Apache Hadoop HDFS HA原理刨析
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.HDFS High Available概述
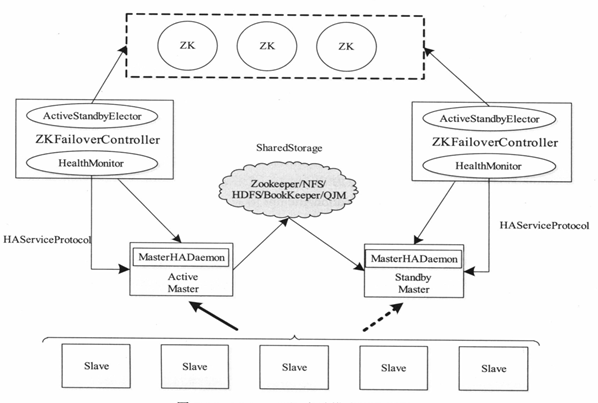
在Hadoop2.0之前,在HDFS集群中NameNode存在单点故障(SPOF)。所谓HA(全称High Available),即高可用。换句话说,7*24小时不中断服务。实现高可用最关键的策略是消除单点故障。HA严格来说应该分成各个组件的HA机制,即HDFS的HA和YARN的HA。 NameNode主要在以下两个方面影响HDFS集群 1>.NameNode机器发生意外,如宕机,集群将无法使用,直到管理员重启。 2>.NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用。 HDFS HA功能通过配置Active/Standby两个NameNodes实现在集群中对NameNode的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器。 HDFS HA的工作要点如下: 1>.元数据管理方式需要改变 (a)两个NameNode内存中各自保存一份元数据(FSImage); (b)Edits日志只有Active状态的NameNode节点可以做写操作; (c)两个NameNode都可以读取Edits; (d)共享的Edits放在一个共享存储中管理(qjournal和NFS两个主流实现); 2>.需要一个状态管理功能模块 实现了一个zkfailover,常驻在每一个namenode所在的节点。 每一个zkfailover负责监控自己所在NameNode节点,利用zk进行状态标识,当需要进行状态切换时,由zkfailover来负责切换,切换时需要防止脑裂(brain split)现象的发生。 3>.必须保证两个NameNode之间能够ssh无密码登录 4>.隔离(Fence),即同一时刻仅仅有一个NameNode对外提供服务 温馨提示: 主备切换控制器(ZKFailoverController): ZKFailoverController作为独立的进程运行,对NameNode的主备切换进行总体控制。 ZKFailoverController能及时检测到NameNode 健康状况,在主NameNode故障时借助Zookeeper实现自动的主备选举和切换,当然NameNode目前也支持不依赖于Zookeeper的手动主备切换。 Zookeeper集群: 为主备切换控制器提供主备选举支持。 共享存储系统: 共享存储系统是实现NameNode的高可用最为关键的部分,共享存储系统保存了NameNode在运行过程中所产生的HDFS的元数据。 Active NameNode和Standby NameNode通过共享存储系统实现元数据同步。在进行主备切换的时候,新的Active NameNode在确认元数据完全同步之后才能继续对外提供服务。 目前官方支持两个主流的文件共享存储的方式,即qjournal和NFS,但实际生产换句中使用前者较多,后者寥寥无几,博主认为的原因如下: (1)NFS文件系统存在单点故障 (2)虽然说可以通过rsync来实现对数据的备份,但稳定性相对较差,没有qjournal分布式文件系统的可靠性强。 DataNode节点: 除了通过共享存储系统共享HDFS的元数据信息之外,主NameNode和备NameNode还需要共享HDFS的数据块和DataNode之间的映射关系。换句话说,DataNode会同时向主NameNode和备NameNode上报数据块的位置信息。
二.基于QJM的共享存储
1>.基于QJM的共享存储系统主要用于保存 EditLog,并不保存FSImage文件
FSImage文件还是在NameNode的本地磁盘上。QJM共享存储的基本思想来自于Paxos算法,采用多个称为JournalNode的节点组成的JournalNode集群来存储EditLog。每个JournalNode保存同样的EditLog副本。
每次NameNode写EditLog的时候,除了向本地磁盘写入EditLog之外,也会并行地向JournalNode集群之中的每一个JournalNode发送写请求,只要大多数(majority)的JournalNode节点返回成功就认为向JournalNode集群写入EditLog成功。
温馨提示:
如果有2N+1台JournalNode服务器节点,那么根据大多数的原则,最多可以容忍有N台JournalNode节点挂掉。
2>.QJM组件介绍
