ElasticSearch的接口语法
curl ‐X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' ‐d '<BODY>'

1.创建索引index同时映射mapping
请求地址,创建一个名为myindex1的索引库
http://192.168.118.3:9200/myindex1
请求的JSON
{ "mappings": { "type1": { "properties": { "id": { "type": "long", "store": true, "index": false }, "title": { "type": "text", "store": true, "index": true, "analyzer":"standard" }, "content": { "type": "text", "store": true, "index": true, "analyzer":"standard" } } } } }
- type:存储的类型
- store:代表是否保存,取值类型为boolean
- index:代表是否进行进行分析(分词),我用的是6.2.4版本的es,其他版本可能有差异取值为"not_analyzed"或"analyzed",
- analyzer:代表使用的分析器的类型,之后才用中文分词的时候修改此处
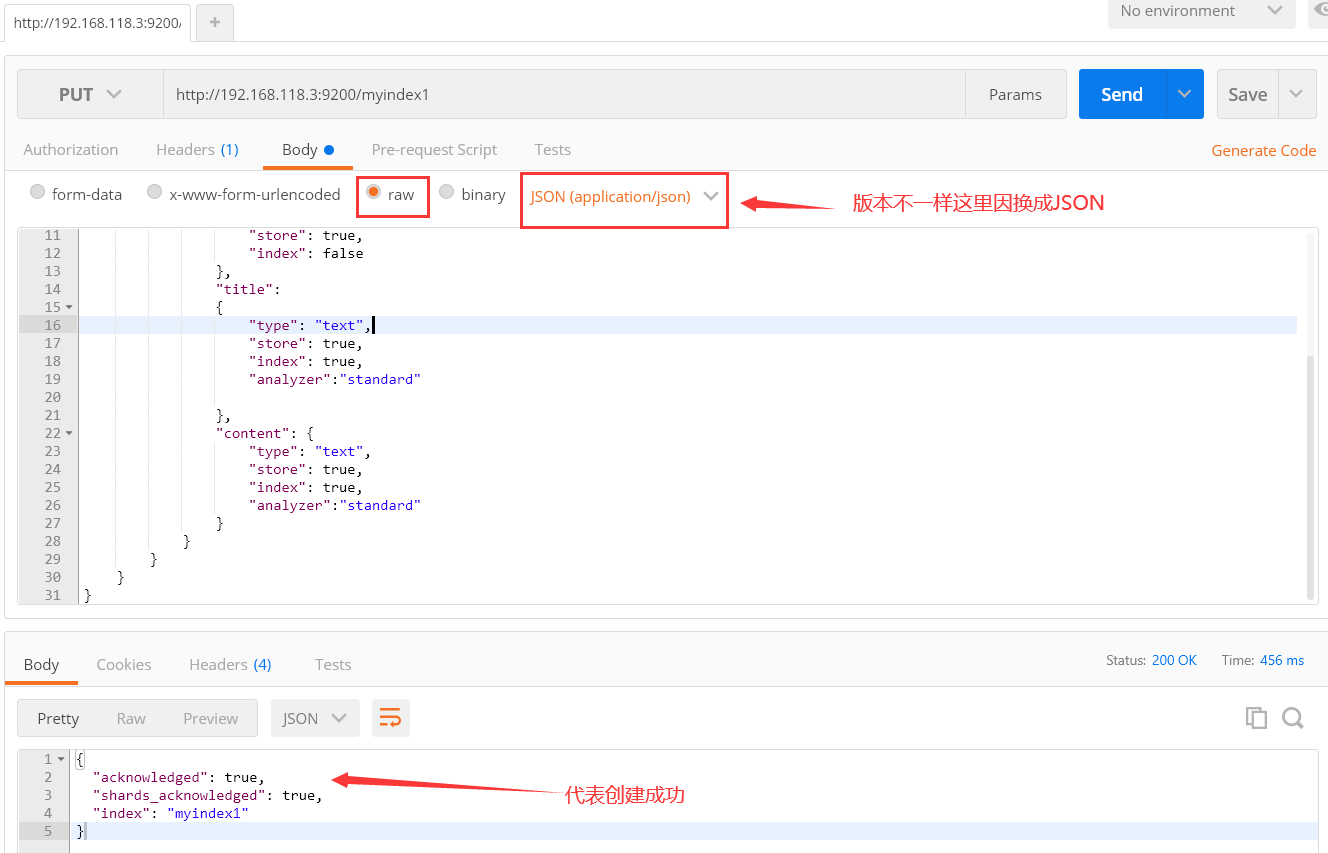
elasticsearch-head查看(我这里使用的集群,默认分成5片,复制一份)
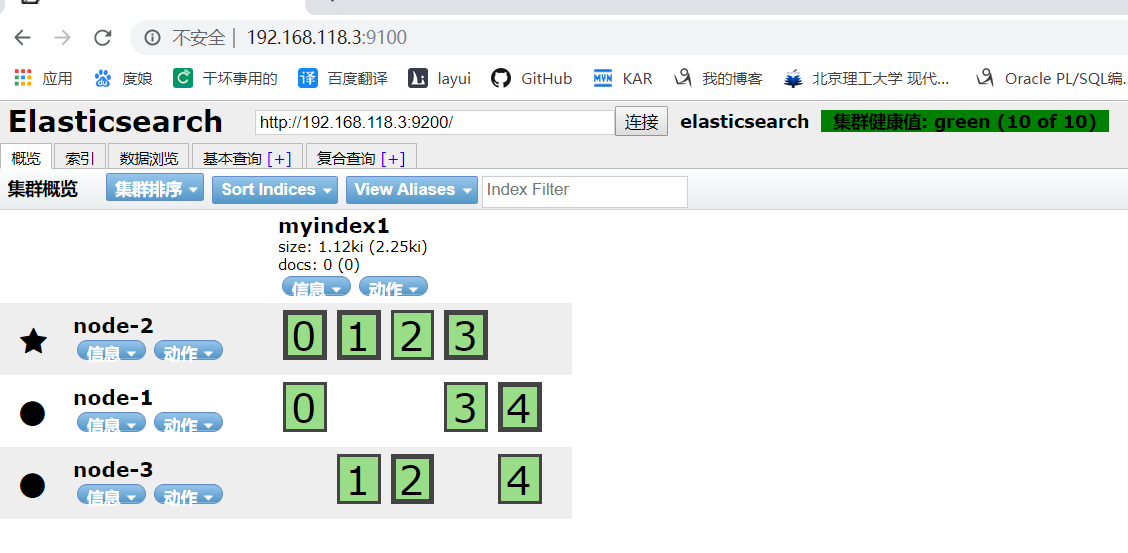
查看索引信息
2.先创建索引然后在设置Mapping(修改)
这种情况也可以当作修改索引库
ElasticSearch是基于Lucene开发的,他的修改的原理也是一样,先删除在添加
只发送请求,不带json请求体
