HBase预分区实战篇
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.HBase预分区概述
每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维护的rowKey范围,则该数据交给这个region维护。那么依照这个原则,我们可以将数据所要投放的分区提前大致的规划好,以提高HBase性能。 预分区是否可以基于时间戳作为ROWKEY? 不推荐基于时间戳来作为ROWKEY,其原因很简单,很容易出现数据倾斜。随着数据量的增大,Region也会被切分,而基于时间戳切分的Region有一个明显特点,前面的Region的数据固定,后面的Region数量不断有数据写入导致数据倾斜现象,从而频繁发生Region的切分。 如何规划预分区? 这需要您对数据的总量有一个判断,举个例子,目前HBase有50亿条数据,每条数据平均大小是10k,那么数据总量大小为5000000000*10k/1024/1024=47683G(约47T).我们假设每个Region可以存储100G的数据,那么要存储到现有数据只需要477个Region足以。 但是这个Region数量仅能存储现有数据,实际情况我们需要预估公司未来5-10年的数量量的增长,比如每年增长10亿条数据,按5年来做预估,那么5年后的数据会增加50亿条数据,因此预估5年后总数居大小为10000000000*10k/1024/1024=95367(约95T)。 综上所述,按照每个Region存储100G的数据,最少需要954个Region,接下来我们就得考虑如何将数据尽量平均的存储在这954个Region中,而不是将数据放在某一个Region中导致数据倾斜的情况发生。
二.手动设置预分区
1>.手动设置预分区


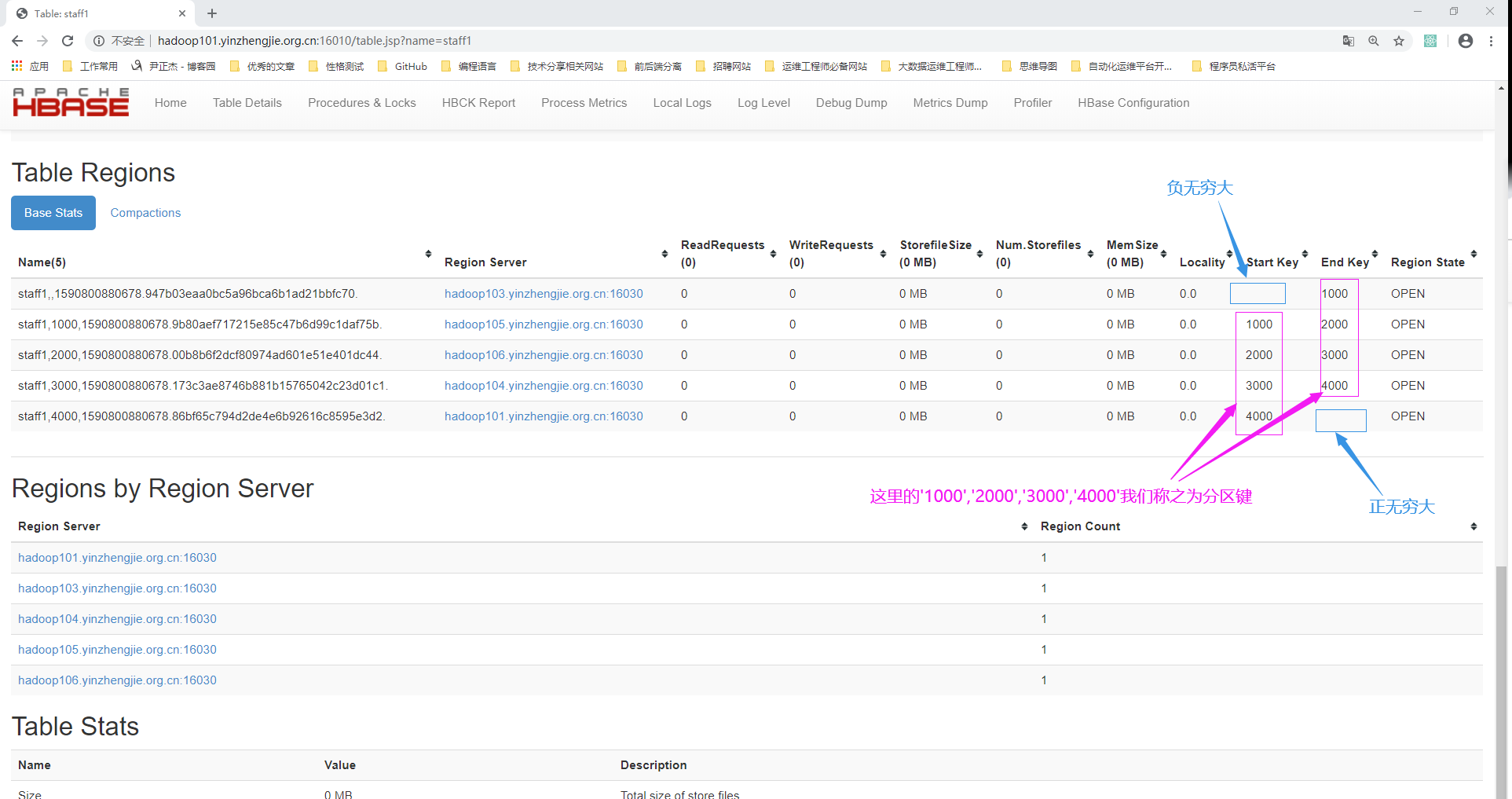
hbase(main):001:0> create 'staff1','info','partition1',SPLITS => ['1000','2000','3000','4000'] Created table staff1 Took 3.0235 seconds => Hbase::Table - staff1 hbase(main):002:0>
hbase(main):006:0> describe 'staff1' Table staff1 is ENABLED staff1 COLUMN FAMILIES DESCRIPTION {NAME => 'info', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTE R => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'} {NAME => 'partition1', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOO MFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'} 2 row(s) QUOTAS 0 row(s) Took 0.0648 seconds hbase(main):007:0>
2>.访问Hmaster的WebUI
浏览器访问HMaster的地址: http://hadoop101.yinzhengjie.org.cn:16010/
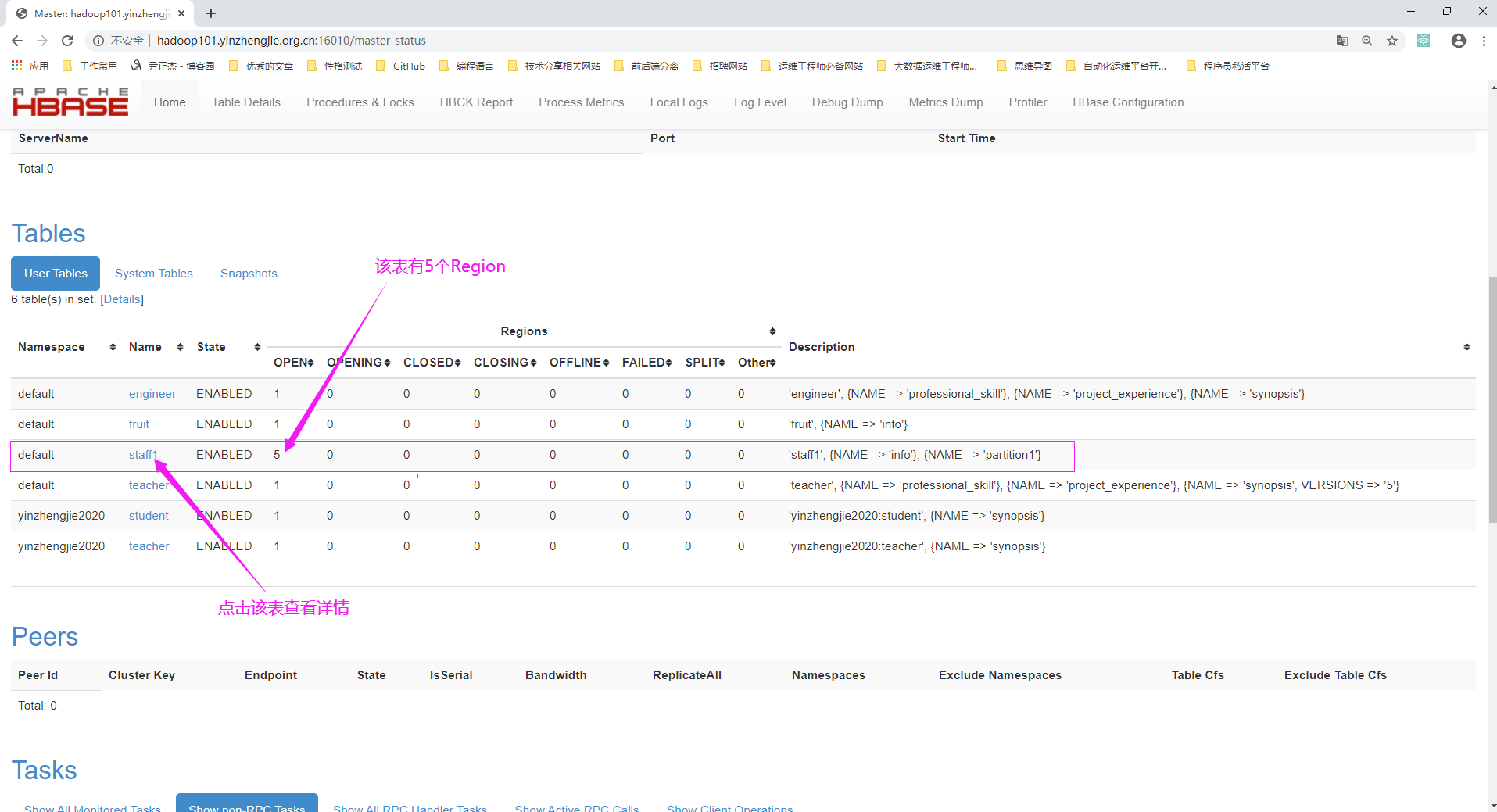
3>.查看staff1表的Region信息
三.生成16进制序列预分区
1>.生成16进制序列预分区
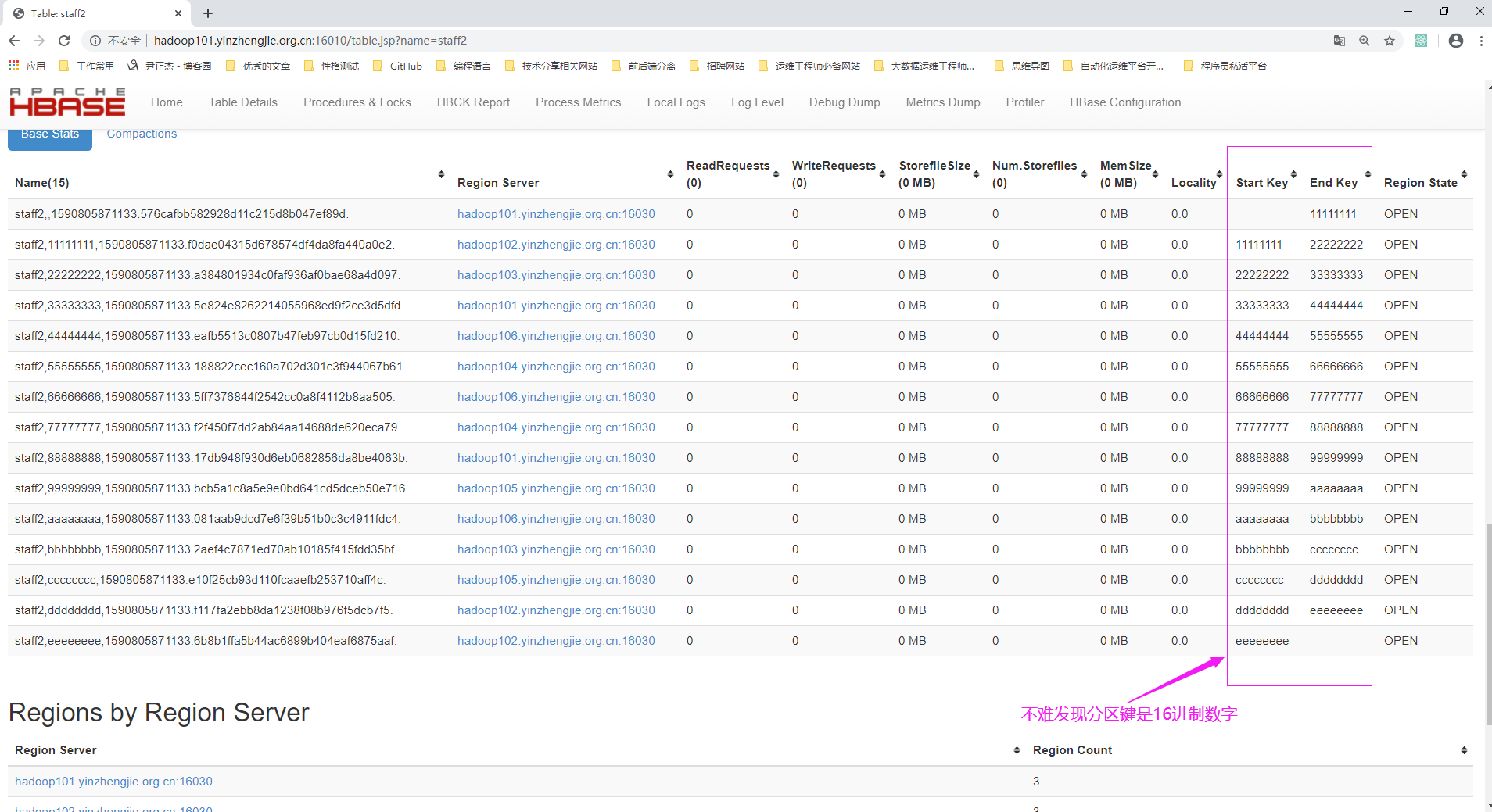
hbase(main):007:0> create 'staff2','info','partition2',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'} Created table staff2 Took 2.4445 seconds => Hbase::Table - staff2 hbase(main):008:0>
hbase(main):008:0> describe 'staff2' Table staff2 is ENABLED staff2 COLUMN FAMILIES DESCRIPTION {NAME => 'info', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTE R => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'} {NAME => 'partition2', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOO MFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'} 2 row(s) QUOTAS 0 row(s) Took 0.0880 seconds hbase(main):009:0>
2>.访问Hmaster的WebUI
浏览器访问HMaster的地址: http://hadoop101.yinzhengjie.org.cn:16010/
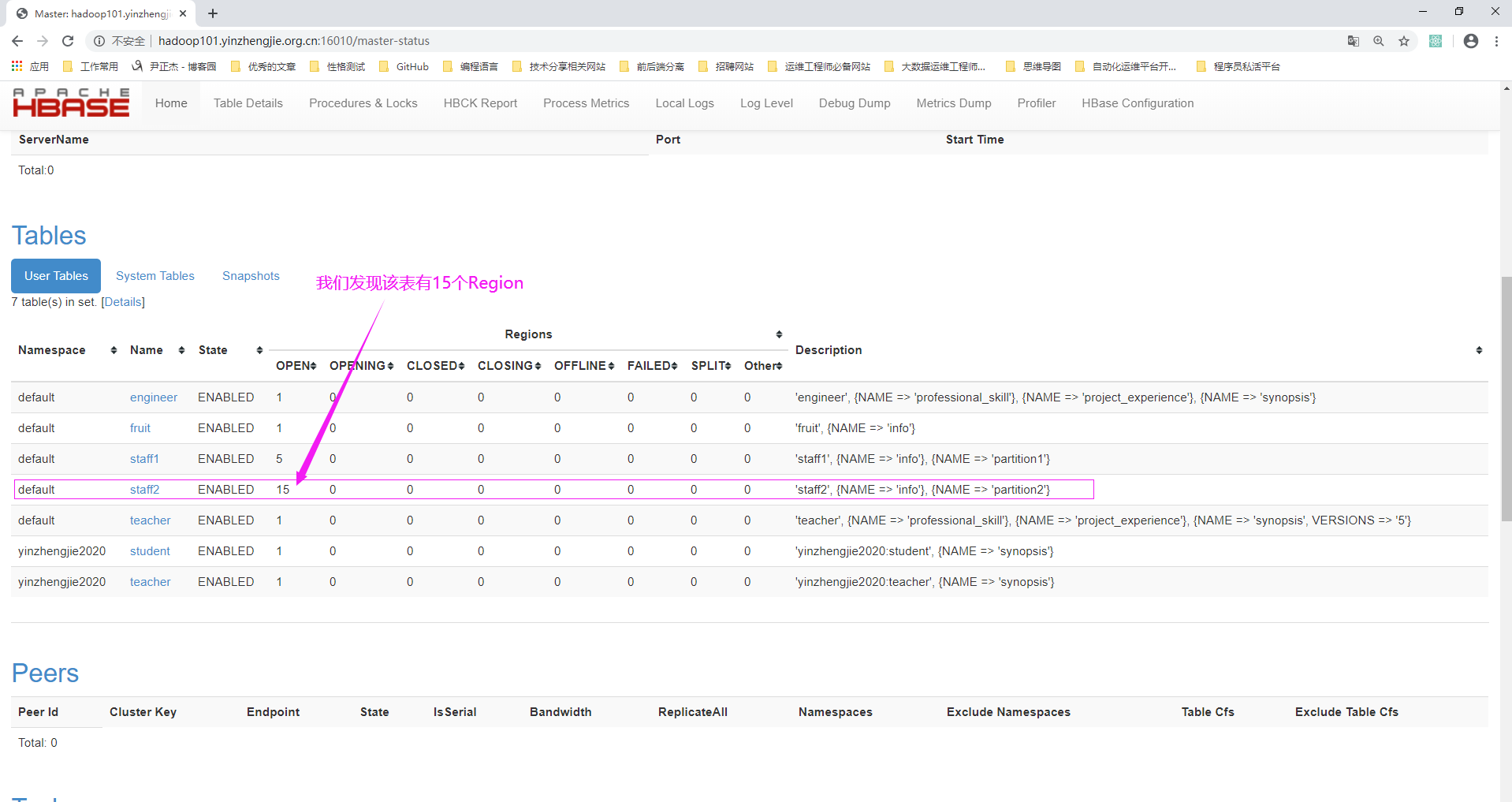
3>.查看staff2表的Region信息
四.按照文件中设置的规则预分区
1>.按照文件中设置的规则预分区