FSEditLog: 这个类封装了对EditLog的所有操作,是NameNode对EditLog的所有操作的入口。 JournalSet: 这个类封装了对本地磁盘和JournalNode集群上的EditLog的操作,内部包含了两类JournalManager(FSEditLog只会调用JournalSet的相关方法,而不会直接使用FileJournalManager和QuorumJournalManager。): (1)FileJournalManager: 封装了对本地磁盘上的EditLog文件的操作。 不仅NameNode在向本地磁盘上写入EditLog的时候使用FileJournalManager,JournalNode在向本地磁盘写入EditLog的时候也复用了FileJournalManager的代码和逻辑。 (2)QuorumJournalManager: 封装了对JournalNode集群上共享目录的EditLog的操作。 它会根据JournalNode集群的URI创建负责与JournalNode集群通信的类AsyncLoggerSet。 QuorumJournalManager通过AsyncLoggerSet来实现对JournalNode集群上的EditLog的写操作,对于读操作,QuorumJournalManager则是通过Http接口从JournalNode上的JournalNodeHttpServer读取EditLog的数据。 温馨提示: AsyncLoggerSet: 内部包含了与JournalNode集群进行通信的AsyncLogger列表. 每一个AsyncLogger对应于一个JournalNode节点,另外AsyncLoggerSet也包含了用于等待大多数JournalNode返回结果的工具类方法给QuorumJournalManager使用。 AsyncLogger: 具体的实现类是IPCLoggerChannel,IPCLoggerChannel在执行方法调用的时候,会把调用提交到一个单线程的线程池之中,由线程池线程来负责向对应的JournalNode的JournalNodeRpcServer发送RPC请求。 JournalNodeRpcServer: 运行在JournalNode节点进程中的RPC服务,接收NameNode端的AsyncLogger的RPC请求。 JournalNodeHttpServer: 运行在JournalNode节点进程中的Http服务,用于接收处于Standby状态的NameNode和其它JournalNode的同步EditLog文件流的请求。
3>.Active NameNode提交EditLog到JournalNode集群
当处于Active状态的NameNode调用FSEditLog类的logSync方法来提交EditLog的时候,会通过JouranlSet同时向本地磁盘目录和JournalNode集群上的共享存储目录写入EditLog。
写入JournalNode集群是通过并行调用每一个JournalNode的QJournalProtocol RPC接口的journal方法实现的,如果对大多数JournalNode的journal方法调用成功,那么就认为提交EditLog成功,否则NameNode就会认为这次提交EditLog失败。
提交EditLog失败会导致Active NameNode关闭JournalSet之后退出进程,留待处于Standby状态的NameNode接管之后进行数据恢复。
综上所述,Active NameNode提交EditLog到JournalNode集群的过程实际上是同步阻塞的,但是并不需要所有的JournalNode都调用成功,只要大多数JournalNode调用成功就可以了。如果无法形成大多数,那么就认为提交EditLog 失败,NameNode停止服务退出进程。如果对应到分布式系统的CAP理论的话,虽然采用了Paxos的“大多数”思想对C(consistency,一致性)和A(availability,可用性)进行了折衷,但还是可以认为NameNode选择C而放弃了A,这也符合NameNode 对数据一致性的要求。
4>.Standby NameNode从JournalNode集群同步EditLog
当NameNode进入Standby状态之后,会启动一个EditLogTailer线程。这个线程会定期调用EditLogTailer类的doTailEdits方法从JournalNode集群上同步EditLog,然后把同步的EditLog回放到内存之中的文件系统镜像上(并不会同时把EditLog 写入到本地磁盘上)。 从JournalNode集群上同步的EditLog都是处于finalized状态的EditLog Segment(实际上有两种状态,还记得以"edits_*(finalized状态)"和"edits_inprogress_*(中间状态)"开头的编辑日志吗?)。 Active NameNode在完成一个EditLog Segment的写入之后,就会向JournalNode集群发送finalizeLogSegment RPC请求,将完成写入的EditLog Segment finalized,然后开始下一个新的EditLog Segment。一旦finalizeLogSegment方法在大多数的JournalNode上调用成功,表明这个EditLog Segment已经在大多数的JournalNode上达成一致。一个EditLog Segment处于finalized状态之后,可以保证它再也不会变化。 温馨提示: 虽然Active NameNode向JournalNode集群提交EditLog是同步的,但Standby NameNode采用的是定时从JournalNode集群上同步EditLog的方式,那么Standby NameNode内存中文件系统镜像有很大的可能是落后于Active NameNode的,所以Standby NameNode在转换为Active NameNode的时候需要把落后的EditLog补上来。