http://192.168.118.3:9200/myindex2
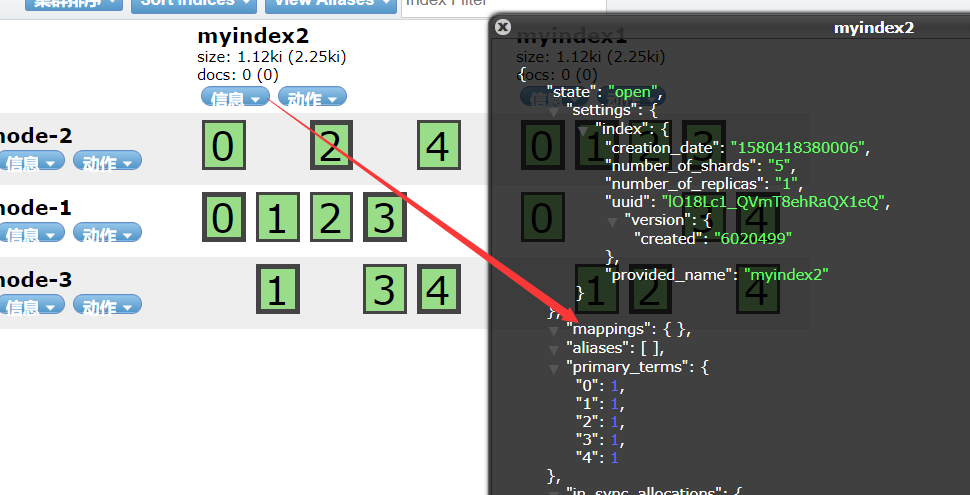
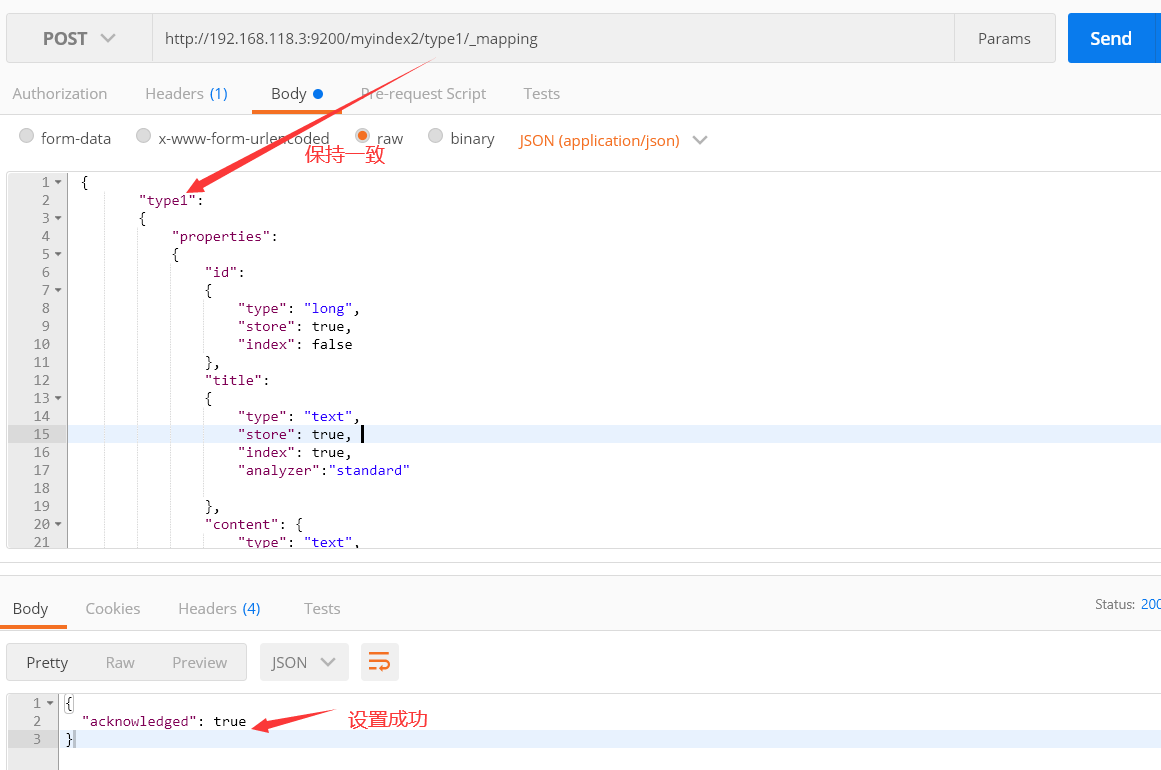
设置mapping的请求,换成POST方式请求
http://192.168.118.3:9200/myindex2/type1/_mapping
请求体中的json串
{ "type1": { "properties": { "id": { "type": "long", "store": true, "index": false }, "title": { "type": "text", "store": true, "index": true, "analyzer":"standard" }, "content": { "type": "text", "store": true, "index": true, "analyzer":"standard" } } } }
