1. url构成
http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name
(1)协议部分:该URL的协议部分为“http:”,这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,如HTTP,FTP等等本例中使用的是HTTP协议。在"HTTP"后面的“//”为分隔符
(2)域名部分:该URL的域名部分为“www.aspxfans.com”。一个URL中,也可以使用IP地址作为域名使用
(3)端口部分:跟在域名后面的是端口,域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口
(4)虚拟目录部分:从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。虚拟目录也不是一个URL必须的部分。本例中的虚拟目录是“/news/”
(5)文件名部分:从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分,如果没有“?”和“#”,那么从域名后的最后一个“/”开始到结束,都是文件名部分。本例中的文件名是“index.asp”。文件名部分也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名
(6)锚部分:从“#”开始到最后,都是锚部分。本例中的锚部分是“name”。锚部分也不是一个URL必须的部分
(7)参数部分:从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分。本例中的参数部分为“boardID=5&ID=24618&page=1”。参数可以允许有多个参数,参数与参数之间用“&”作为分隔符
2. dns协议
如果说ARP协议是将IP地址转换成MAC地址,那么DNS协议则是用来将域名转换为IP地址(也可以将IP地址转换成相应的域名地址)
IP地址是面向主机的,而域名是面向用户的。
域名服务主要是基于UDP实现的,服务器的端口号为53。
域名是分层结构,域名服务器也是对应的层级结构。
有了域名结构,还需要有一个东西去解析域名,域名需要由遍及全世界的域名服务器去解析,域名服务器实际上就是装有域名系统的主机。
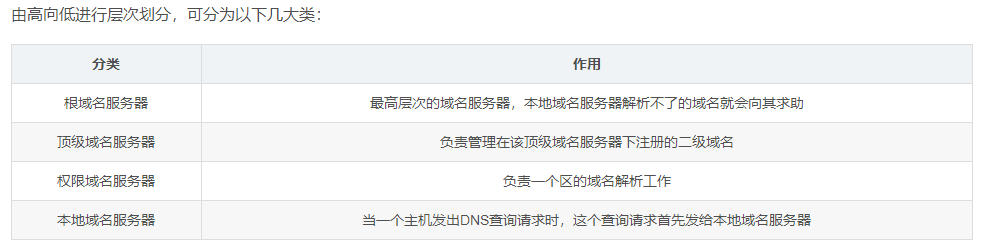
域名解析总体可分为一下过程:
(1) 输入域名后, 先查找自己主机对应的域名服务器,域名服务器先查找自己的数据库中的数据.
(2) 如果没有, 就向上级域名服务器进行查找, 依次类推
(3) 最多回溯到根域名服务器, 肯定能找到这个域名的IP地址
(4) 域名服务器自身也会进行一些缓存, 把曾经访问过的域名和对应的IP地址缓存起来, 可以加速查找过程
具体可描述如下:
1. 主机先向本地域名服务器进行递归查询
2. 本地域名服务器采用迭代查询,向一个根域名服务器进行查询
3. 根域名服务器告诉本地域名服务器,下一次应该查询的顶级域名服务器的IP地址
4. 本地域名服务器向顶级域名服务器进行查询
5. 顶级域名服务器告诉本地域名服务器,下一步查询权限服务器的IP地址
6. 本地域名服务器向权限服务器进行查询
7. 权限服务器告诉本地域名服务器所查询的主机的IP地址
8. 本地域名服务器最后把查询结果告诉主机
上文我们提出了两个概念:递归查询和迭代查询
(1)递归查询:本机向本地域名服务器发出一次查询请求,就静待最终的结果。如果本地域名服务器无法解析,自己会以DNS客户机的身份向其它域名服务器查询,直到得到最终的IP地址告诉本机