5>.基于QJM的共享存储系统的数据恢复机制分析
处于Standby状态的NameNode转换为Active状态的时候,有可能上一个Active NameNode发生了异常退出,那么JournalNode集群中各个JournalNode上的EditLog就可能会处于不一致的状态,所以首先要做的事情就是让JournalNode 集群中各个节点上的EditLog恢复为一致。
当前处于Standby状态的NameNode的内存中的文件系统镜像有很大的可能是落后于旧的Active NameNode的,所以在JournalNode集群中各个节点上的EditLog达成一致之后,接下来要做的事情就是从JournalNode集群上补齐落后的 EditLog。
只有完成上述两步之后,当前新的Active NameNode才能安全地对外提供服务。
6>.NameNode在进行状态转换时对共享存储的处理
NameNode初始化启动,进入Standby状态: (1)在NameNode以HA模式启动的时候,NameNode会认为自己处于Standby模式,在NameNode的构造函数中会加载FSImage文件和EditLog Segment文件来恢复自己的内存文件系统镜像; (2)在加载EditLog Segment的时候,调用FSEditLog类的initSharedJournalsForRead方法来创建只包含了在JournalNode集群上的共享目录的JournalSet,也就是说,这个时候只会从JournalNode集群之中加载EditLog,而不会加载本地磁盘上的EditLog。另外值得注意的是,加载的EditLog Segment只是处于finalized状态的EditLog Segment,而处于in-progress状态的Segment需要后续在切换为Active状态的时候,进行一次数据恢复过程,将in-progress状态的Segment转换为finalized状态的 Segment之后再进行读取; (3)加载完FSImage文件和共享目录上的EditLog Segment文件之后,NameNode会启动EditLogTailer线程和StandbyCheckpointer线程,正式进入Standby模式。EditLogTailer线程的作用是定时从JournalNode集群上同步EditLog。而 StandbyCheckpointer线程的作用其实是为了替代Hadoop 1.x版本之中的Secondary NameNode的功能,StandbyCheckpointer线程会在Standby NameNode节点上定期进行Checkpoint,将Checkpoint之后的FSImage文件上传到Active NameNode节点; NameNode从Standby状态切换为Active状态: (1)当NameNode从Standby状态切换为Active状态的时候,首先需要做的就是停止它在Standby状态的时候启动的线程和相关的服务,包括上面提到的EditLogTailer线程和StandbyCheckpointer线程; (2)然后关闭用于读取JournalNode集群的共享目录上的 EditLog的JournalSet,接下来会调用FSEditLog的initJournalSetForWrite方法重新打开JournalSet(不同的是,这个JournalSet内部同时包含了本地磁盘目录和JournalNode集群上的共享目录); (3)这些工作完成之后,调用FSEditLog类的recoverUnclosedStreams方法让JournalNode集群中各个节点上的EditLog达成一致; (4)然后调用EditLogTailer类的catchupDuringFailover方法从JournalNode集群上补齐落后的EditLog; (5)最后打开一个新的EditLog Segment用于新写入数据,同时启动Active NameNode所需要的线程和服务。 NameNode从Active状态切换为Standby状态 (1)当NameNode从Active状态切换为Standby状态的时候,首先需要做的就是停止它在Active状态的时候启动的线程和服务; (2)然后关闭用于读取本地磁盘目录和JournalNode集群上的共享目录的EditLog的JournalSet; (3)接下来会调用FSEditLog的initSharedJournalsForRead方法重新打开用于读取JournalNode集群上的共享目录的JournalSet; (4)上述工作完成之后,就会启动EditLogTailer线程和StandbyCheckpointer线程,EditLogTailer线程会定时从JournalNode集群上同步Edit Log。
三.HDFS HA自动故障转移工作机制

1>.主备切换流程