请求注意要点(下图)
3.删除索引
删除索引比较简单,把请求方式更改为DELETE

4.创建文档document
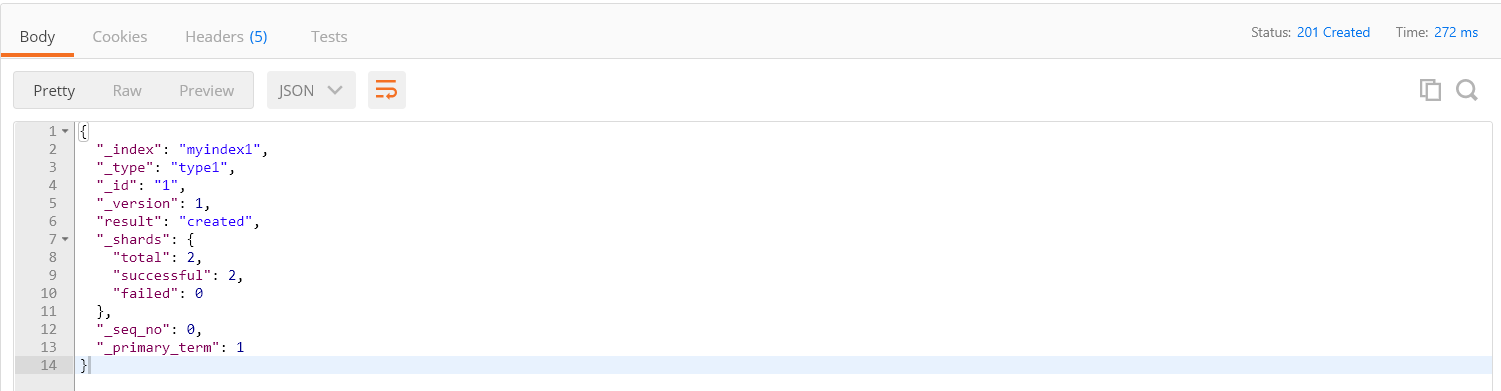
POST请求
http://192.168.118.3:9200/myindex1/type1/1
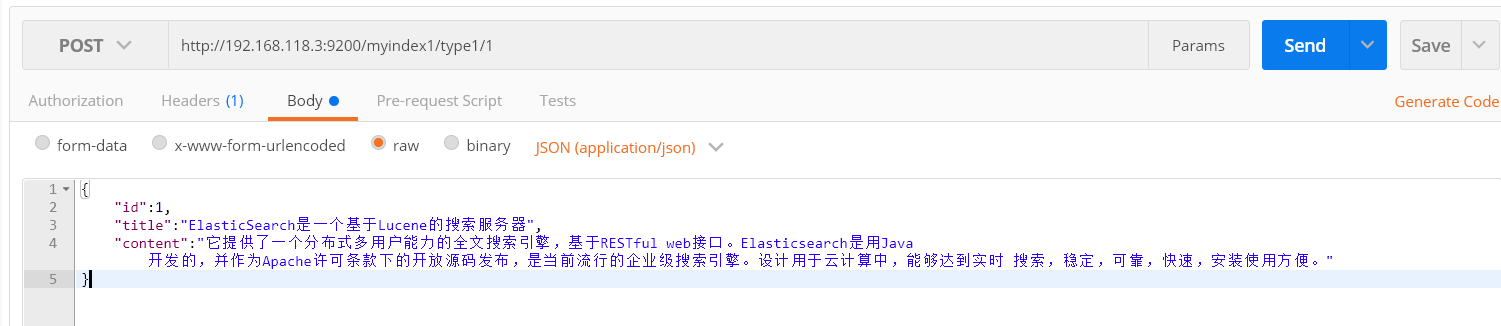
json文档内容
{ "id":1, "title":"ElasticSearch是一个基于Lucene的搜索服务器", "content":"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java 开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时 搜索,稳定,可靠,快速,安装使用方便。" }
