YARN基本配置-物理资源分配设置
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
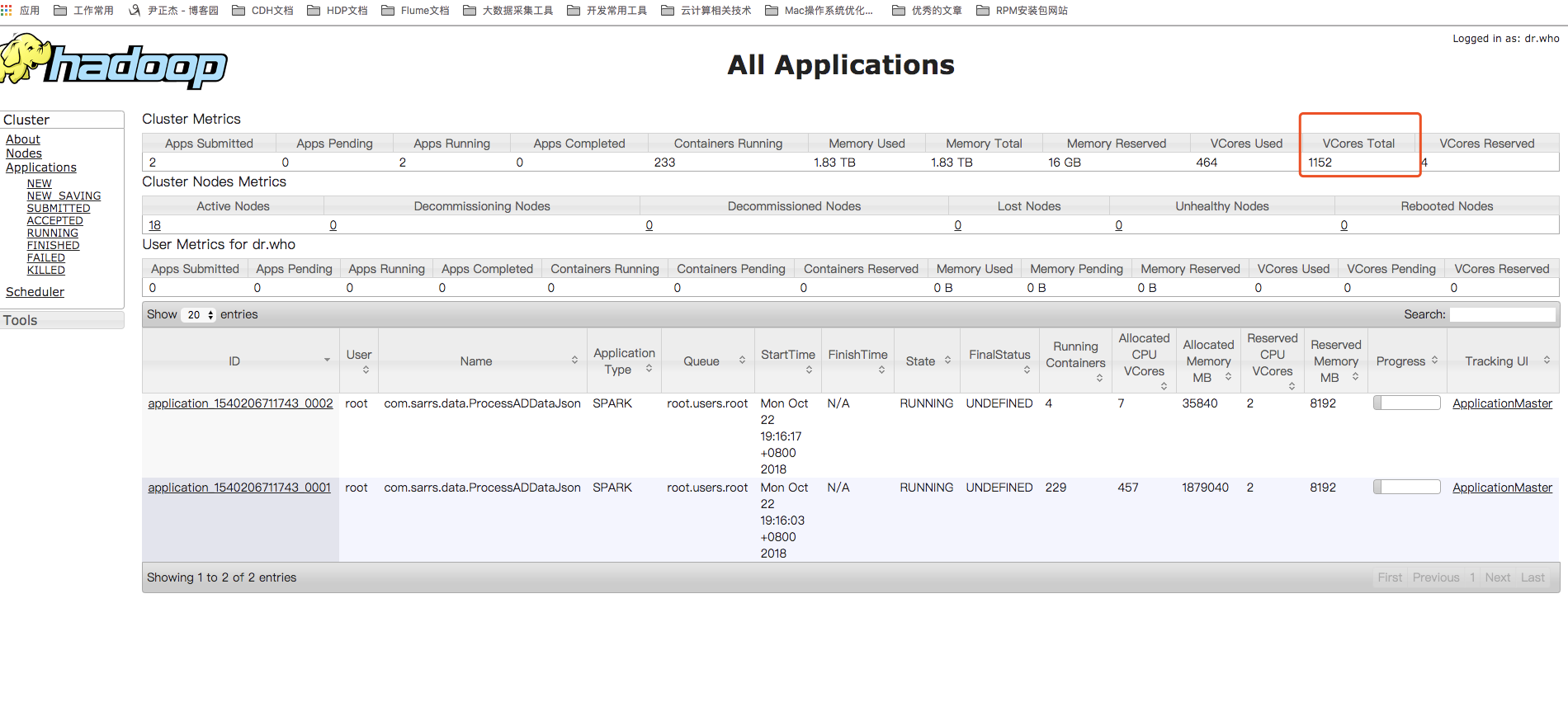