(2)迭代查询:本地域名服务器向根域名服务器查询,根域名服务器告诉它下一步到哪里去查询,然后它再去查,每次它都是以客户机的身份去各个服务器查询。
3. 浏览器的渲染过程
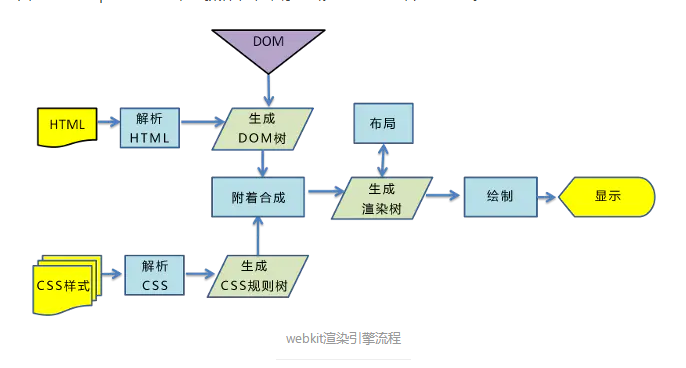
(1)浏览器会将获取的HTML文档解析成DOM树,DOM树的构建过程是一个深度遍历过程,当前节点的所有子节点都构建好后才会去构建当前节点的下一个兄弟节点
(2)处理CSS标记,将CSS解析成CSS规则树或CSSOM(层叠样式表模型)
(3)构建:根据DOM树和CSSOM树来构建渲染树,渲染树不等于DOM树,没有display:none
(4)布局:浏览器可以根据render树来计算网页上有哪些节点,各节点的CSS和其从属关系、在页面中的位置
(5)绘制:遍历render树进行绘制页面中的各元素
4. CSS选择器及其优先级
CSS三大特性:继承、优先级和层叠
继承:子类元素继承父类的元素
优先级:是指不同类别样式的权重比较
层叠:数量相同是,通过层叠(后者代替前者)的样式
(1)css选择器分类:
1)标签选择器:div
2)类选择器
3)ID选择器
4)全局选择器:*
5)组合选择器
6)后代选择器
7)群组选择器
8)继承选择器
9)伪类选择器
10)字符串匹配的属性选择符(^ $ *三种,分别对应开始、结尾、包含)
11)子选择器 (如:div>p ,带大于号>)
12)CSS 相邻兄弟选择器器 (如:h1+p,带加号+)
(2)css优先级
不同级别:
总结排序:!important > 行内样式>ID选择器 > 类选择器 > 标签 > 通配符 > 继承 > 浏览器默认属性
同一级别:
- 内联样式表的权值为 1000
- ID 选择器的权值为 100
- Class 类选择器的权值为 10
- HTML 标签选择器的权值为 1
内联样式 > 内部样式 > 外部样式
5. 手写promise
6. promise.then等链式调用的实现
7. keep-alive实现的机制
8. keep-alive更新
9. vue路由原理和状态维护
10. trim的实现
由于webpack本身只能打包commonjs规范的js文件,所以针对css,图片等格式的文件没法打包,就需要引入第三方的模块进行打包。
loader 扩展了webpack,只专注于转化文件这一个领域,完成压缩 / 打包 / 语言翻译等,仅仅只是为了打包,仅仅只是为了打包。
如 css-loader 和 style-loader 模块,是为了打包css的
如 babel-loader 和 babel-core 模块,是为了把es6的代码 转成 es5
如 url-loader 和 file-loader,是为了把图片进行打包
plugin也是为了扩展webpack的功能,plugin是作用于webpack本身的;
从打包优化到压缩,到重新定义环境变量,webpack提供了很多开箱即用的插件:
如 CommonChunkPlugin 主要用于提取第三方库和公共模块,避免首屏加载的bundle文件 或者 按需加载的bundle文件体积过大,导致加载时间过长,是优化的利器
注:CommonsChunkPlugin于4.0及以后被移除,使用SplitChunksPlugin替代
如 html-webpack-plugin 用于html文件的拷贝,打包,还给html中自动增加了引入打包后的js文件的代码 <script src=""></script>,还能指明把js文件引入到html文件的底部等,参考 webpack打包
loader运行在打包文件之前,loader为在模块加载时的预处理文件
plugins在整个编译周期都起作用