响应结果
使用elasticSearch-head查看文档

使用相同的id再次添加视为修改,会覆盖之前的文档
5.删除文档
删除和创建文档的请求一样,只不过不需要json串,只是把请求方式由post更改为DELETE
http://192.168.118.3:9200/myindex1/type1/1
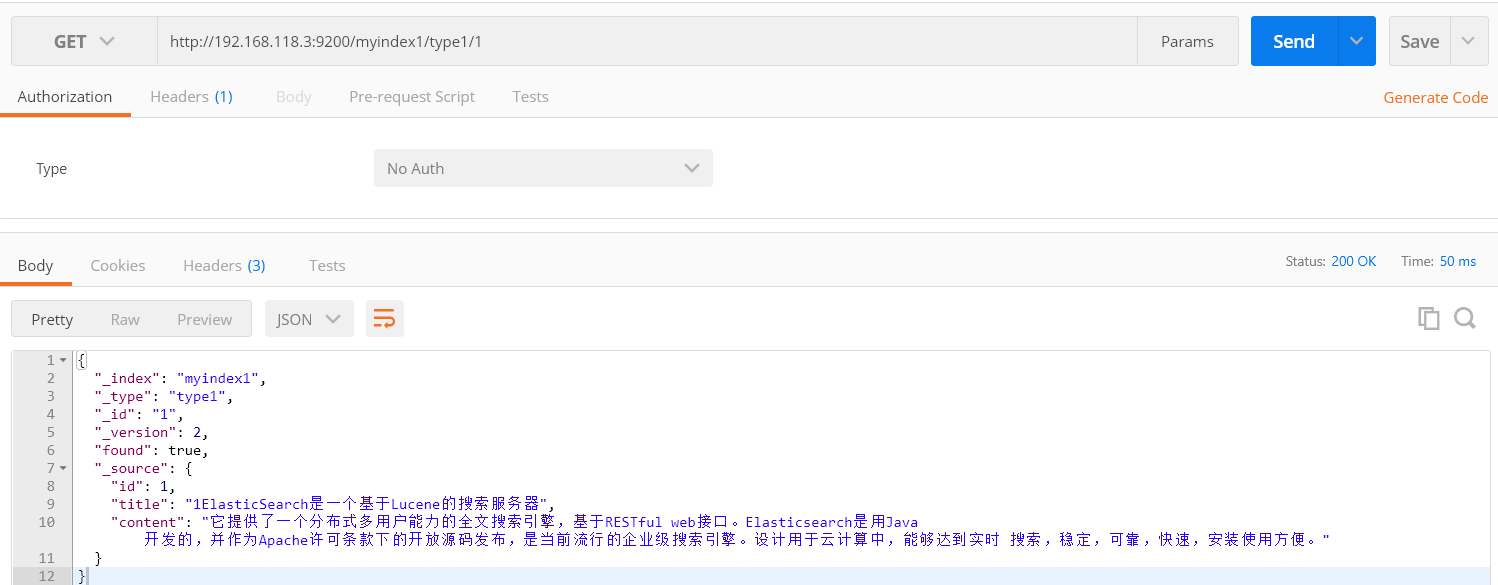
6.根据id查询文档
根据id查询文档请求和添加删除一样,把请求方式更改为GET即可
7.使用querystring查询文档
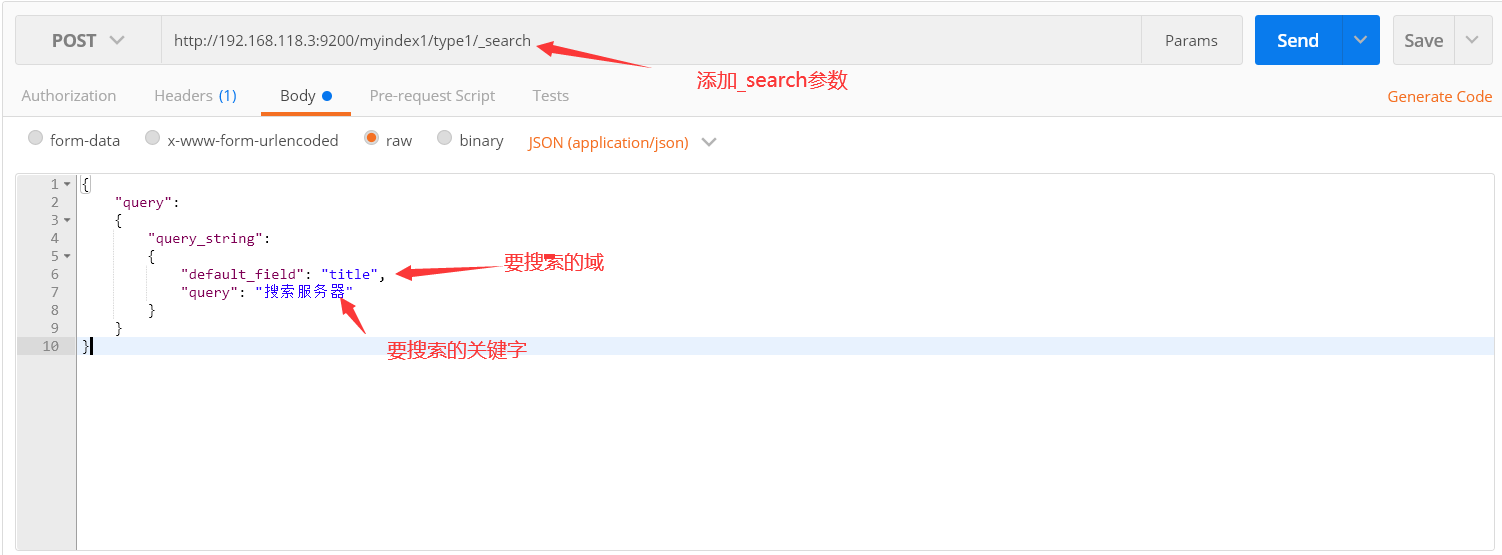
POST请求
http://192.168.118.3:9200/myindex1/type1/_search
请求json
{ "query": { "query_string": { "default_field": "title", "query": "搜索服务器" } } }
