pip install jieba
安装jieba模块
如果网速比较慢,
可以使用豆瓣的Python源:
pip install -i https://pypi.douban.com/simple/ jieba
一、分词:
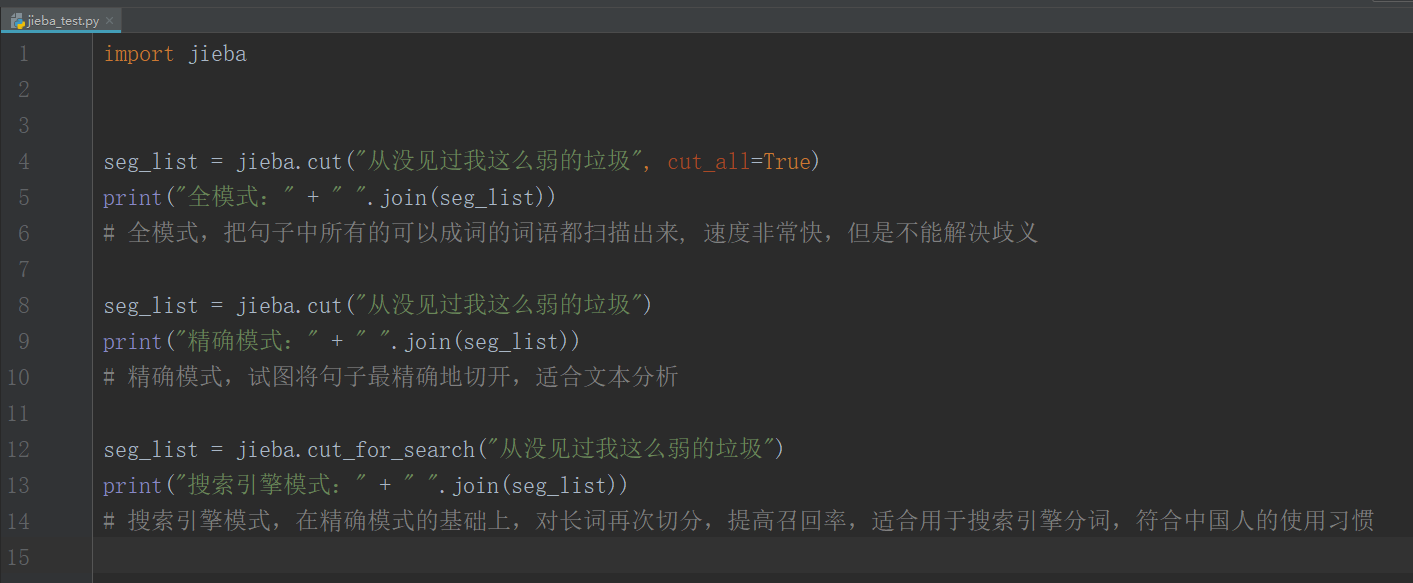
import jieba
seg_list = jieba.cut("从没见过我这么弱的垃圾", cut_all=True)
print("全模式:" + " ".join(seg_list))
# 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义
seg_list = jieba.cut("从没见过我这么弱的垃圾")
print("精确模式:" + " ".join(seg_list))
# 精确模式,试图将句子最精确地切开,适合文本分析
seg_list = jieba.cut_for_search("从没见过我这么弱的垃圾")
print("搜索引擎模式:" + " ".join(seg_list))
# 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词,符合中国人的使用习惯
打印结果:
全模式:从没 没见 过 我 这么 弱 的 垃圾
精确模式:从没 见 过 我 这么 弱 的 垃圾
搜索引擎模式:从没 见 过 我 这么 弱 的 垃圾
也可以这样写:
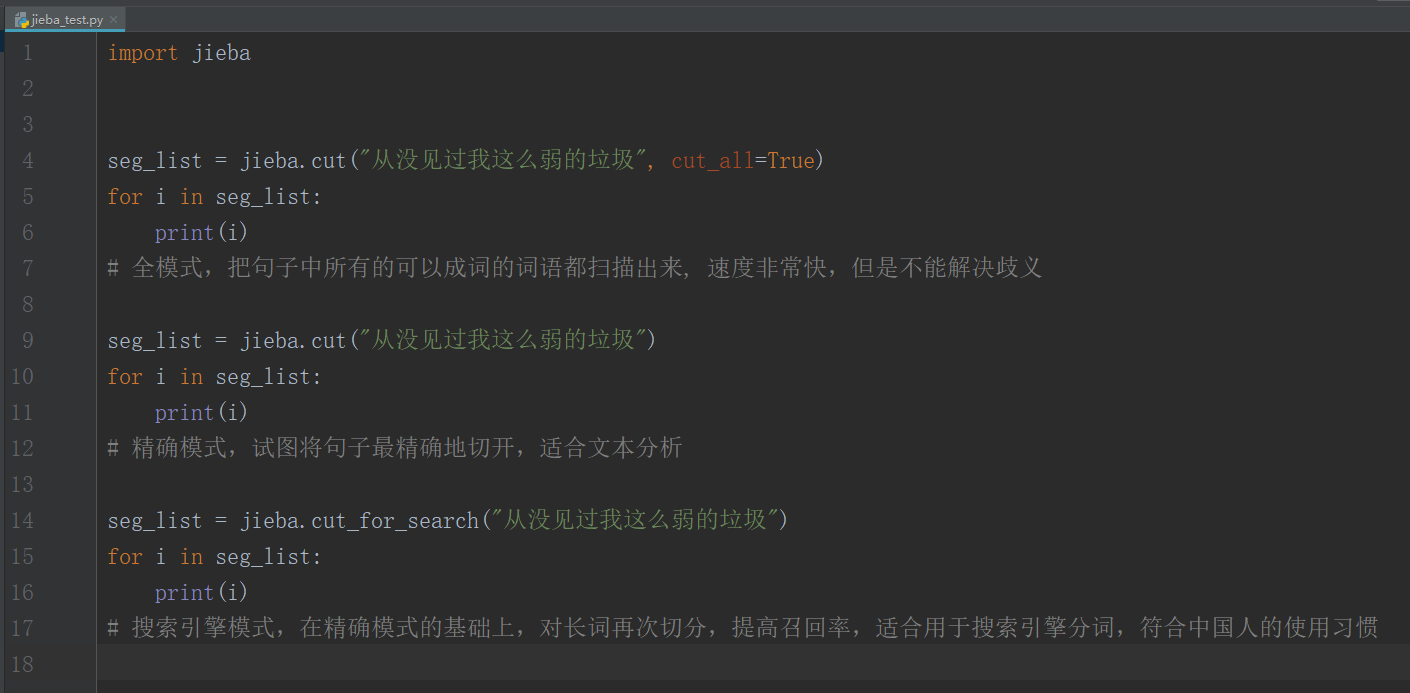
import jieba
seg_list = jieba.cut("从没见过我这么弱的垃圾", cut_all=True)
for i in seg_list:
print(i)
# 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义
seg_list = jieba.cut("从没见过我这么弱的垃圾")