折腾了一个星期,终于让开发将数据跑起来了,可通过yarn的webUI界面,发现这里的核心数和内存都对应不上,相差的太远了,我的服务器都是32core,128G内存,12*8T的硬盘。理论上的集群可以用的内存应该接近2T。可是我发信内存只有四分之一。

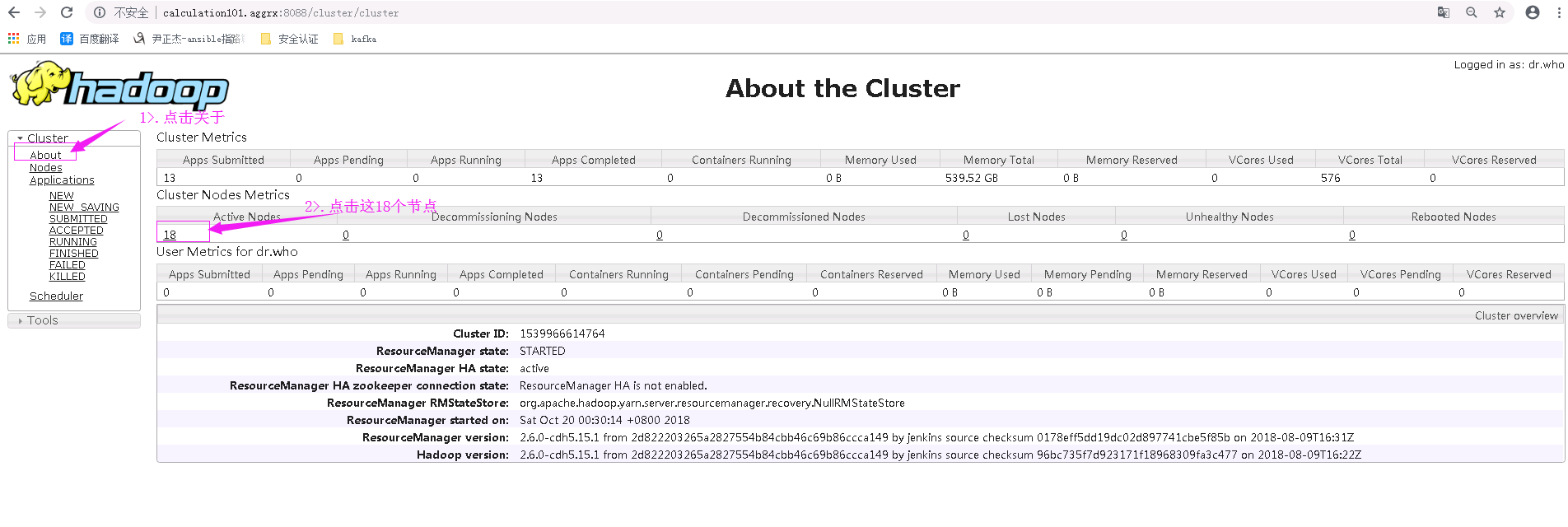
接下来,我们可以通过这个界面获取一些信息,如下图,点击“about”,可以看到有18个节点(20台机器,2gNN节点,18个DN节点)
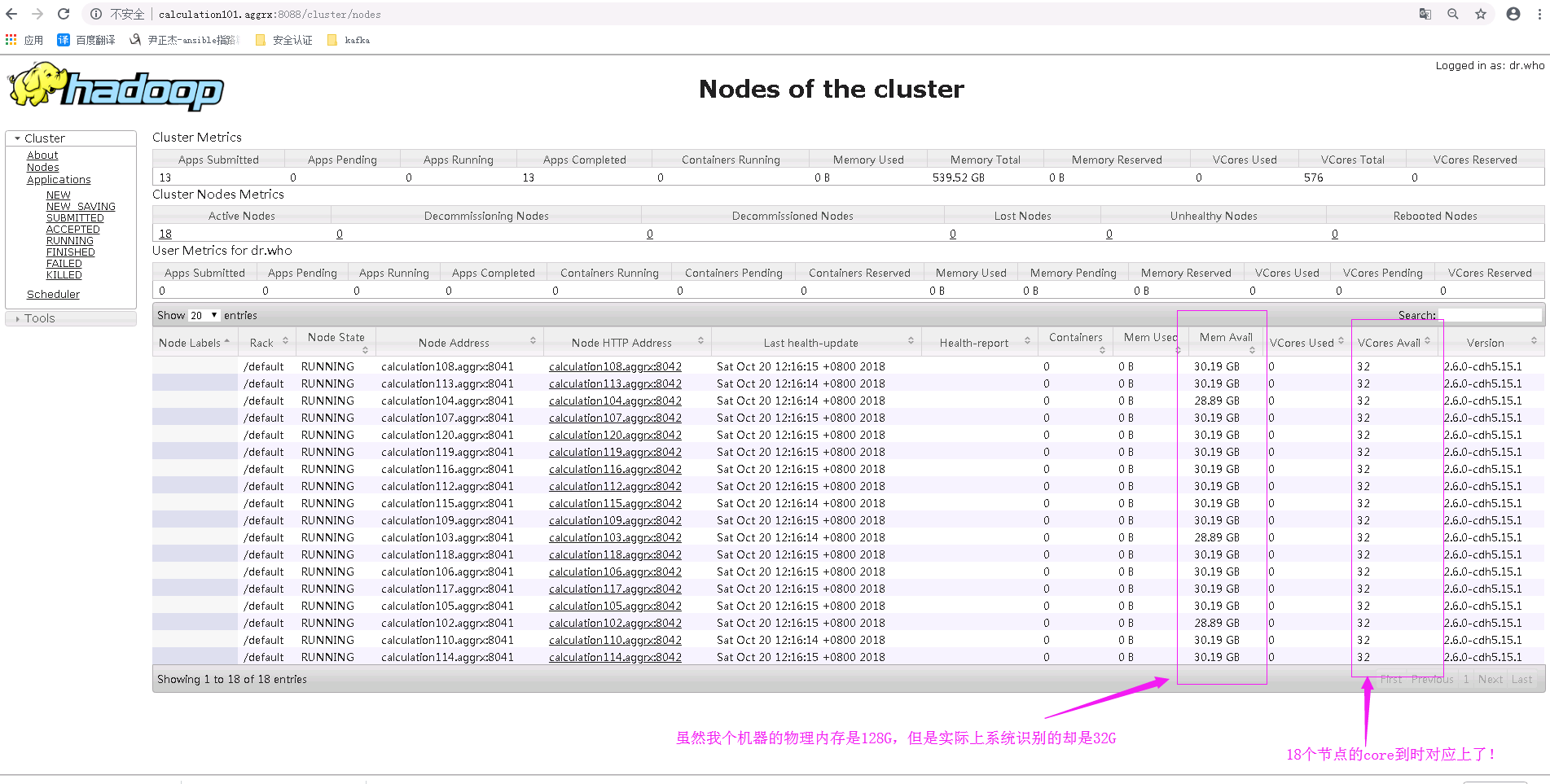