default_field:要搜索的域
query:搜索条件
响应结果
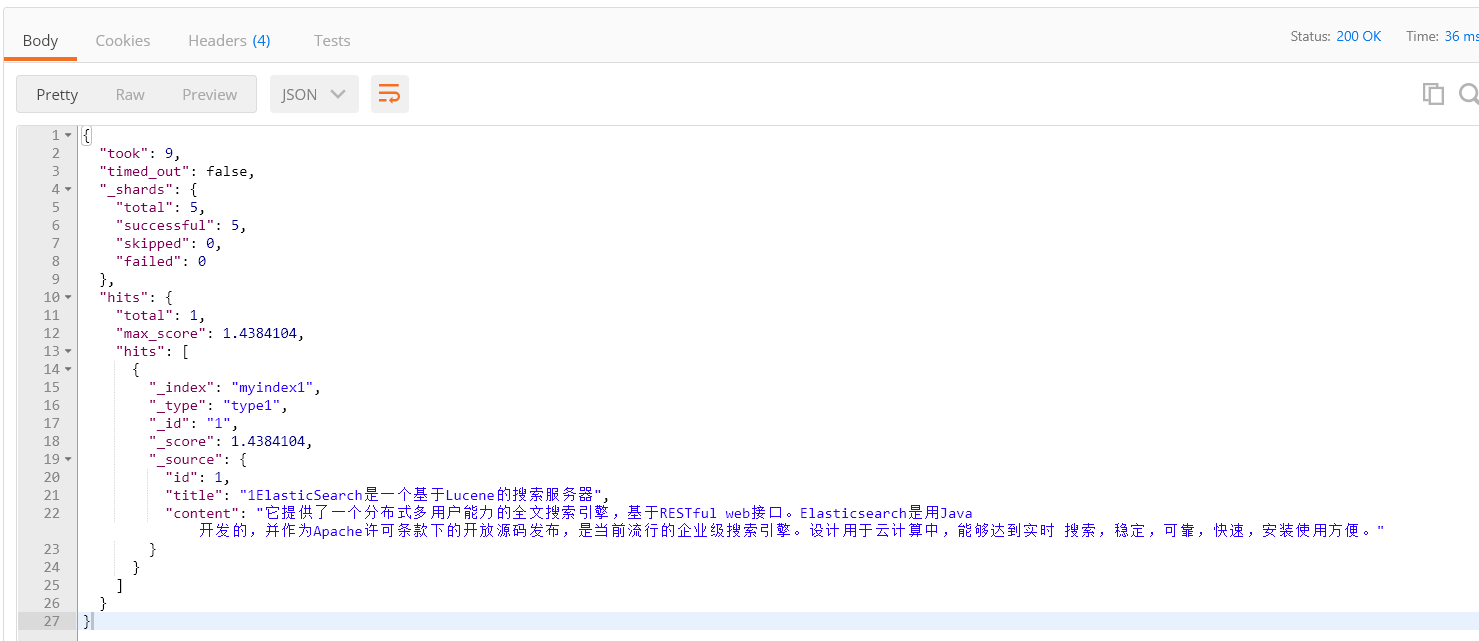
将查询关键字变为"亚索",还是可以查到,应为包含了"索"字,这是应为底层的分析器的原因
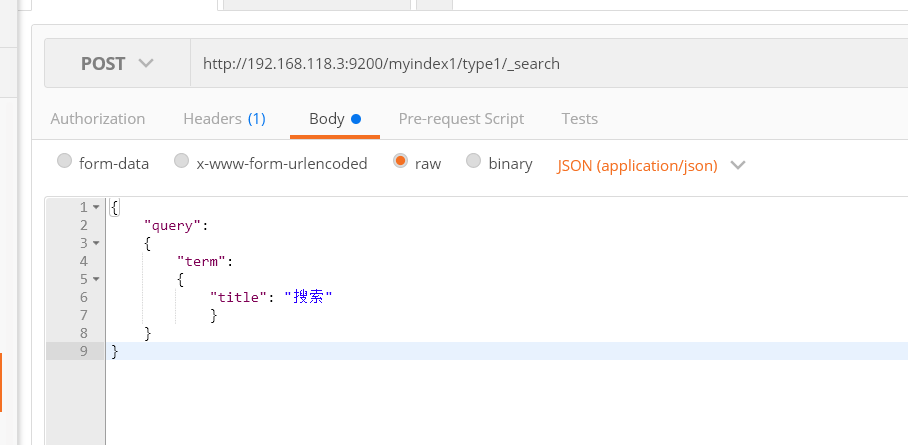
8.使用term查询
将上次发生的json更改为term方式
{ "query": { "term": { "title": "搜索" } } }
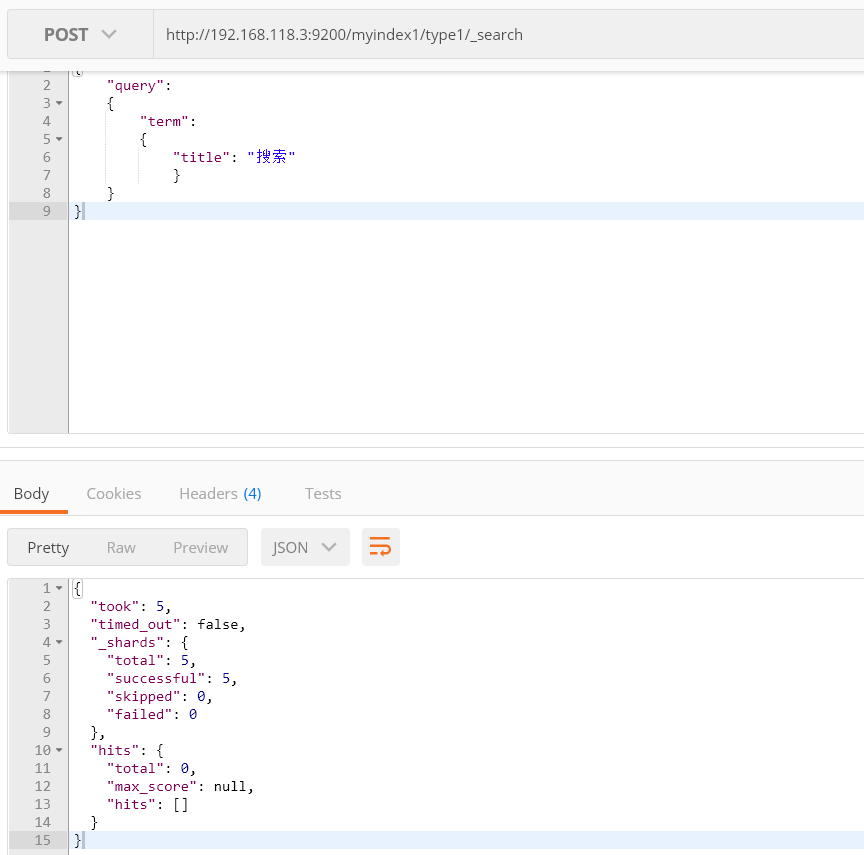
在使用默认的分析器,会把汉字拆分成一个一个的,搜索词语是查询不出来结果的
IK分词器
测试默认的分词器
发生POST请求
http://192.168.118.3:9200/_analyze
JSON