[root@hadoop101.yinzhengjie.org.cn ~]# vim splits.txt [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# cat splits.txt AAAAA BBBBB CCCCC DDDDD EEEEE [root@hadoop101.yinzhengjie.org.cn ~]#
hbase(main):009:0> create 'staff3','partition3',SPLITS_FILE => 'splits.txt' Created table staff3 Took 2.3140 seconds => Hbase::Table - staff3 hbase(main):010:0>
hbase(main):010:0> describe 'staff3' Table staff3 is ENABLED staff3 COLUMN FAMILIES DESCRIPTION {NAME => 'partition3', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOO MFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'} 1 row(s) QUOTAS 0 row(s) Took 0.0955 seconds hbase(main):011:0>
2>.访问Hmaster的WebUI
浏览器访问HMaster的地址: http://hadoop101.yinzhengjie.org.cn:16010/
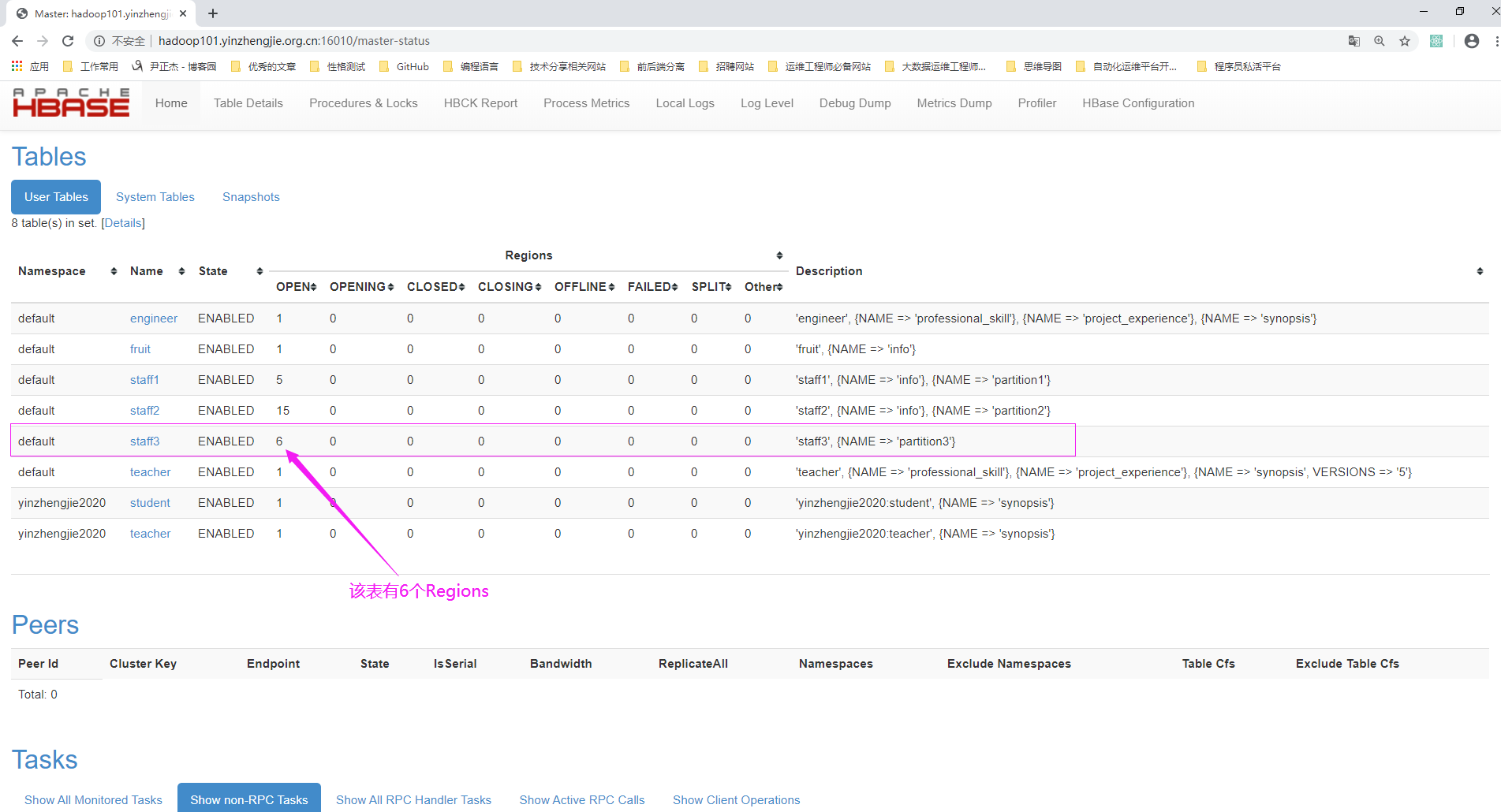
3>.查看staff3表的Region信息

五.基于JavaAPI创建预分区
1>.自定义生成3个Region的预分区表
package cn.org.yinzhengjie.bigdata.hbase.util; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Table; import org.apache.hadoop.hbase.util.Bytes; import java.io.IOException; /** * HBase操作工具类 */ public class HBaseUtil { //创建ThreadLocal对象(会在各个线程里单独开辟一块共享内存空间),目的是为了同一个线程内实现数据共享,它的作用并不是解决线程安全问题哟~ private static ThreadLocal<Connection> connHolder = new ThreadLocal<Connection>(); /** * 将构造方法私有化,禁止该工具类被实例化 */ private