点击上面的按钮,我们可以查看到18个几点的详细信息,因此我们可以一目了然的看出来我的集群配置如下:
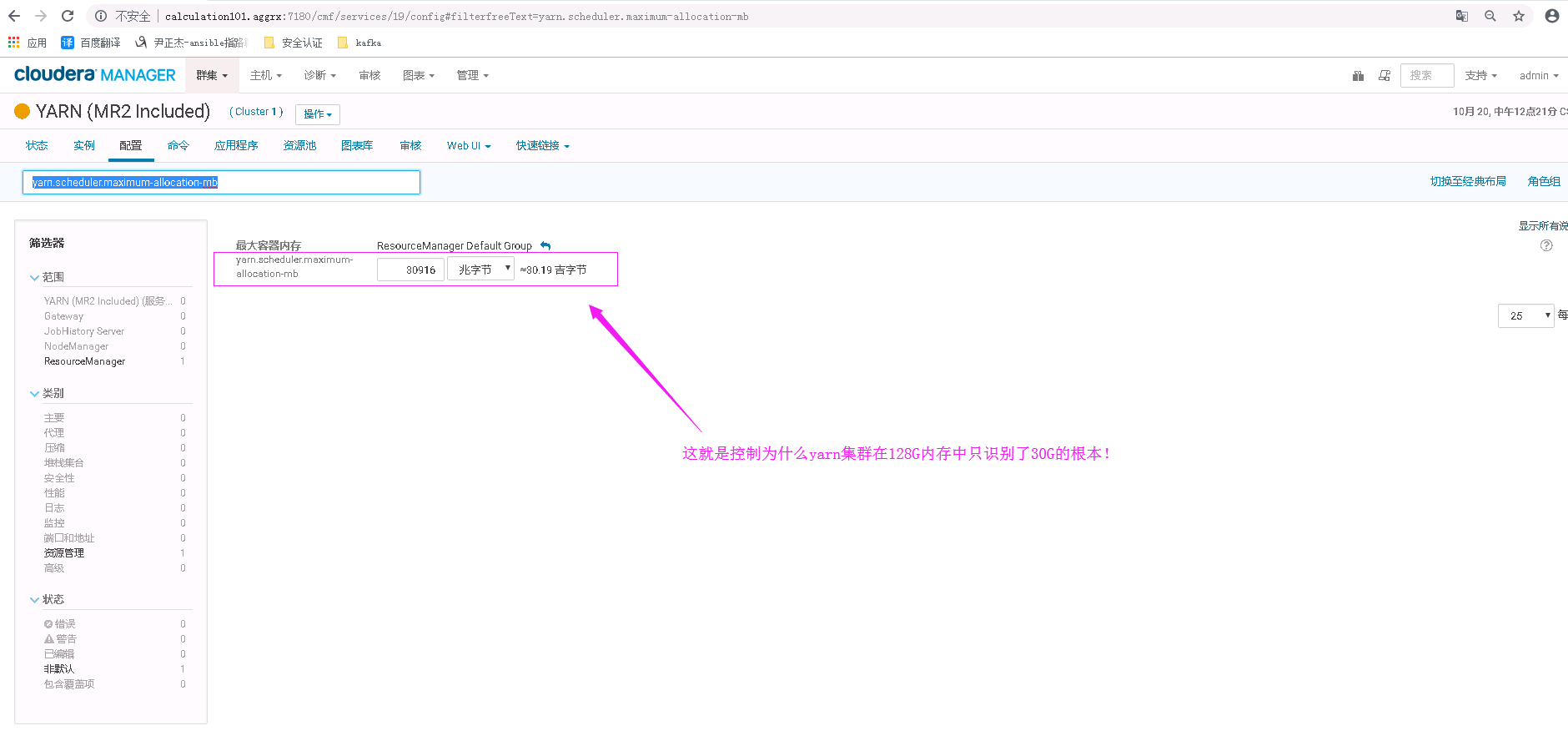