for i in seg_list:
print(i)
# 精确模式,试图将句子最精确地切开,适合文本分析
seg_list = jieba.cut_for_search("从没见过我这么弱的垃圾")
for i in seg_list:
print(i)
# 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词,符合中国人的使用习惯
打印结果:
从没
没见
过
我
这么
弱
的
垃圾
从没
见
过
我
这么
弱
的
垃圾
从没
见
过
我
这么
弱
的
垃圾
jieba.cut 方法接受三个输入参数:
1、需要分词的字符串;
2、cut_all 参数用来控制模式,
cut_all=True or False,
默认为False(精确模式);
3、HMM 参数用来控制是否使用HMM模型,
HMM=True or False,
默认为True(新词识别)。
jieba.cut_for_search 方法接受两个参数:
1、需要分词的字符串;
2、是否使用 HMM 模型。
该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的generator,
可以使用 for 循环来获得分词后得到的每一个词语(unicode),
或者用
jieba.lcut 以及 jieba.lcut_for_search 直接返回 list
二、添加自定义的词典:
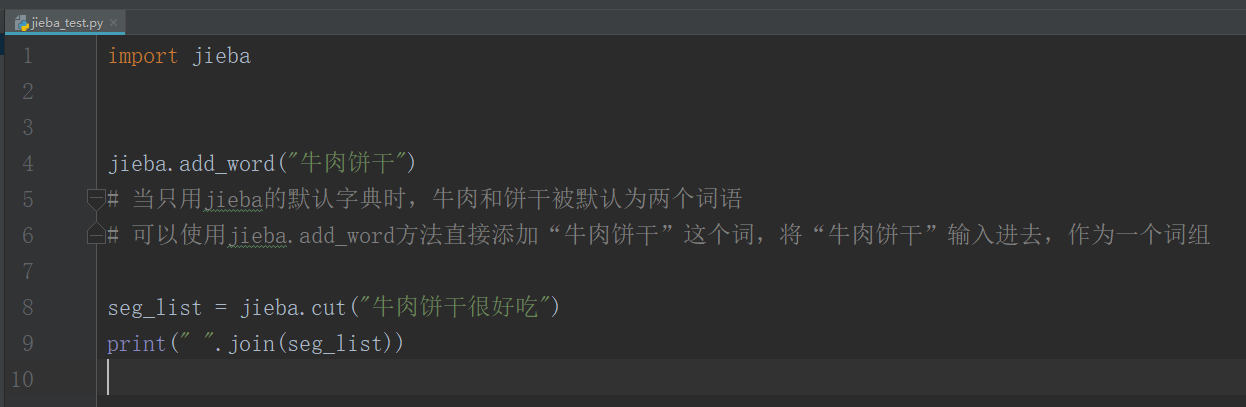
import jieba
jieba.add_word("牛肉饼干")
# 当只用jieba的默认字典时,牛肉和饼干被默认为两个词语
# 可以使用jieba.add_word方法直接添加“牛肉饼干”这个词,将“牛肉饼干”输入进去,作为一个词组
seg_list = jieba.cut("牛肉饼干很好吃")