NameNode 实现主备切换的流程如上图所示,有以下几步: 1>.HealthMonitor初始化完成之后会启动内部的线程来定时调用对应NameNode的HAServiceProtocol RPC接口的方法,对NameNode的健康状态进行检测; 2>.HealthMonitor如果检测到NameNode的健康状态发生变化,会回调ZKFailoverController注册的相应方法进行处理; 3>.如果ZKFailoverController判断需要进行主备切换,会首先使用ActiveStandbyElector来进行自动的主备选举; 4>.ActiveStandbyElector与Zookeeper进行交互完成自动的主备选举; 5>.ActiveStandbyElector在主备选举完成后,会回调ZKFailoverController的相应方法来通知当前的NameNode成为主NameNode或备NameNode; 6>.ZKFailoverController调用对应NameNode的HAServiceProtocol RPC接口的方法将NameNode转换为Active状态或Standby状态;
2>.HealthMonitor实现分析
ZKFailoverController在初始化的时候会创建HealthMonitor,HealthMonitor在内部会启动一个线程来循环调用NameNode的HAServiceProtocol RPC接口的方法来检测NameNode的状态,并将状态的变化通过回调的方式来通知 ZKFailoverController。
HealthMonitor主要检测NameNode的两类状态,分别是HealthMonitor.State和HAServiceStatus。
HealthMonitor.State:
HealthMonitor.State在状态检测之中起主要的作用,在HealthMonitor.State发生变化的时候,HealthMonitor会回调ZKFailoverController的相应方法来进行处理。
HealthMonitor.State是通过HAServiceProtocol RPC接口的monitorHealth方法来获取的,反映了NameNode节点的健康状况,主要是磁盘存储资源是否充足。
HealthMonitor.State 包括以下几种状态:
INITIALIZING:
HealthMonitor 在初始化过程中,还没有开始进行健康状况检测;
SERVICE_HEALTHY:
NameNode 状态正常;
SERVICE_NOT_RESPONDING:
调用NameNode的monitorHealth方法调用无响应或响应超时;
SERVICE_UNHEALTHY:
NameNode 还在运行,但是monitorHealth方法返回状态不正常,磁盘存储资源不足;
HEALTH_MONITOR_FAILED:
HealthMonitor自己在运行过程中发生了异常,不能继续检测NameNode的健康状况,会导致ZKFailoverController进程退出;
HAServiceStatus:
HAServiceStatus在状态检测之中只是起辅助的作用,在HAServiceStatus发生变化时,HealthMonitor也会回调ZKFailoverController的相应方法来进行处理。
HAServiceStatus则是通过 HAServiceProtocol RPC接口的getServiceStatus方法来获取的,主要反映的是NameNode的 HA状态。
HAServiceStatus包括以下几种状态:
INITIALIZING:
NameNode 在初始化过程中;
ACTIVE:
当前 NameNode 为主 NameNode;
STANDBY:
当前 NameNode 为备 NameNode;
STOPPING:
当前 NameNode 已停止;
3>.ActiveStandbyElector实现分析
Namenode(包括 YARN ResourceManager)的主备选举是通过ActiveStandbyElector来完成的,ActiveStandbyElector主要是利用了Zookeeper的写一致性和临时节点机制。
ActiveStandbyElector具体的主备选举功能如下: (1)创建锁节点 如果HealthMonitor检测到对应的NameNode的状态正常,那么表示这个NameNode有资格参加Zookeeper的主备选举。 如果目前还没有进行过主备选举的话,那么相应的ActiveStandbyElector就会发起一次主备选举,尝试在Zookeeper上创建一个路径为/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock的临时节点 (${dfs.nameservices}为Hadoop的配置参数dfs.nameservices的值),Zookeeper的写一致性会保证最终只会有一个ActiveStandbyElector创建成功,那么创建成功的ActiveStandbyElector对应的NameNode就会成为主 NameNode,ActiveStandbyElector会回调ZKFailoverController的方法进一步将对应的NameNode切换为Active状态。而创建失败的ActiveStandbyElector对应的NameNode成为备NameNode,ActiveStandbyElector会回调 ZKFailoverController的方法进一步将对应的NameNode切换为Standby状态。 (2)注册Watcher监听 不管创建/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock节点是否成功,ActiveStandbyElector随后都会向Zookeeper注册一个Watcher来监听这个节点的状态变化事件,ActiveStandbyElector主要关注这个节点的 NodeDeleted事件。 (3)自动触发主备选举 如果Active NameNode对应的HealthMonitor检测到NameNode的状态异常时,ZKFailoverController会主动删除当前在Zookeeper上建立的临时节点/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock,这样处于 Standby状态的NameNode的ActiveStandbyElector注册的监听器就会收到这个节点的NodeDeleted事件。收到这个事件之后,会马上再次进入到创建/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 节点的流程,如果创建成功,这个本来处于Standby状态的NameNode就选举为主NameNode并随后开始切换为Active状态。 如果是Active状态的NameNode所在的机器整个宕掉的话,那么根据Zookeeper的临时节点特性,/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock节点会自动被删除,从而也会自动进行一次主备切换。 (4)防止脑裂 Zookeeper在工程实践的过程中经常会发生的一个现象就是Zookeeper客户端“假死”,所谓的“假死”是指如果Zookeeper客户端机器负载过高或者正在进行JVM Full GC,那么可能会导致Zookeeper客户端到Zookeeper 服务端的心跳不能正常发出,一旦这个时间持续较长,超过了配置的Zookeeper Session Timeout参数的话,Zookeeper服务端就会认为客户端的session已经过期从而将客户端的Session 关闭。“假死”有可能引起分布式系统常说的双主或脑裂(brain-split)现象。假设NameNode1当前为Active状态,NameNode2当前为Standby状态。如果某一时刻NameNode1对应的ZKFailoverController进程发生了“假死”现象,那么Zookeeper 服务端会认为NameNode1挂掉了,根据前面的主备切换逻辑,NameNode2会替代NameNode1进入Active状态。但是此时NameNode1可能仍然处于Active状态正常运行,即使随后NameNode1对应的ZKFailoverController因为负载下降或者 Full GC结束而恢复了正常,感知到自己和Zookeeper的Session已经关闭,但是由于网络的延迟以及CPU线程调度的不确定性,仍然有可能会在接下来的一段时间窗口内NameNode1认为自己还是处于Active状态。这样NameNode1和 NameNode2都处于Active状态,都可以对外提供服务。这种情况对于NameNode这类对数据一致性要求非常高的系统来说是灾难性的,数据会发生错乱且无法恢复。Zookeeper社区对这种问题的解决方法叫做 fencing,中文翻译为隔离,也就是想办法把旧的Active NameNode隔离起来,使它不能正常对外提供服务。 ActiveStandbyElector为了实现fencing,会在成功创建Zookeeper节点hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 从而成为 Active NameNode之后,创建另外一个路径为/hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb的持久节点,这个节点里面保存了这个Active NameNode的地址信息。Active NameNode的ActiveStandbyElector在正常的状态下关闭Zookeeper Session的时候(注意由于/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock是临时节点,也会随之删除),会一起删除节点/hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb。但是如果ActiveStandbyElector在异常的状态下Zookeeper Session关闭(比如前述的Zookeeper假死),那么由于/hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb 是持久节点,会一直保留下来。后面当另一个NameNode选主成功之后,会注意到上一个Active NameNode 遗留下来的这个节点,从而会回调ZKFailoverController的方法对旧的Active NameNode进行fencing。
4>.ZKFailoverController实现分析