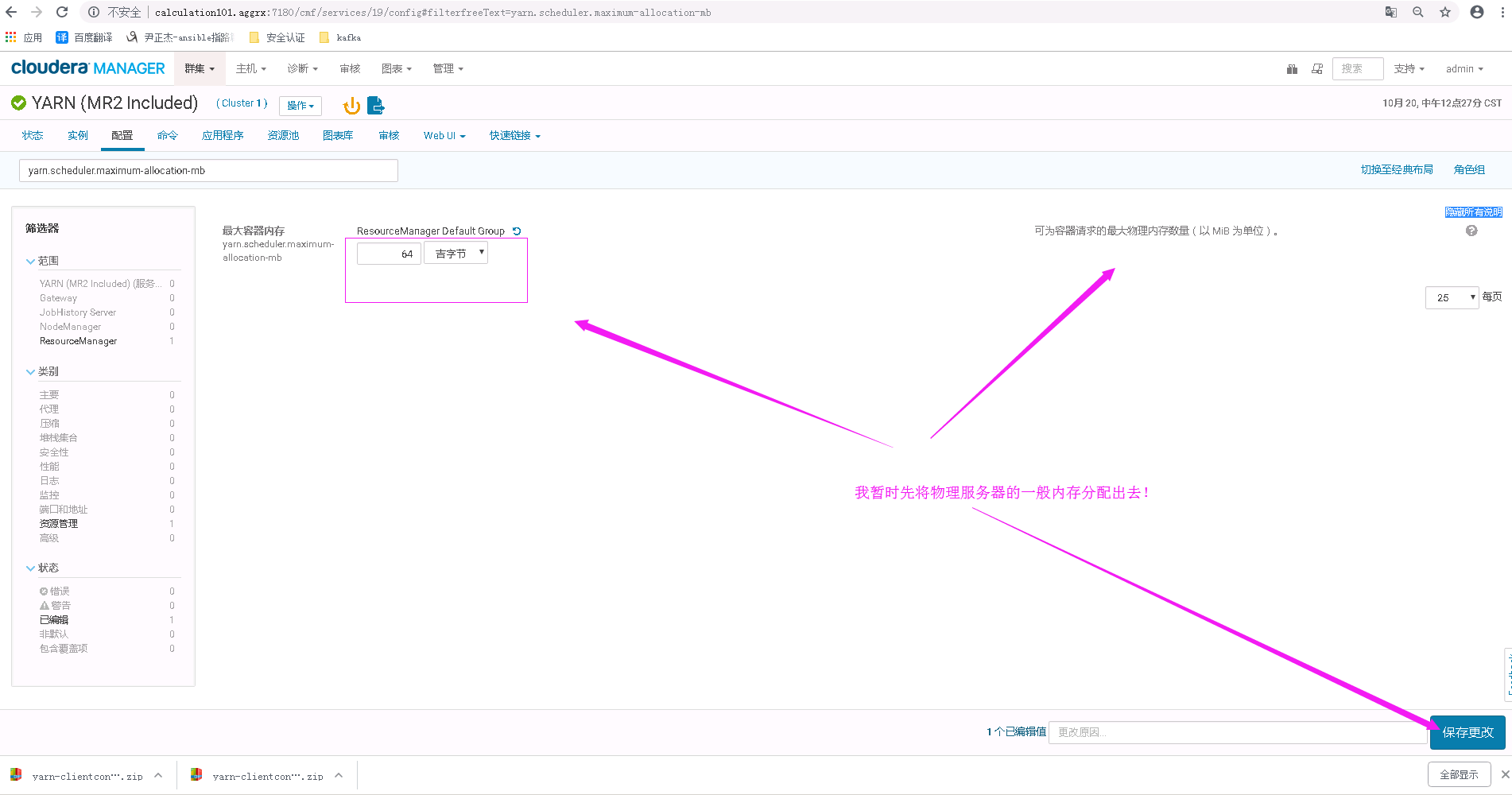
接下来我们去CM上查看一个配置参数:yarn.scheduler.maximum-allocation-mb,这个参数是:可为容器请求的最大物理内存数量
于是,我修改了上面的值,将其改为64G,如下图,点击保存并重启yarn服务