print(" ".join(seg_list))
打印结果:
牛肉饼干 很 好吃
还可以这样写:
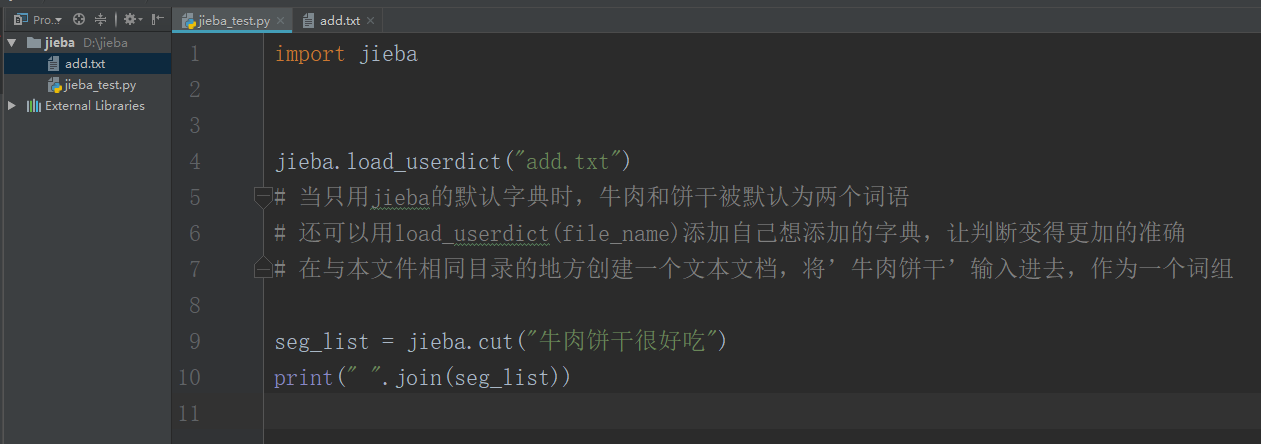
import jieba
jieba.load_userdict("add.txt")
# 当只用jieba的默认字典时,牛肉和饼干被默认为两个词语
# 还可以用load_userdict(file_name)添加自己想添加的字典,让判断变得更加的准确
# 在与本文件相同目录的地方创建一个文本文档,将’牛肉饼干’输入进去,作为一个词组
seg_list = jieba.cut("牛肉饼干很好吃")
print(" ".join(seg_list))
打印结果:
牛肉饼干 很 好吃
三、调整词典:
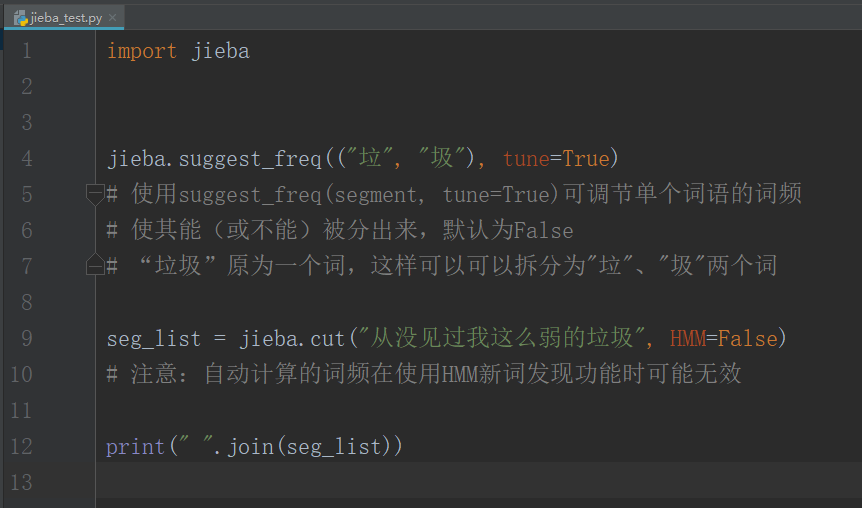
import jieba
jieba.suggest_freq(("垃", "圾"), tune=True)
# 使用suggest_freq(segment, tune=True)可调节单个词语的词频
# 使其能(或不能)被分出来,默认为False
# “垃圾”原为一个词,这样可以可以拆分为"垃"、"圾"两个词
seg_list = jieba.cut("从没见过我这么弱的垃圾", HMM=False)
# 注意:自动计算的词频在使用HMM新词发现功能时可能无效
print(" ".join(seg_list))
打印结果:
从没 见 过 我 这么 弱 的 垃 圾
补充:
1、文件名不可命令为jieba.py
否则会报错:
AttributeError: module 'jieba' has no attribute 'cut'
2、join()方法:
连接字符串数组,
将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串