ZKFailoverController在创建HealthMonitor和ActiveStandbyElector的同时,会向HealthMonitor和ActiveStandbyElector注册相应的回调函数,ZKFailoverController的处理逻辑主要靠HealthMonitor和ActiveStandbyElector 的回调函数来驱动。 对HealthMonitor状态变化的处理 HealthMonitor会检测NameNode的两类状态: (1)HealthMonitor.State在状态检测之中起主要的作用: ZKFailoverController注册到HealthMonitor上的处理HealthMonitor.State状态变化的回调函数主要关注 SERVICE_HEALTHY、SERVICE_NOT_RESPONDING和SERVICE_UNHEALTHY这3种状态。 如果检测到状态为SERVICE_HEALTHY,表示当前的NameNode有资格参加Zookeepe 的主备选举,如果目前还没有进行过主备选举的话,ZKFailoverController会调用ActiveStandbyElector的joinElection方法发起一次主备选举。 如果检测到状态为SERVICE_NOT_RESPONDING或者是SERVICE_UNHEALTHY,就表示当前的NameNode出现问题了,ZKFailoverController会调用ActiveStandbyElector的quitElection方法删除当前已经在Zookeeper 上建立的临时节点退出主备选举,这样其它的NameNode就有机会成为主NameNode。 (2)HAServiceStatus在状态检测之中仅起辅助的作用: 在HAServiceStatus发生变化时,ZKFailoverController注册到HealthMonitor上的处理HAServiceStatus状态变化的回调函数会判断NameNode返回的HAServiceStatus和ZKFailoverController 所期望的是否一致,如果不一致的话,ZKFailoverController也会调用ActiveStandbyElector的quitElection方法删除当前已经在Zookeeper上建立的临时节点退出主备选举。 对ActiveStandbyElector主备选举状态变化的处理 在ActiveStandbyElector的主备选举状态发生变化时,会回调ZKFailoverController注册的回调函数来进行相应的处理: 如果ActiveStandbyElector选主成功,那么ActiveStandbyElector对应的NameNode成为主NameNode,ActiveStandbyElector会回调ZKFailoverController的becomeActive方法,这个方法通过调用对应的NameNode的 HAServiceProtocol RPC接口的transitionToActive方法,将NameNode转换为Active状态。 如果ActiveStandbyElector选主失败,那么ActiveStandbyElector对应的NameNode成为备NameNode,ActiveStandbyElector会回调ZKFailoverController的becomeStandby方法,这个方法通过调用对应的NameNode的 HAServiceProtocol RPC接口的transitionToStandby方法,将NameNode转换为Standby状态。 如果ActiveStandbyElector选主成功之后,发现了上一个Active NameNode遗留下来的/hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb节点,那么ActiveStandbyElector会首先回调ZKFailoverController注册的 fenceOldActive方法,尝试对旧的Active NameNode进行fencing,在进行fencing的时候,会执行以下的操作: (1)首先尝试调用这个旧Active NameNode的HAServiceProtocol RPC接口的transitionToStandby方法,看能不能把它转换为Standby状态。 (2)如果transitionToStandby方法调用失败,那么就执行Hadoop配置文件之中预定义的隔离措施,Hadoop目前主要提供两种隔离措施,通常会选择sshfence: sshfence: 通过SSH登录到目标机器上,执行命令fuser将对应的进程杀死; shellfence: 执行一个用户自定义的shell脚本来将对应的进程隔离; (3)只有在成功地执行完成隔离(fencing)之后,选主成功的ActiveStandbyElector才会回调ZKFailoverController的becomeActive方法将对应的NameNode转换为Active状态,开始对外提供服务。
5>.Apache Hadoop高可用部署实战案例
博主推荐阅读: https://www.cnblogs.com/yinzhengjie2020/p/12508145.html