按照上述配置修改后,发现依旧不对,如下图:

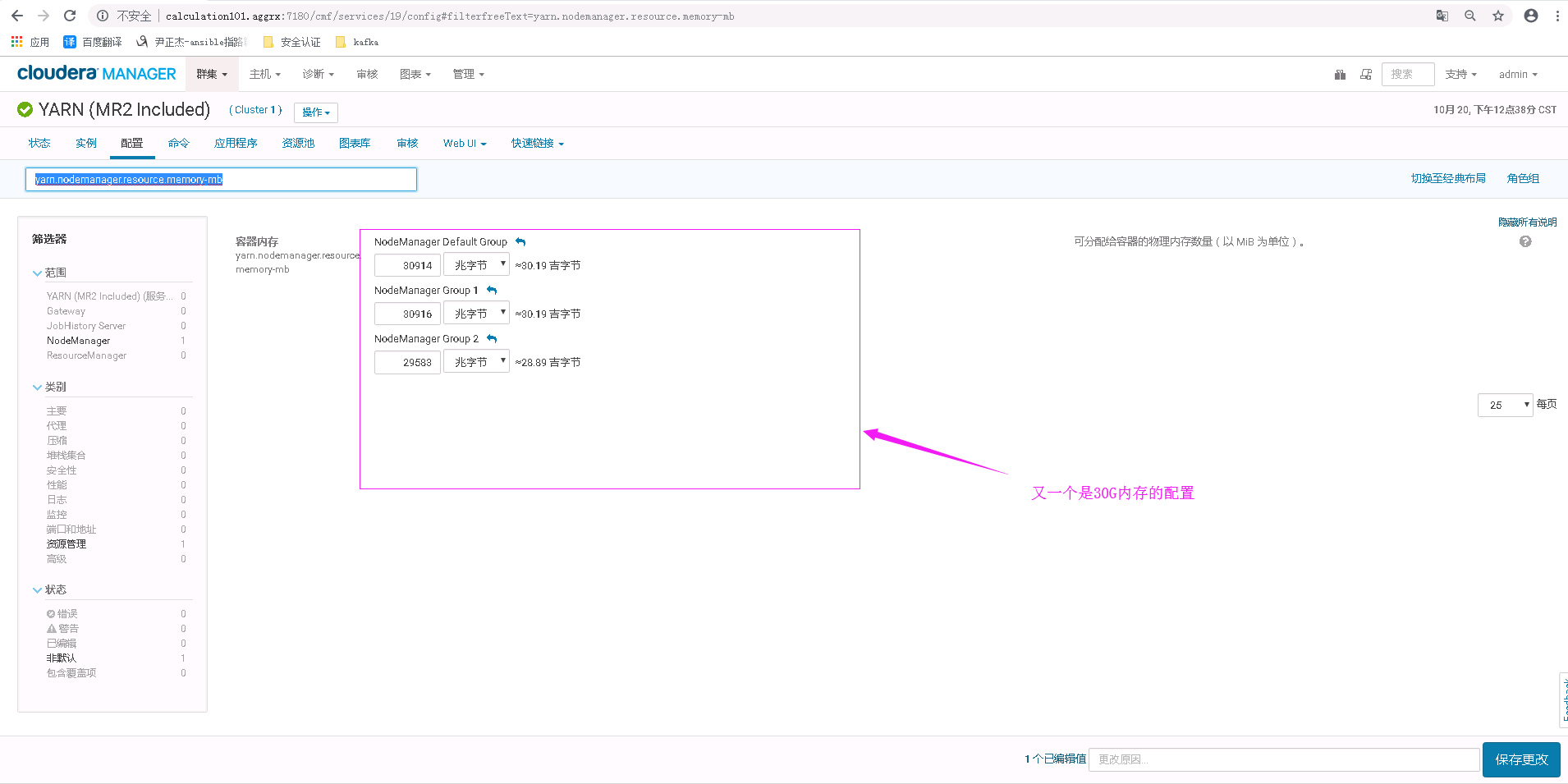
紧接着,我有修改了yarn.nodemanager.resource.memory-mb这个