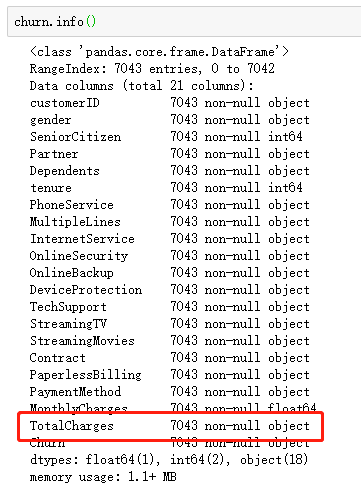
出现的问题:如图,总消费金额本应该为float类型,此处却显示object
需求:将 TotalCharges 的类型转换成float
使用 pandas.to_numeric(arg, errors='raise', downcast=None) 方法,可将参数转换为数字类型。
(别的类型转换,遇到再补充)
1 df = pd.read_excel('./data_files/Using_Customer-Churn.xlsx') 2 3 # 将df.TotalCharges 转成数字类型的数据,则将无效解析设置为NaN 4 df.TotalCharges = pd.to_numeric(df.TotalCharges, errors='coerce') 5 df.isnull().sum()
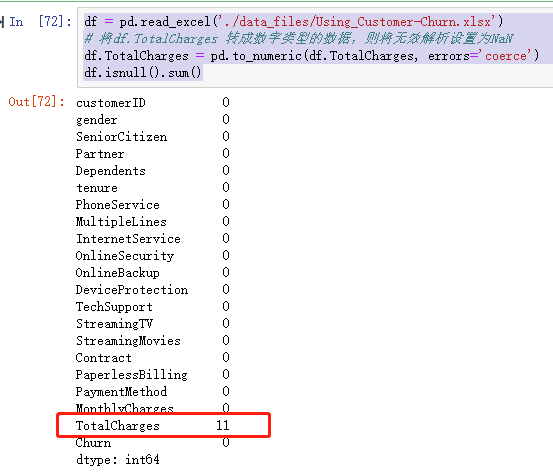
此时,转换完成!
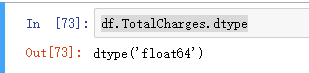
关于pandas.to_numeric 方法的详细信息可参见:https://www.cjavapy.com/article/532/
—————————— 手动分隔,以下为原来的野生思路 —————————
1 首先要找出本特征中,包含的数据类型究竟有哪些
1 # 创建一个用于盛放数据类型的列表 2 test_type = list() 3 4 for i in churn["TotalCharges"]: 5 6 # 将数据类型 不重复的放入列表中 7 if type(i) not in test_type: 8 test_type.append(type(i)) 9 print(test_type) 10 11 """ 12 [<class 'float'>, <class 'int'>, <class 'str'>] 13 """
2 查看除 float 和 int 之外的类型的数据有哪些
# 创建用于盛放数据的列表 str_values= list() for i in churn["TotalCharges"]: if type(i) != float and type(i) != int: # 将既不是 float 也不是 int 的数据加到列表 str_values.append(i) print(str_values) """ [' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' '] """
此时得到:非数值型数据均为空格。
3 将数据统一为 float 类型
1 # 空值替换所有空格 2 churn['TotalCharges'] = churn["TotalCharges"].replace(" ",np.nan) 3 # 去掉含有空值的样本 4 churn = churn[churn["TotalCharges"].notnull()] 5 # 将 TotalCharges 转换成 float类型 6 churn['TotalCharges'] = churn['TotalCharges'].astype(float)
此时
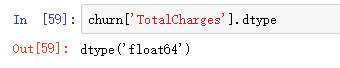
大功告成!
遍历的方法,相对来说效率略低,Pandas 应该有什么方法,更加直接吧
纯野生思路,找到更好的办法再更新~