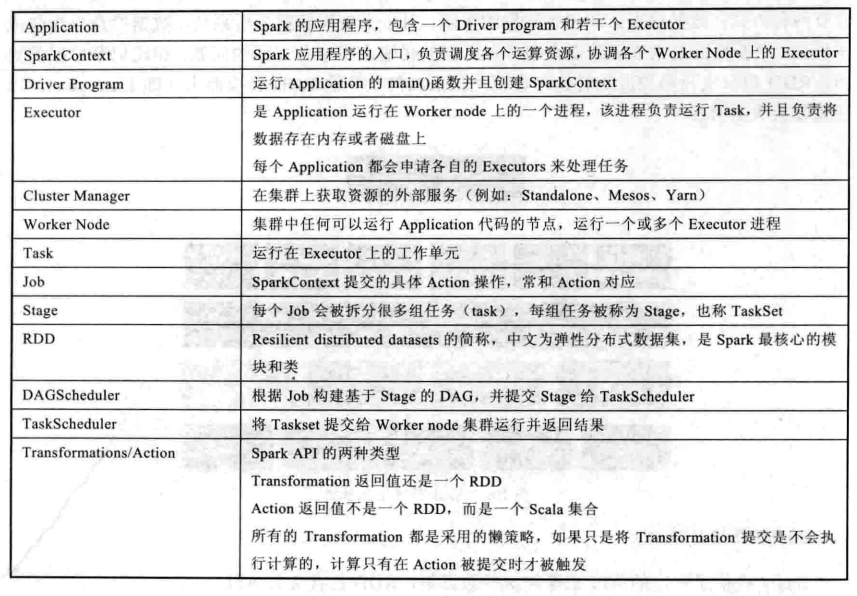
Application
application和Hadoop MapReduce类似,都是指用户编写的spark应用程序,其中包含了一个driver功能的代码和分布在集群中多个节点运行的executor代码。
Driver
使用driver这一概念的分布式框架很多,比如hive。spark中的driver即运行上述application的main()函数并创建sparkcontext,创建sparkcontext的目的是为了准备spark应用程序的运行环境。在spark中,由sparkcontext负责与clustermanager通信,进行资源的申请,任务的分配和监控等。当executor部分执行完毕以后,driver负责将sparkcontext关闭。通常用sparkcontext代表driver。
Executor
某个application运行worker节点上的一个进程,该进程负责执行task,并且负责将数据存储在内存或者磁盘上。每个application都有各自独立的一批executor。在spark on yarn模式下,其进程名字为CoarseGrainedExecutor Backend,类似于Hadoop MapReduce中的YarnChild,一个CoarseGrainedExecutor Backend进程有且仅有一个executor对象,它负责将task包装成taskRunner,并从线程池中抽取一个空闲线程运行task。这样,每个CoarseGrainedExecutor Backend能并行运行task的数量就取决于分配给它的CPU个数了。
ClusterManager
指的是在集群上获取资源的外部服务,目前有三种类型。
Standalone
Spark原生的资源管理,由master负责资源的分配,可以在亚马逊的EC2上运行。
Apache Mesos
与Hadoop MapReduce兼容性良好的一种资源调度框架。
Hadoop Yarn
主要指的是yarn中的resourcemanager。
Worker
集群中任何可以运行application代码的节点,类似于yarn中的nodemanager节点。在standalone模式中指的就是通过slave文件配置的worker节点,在spark on yarn中指的是nodemanager节点。
Task
被送到某个executor上的工作单元,和Hadoop MapReduce中的maptask和reducetask概念一样,是运行Application的基本单位,多个task组成一个stage,而task的调度和管理由TaskScheduler负责。
Job
包含多个task组成的并行计算,往往由spark Action触发产生。一个Application中可能会产生多个job
Stage
每个job会拆分成多组task,作为一个TaskSet,其名称为Stage,Stage的划分和调度由DAGSchedule负责。Stage有非最终的Stage(即shuffle Map Stage)和最终的Stage即(Result Stage)两种,Stage的边界就是发生shuffle的地方。
RDD
Spark的基本计算单元,通过一系列的算子进行操作(主要有transformation和Action两种操作)。同时,RDD是Spark最核心的东西,它表示已被分区、被序列化、不可变的、有容错机制的,并且能够被并行操作的数据集合。其存储基本可以是磁盘也可以是内存,通过spark.storageLevel属性配置。
共享变量
在spark Application运行时,可能需要共享一些变量,提供给Task或Driver使用。Spark提供了两种共享变量,一种是可以缓存到各个节点的广播变量,另外一种是只支持加法操作,可以实现求和的累加变量。
宽依赖
或称为shuffleDependency,与Hadoop MapReduce中的shuffle的数据依赖相同,宽依赖需要计算好所有父RDD对应的数据分区,然后在节点之间进行shuffle。
窄依赖
或称为narrowDependency,指某个具体的RDD,其分区partition a最多被子RDD中的的一个分区partition b依赖,此种情况只有map任务,是不需要shuffle过程的。窄依赖分为1:1和N:1两种。
DAGScheduler
根据job构建基于stage的DAG,并提交stage给TaksScheduler,其划分stage的依据是RDD之间的依赖关系。
TaskScheduler
将task任务提交给worker运行,每个executor运行什么task就是再次分配的。
常见术语表