HBaseUtil(){} /** * 获取HBase连接对象 */ public static void makeHbaseConnection() throws IOException { //获取连接 Connection conn = connHolder.get(); //第一次获取连接为空,因此需要手动创建Connection对象 if (conn == null){ //使用HBaseConfiguration的单例方法实例化,该方法会自动帮咱们加载"hbase-default.xml"和"hbase-site.xml"文件. Configuration conf = HBaseConfiguration.create(); conn = ConnectionFactory.createConnection(conf); connHolder.set(conn); } } /** * 增加数据 */ public static void insertData (String tableName, String rowKey, String columnFamily, String column, String value) throws IOException{ //获取连接 Connection conn = connHolder.get(); //获取表 Table table = conn.getTable(TableName.valueOf(tableName)); //创建Put对象,需要指定往哪个"RowKey"插入数据 Put put = new Put(Bytes.toBytes(rowKey)); //记得添加列族信息 put.addColumn(Bytes.toBytes(columnFamily),Bytes.toBytes(column),Bytes.toBytes(value)); //执行完这行代码数据才会被真正写入到HBase哟~ table.put(put); //记得关闭表 table.close(); } /** * 关闭连接 */ public static void close() throws IOException { //获取连接 Connection conn = connHolder.get(); if (conn != null){ conn.close(); //关闭连接后记得将其从ThreadLocal的内存中移除以释放空间。 