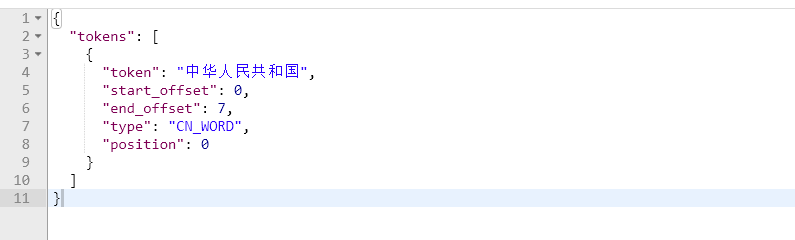
{ "analyzer":"standard", "text":"中华人民共和国" }
分词结果

这样分词效果对于中文文档来说,是我们不能接受的,我们需要使用专门针对于汉字词语进行分词的分词器
我们需要配置IK分词到Elasticsearch中,将ik分词器的包解压到plugins目录下并重新启动ES就好了
IK提供了两个分词算法ik_smart 和 ik_max_word
其中 ik_smart 为最少切分,ik_max_word为最细粒度划分
先来测试一下ik_smart最少切分
请求路径不变更改json
{ "analyzer":"ik_smart", "text":"中华人民共和国" }
分词结果
再测试一下,ik_max_word最细粒度划分
{ "analyzer":"ik_max_word", "text":"中华人民共和国" }
分词结果

接下来使用ik分词器重建索引库,先将之前的索引库删除