connHolder.remove(); } } /** * 生成分区键 */ public static byte[][] genRegionKeys(int regionCount){ //设置3个Region就会生成2分区键 byte[][] bs = new byte[regionCount -1][]; for (int i = 0;i<regionCount -1;i++){ bs[i] = Bytes.toBytes(i + "|"); } return bs; } /** * 生成分区号 */ public static String genRegionNumber(String rowkey,int regionCount){ //计算分区号 int regionNumber; //获取一个散列值 int hash = rowkey.hashCode(); /** * (regionCount & (regionCount - 1)) == 0 : * 用于判断regionCount这个数字是否是2的N次方: * 如果是则将该数字减去1和hash值做与运算(&)目的是可以随机匹配到不同的分区号; * 如果不是则将该数字和hash值做取余运算(%)目的也是可以随机匹配到不同的分区号; */ if (regionCount > 0 && (regionCount & (regionCount - 1)) == 0){ // (regionCount -1)算的是分区键,举个例子:分区数为3,则分区键为2. regionNumber = hash & (regionCount -1); }else { regionNumber = hash % regionCount; } return regionNumber + "_" + rowkey; } }
package cn.org.yinzhengjie.bigdata.hbase; import cn.org.yinzhengjie.bigdata.hbase.util.HBaseUtil; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Admin; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.util.Bytes; import java.io.IOException; public class PrePartition { public static void main(String[] args) throws IOException { //创建配置对象 Configuration conf = HBaseConfiguration.create(); //获取HBase的连接对象 Connection conn = ConnectionFactory.createConnection(conf); //获取管理Hbase的对象 Admin admin = conn.getAdmin(); //获取表对象 HTableDescriptor td = new HTableDescriptor(TableName.valueOf("yinzhengjie2020:course1")); //为表设置列族 HColumnDescriptor cd = new HColumnDescriptor("info"); td.addFamily(cd); //设置3个Region就会生成2分区键 byte[][] spiltKeys = HBaseUtil.genRegionKeys(3); for (byte[] spiltKey : spiltKeys) { System.out.println(Bytes.toString(spiltKey)); } //创建表并指定分区键(二维数组)可用增加预分区 admin.createTable(td,spiltKeys); System.out.println("预分区表创建成功...."); //释放资源 admin.close(); conn.close(); } }
2>.查看WebUI
浏览器访问: http://hadoop105.yinzhengjie.org.cn:16010/table.jsp?name=yinzhengjie2020:course
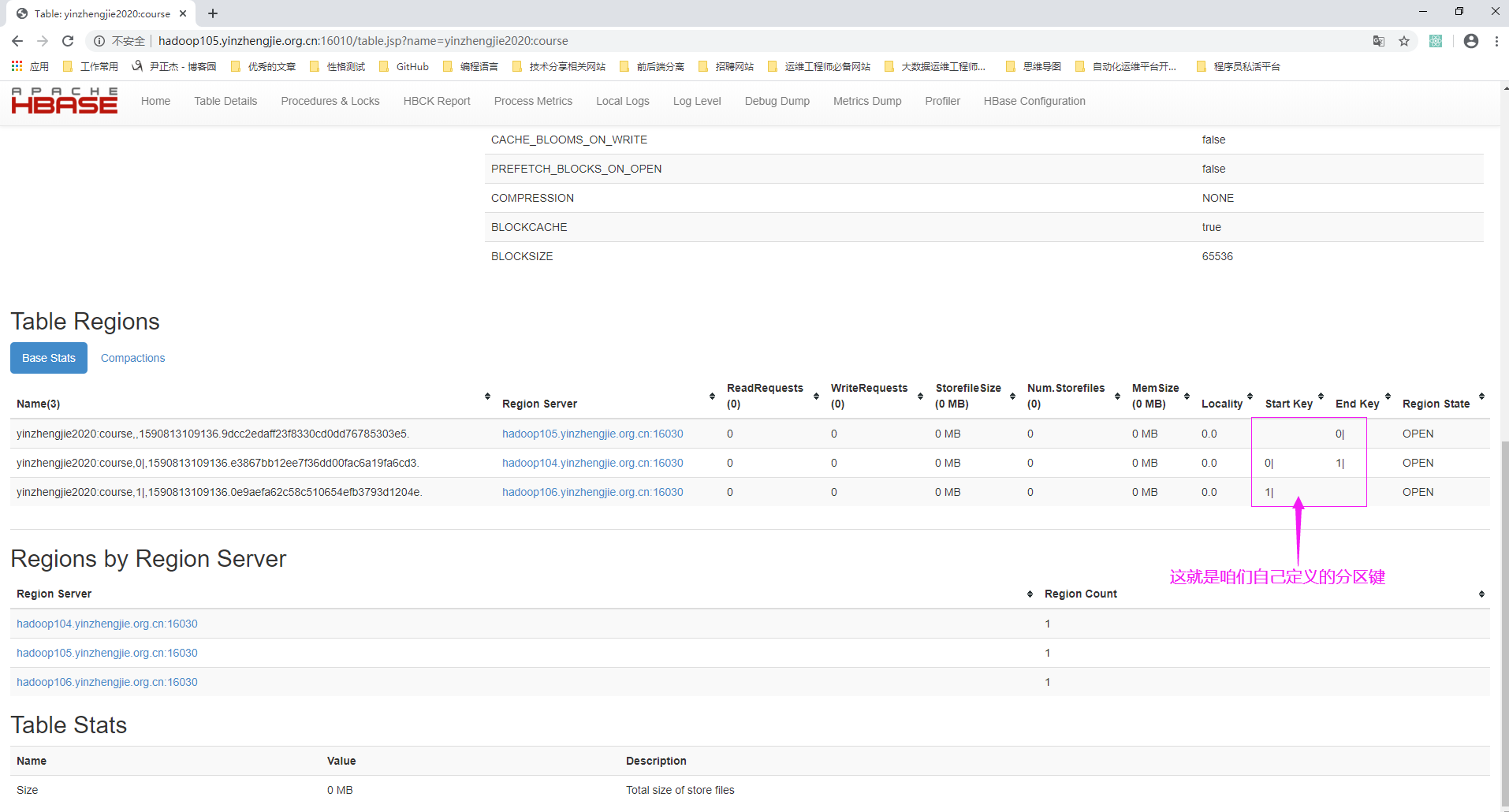
3>.往自定义的分区插入数据
package cn.org.yinzhengjie.bigdata.hbase.util; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Table; import org.apache.hadoop.hbase.util.Bytes; import java.io.IOException; /** * HBase操作工具类 */ public class HBaseUtil { //创建ThreadLocal对象(会在各个线程里单独开辟一块共享内存空间),目的是为了同一个线程内实现数据共享,它的作用并不是解决线程安全问题哟~ private static ThreadLocal<Connection> connHolder = new ThreadLocal<Connection>(); /** * 将构造方法私有化,禁止该工具类被实例化 */ private HBaseUtil(){} /** * 获取HBase连接对象 */ public static void makeHbaseConnection() throws IOException { //获取连接 Connection conn = connHolder.get(); //第一次获取连接为空,因此需要手动创建Connection对象 if (conn == null){ //使用HBaseConfiguration的单例方法实例化,该方法会自动帮咱们加载"hbase-default.xml"和"hbase-site.xml"文件. Configuration