{ "type1": { "properties": { "id": { "type": "long", "store": true, "index": false }, "title": { "type": "text", "store": true, "index": true, "analyzer":"ik_max_word" }, "content": { "type": "text", "store": true, "index": true, "analyzer":"ik_max_word" } } } }
然后再添加文档
之后再次执行之前的查找文档
再次搜索"亚索"
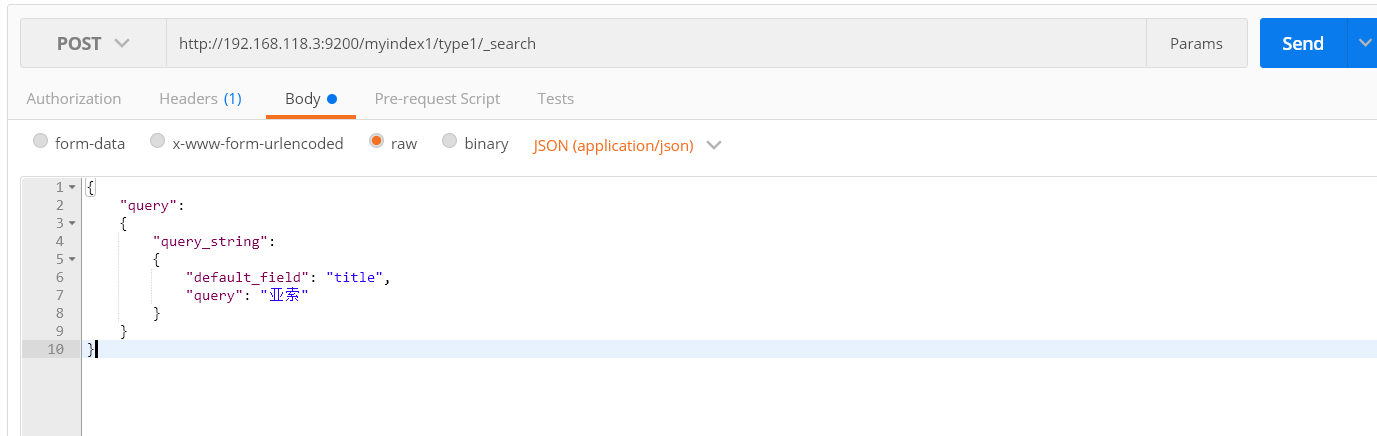
返回结果为空,
再执行之前的trem查询
可以看到正常搜索出来了
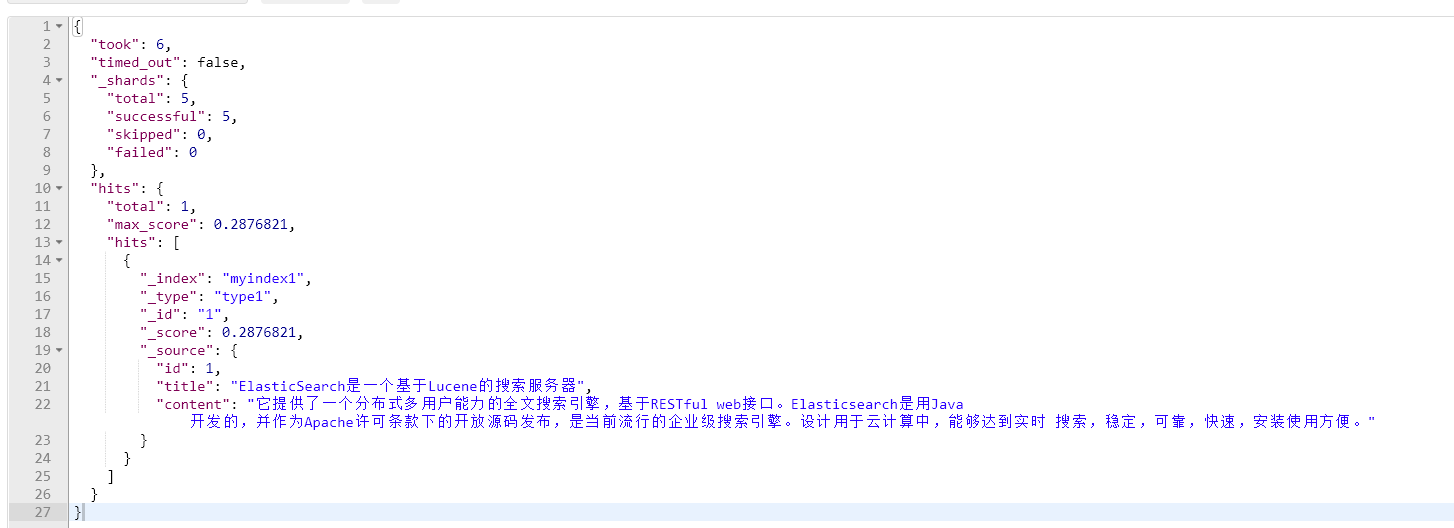
索引库