conf = HBaseConfiguration.create(); conn = ConnectionFactory.createConnection(conf); connHolder.set(conn); } } /** * 增加数据 */ public static void insertData (String tableName, String rowKey, String columnFamily, String column, String value) throws IOException{ //获取连接 Connection conn = connHolder.get(); //获取表 Table table = conn.getTable(TableName.valueOf(tableName)); //创建Put对象,需要指定往哪个"RowKey"插入数据 Put put = new Put(Bytes.toBytes(rowKey)); //记得添加列族信息 put.addColumn(Bytes.toBytes(columnFamily),Bytes.toBytes(column),Bytes.toBytes(value)); //执行完这行代码数据才会被真正写入到HBase哟~ table.put(put); //记得关闭表 table.close(); } /** * 关闭连接 */ public static void close() throws IOException { //获取连接 Connection conn = connHolder.get(); if (conn != null){ conn.close(); //关闭连接后记得将其从ThreadLocal的内存中移除以释放空间。 connHolder.remove(); } } /** * 生成分区键 */ public static byte[][] genRegionKeys(int regionCount){ //设置3个Region就会生成2分区键 byte[][] bs = new byte[regionCount -1][]; for (int i = 0;i<regionCount -1;i++){ bs[i] = Bytes.toBytes(i + "|"); } return bs; } /** * 生成分区号 */ public static String genRegionNumber(String rowkey,int regionCount){ //计算分区号 int regionNumber; //获取一个散列值 int hash = rowkey.hashCode(); /** * (regionCount & (regionCount - 1)) == 0 : * 用于判断regionCount这个数字是否是2的N次方: * 如果是则将该数字减去1和hash值做与运算(&)目的是可以随机匹配到不同的分区号; * 如果不是则将该数字和hash值做取余运算(%)目的也是可以随机匹配到不同的分区号; */ if (regionCount > 0 && (regionCount & (regionCount - 1)) == 0){ // (regionCount -1)算的是分区键,举个例子:分区数为3,则分区键为2. regionNumber = hash & (regionCount -1); }else { regionNumber = hash % regionCount; } return regionNumber + "_" + rowkey; } }
package cn.org.yinzhengjie.bigdata.hbase; import cn.org.yinzhengjie.bigdata.hbase.util.HBaseUtil; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.util.Bytes; import java.io.IOException; public class InsertPrePartition { public static void main(String[] args) throws IOException { //创建配置对象 Configuration conf = HBaseConfiguration.create(); //获取HBase的连接对象 Connection conn = ConnectionFactory.createConnection(conf); //获取管理Hbase的对象 Admin admin = conn.getAdmin(); //获取要操作的表对象 Table courseTable = conn.getTable(TableName.valueOf("yinzhengjie2020:course")); //编辑待插入数据,将rowkey均匀分配到不同的分区中,效果可以模拟HashMap数据存储的规则。 String rowkey = "yinzhengjie8"; rowkey = HBaseUtil.genRegionNumber(rowkey, 3); Put put = new Put(Bytes.toBytes(rowkey)); put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("age"),Bytes.toBytes(20)); //往表中插入数据 courseTable.put(put); System.out.println("数据插入成功......"); } }