值,它是值可分配的物理内存数量,这个值在我的集群中国貌似默认就是30G和上图中的30G很像呢,如下图:
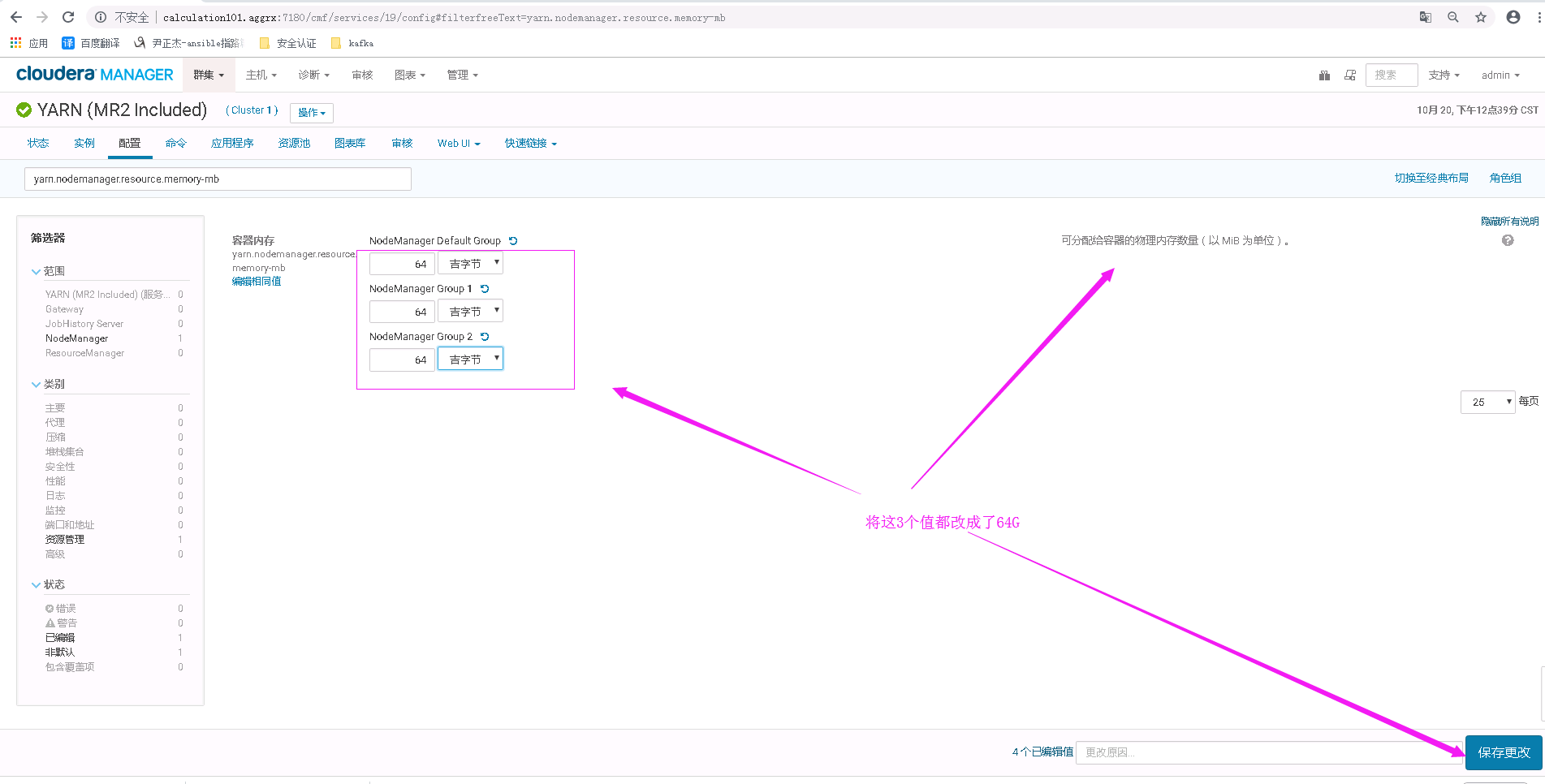
我将上面的值修改成64G,保存并重启了yarn服务,如下图:
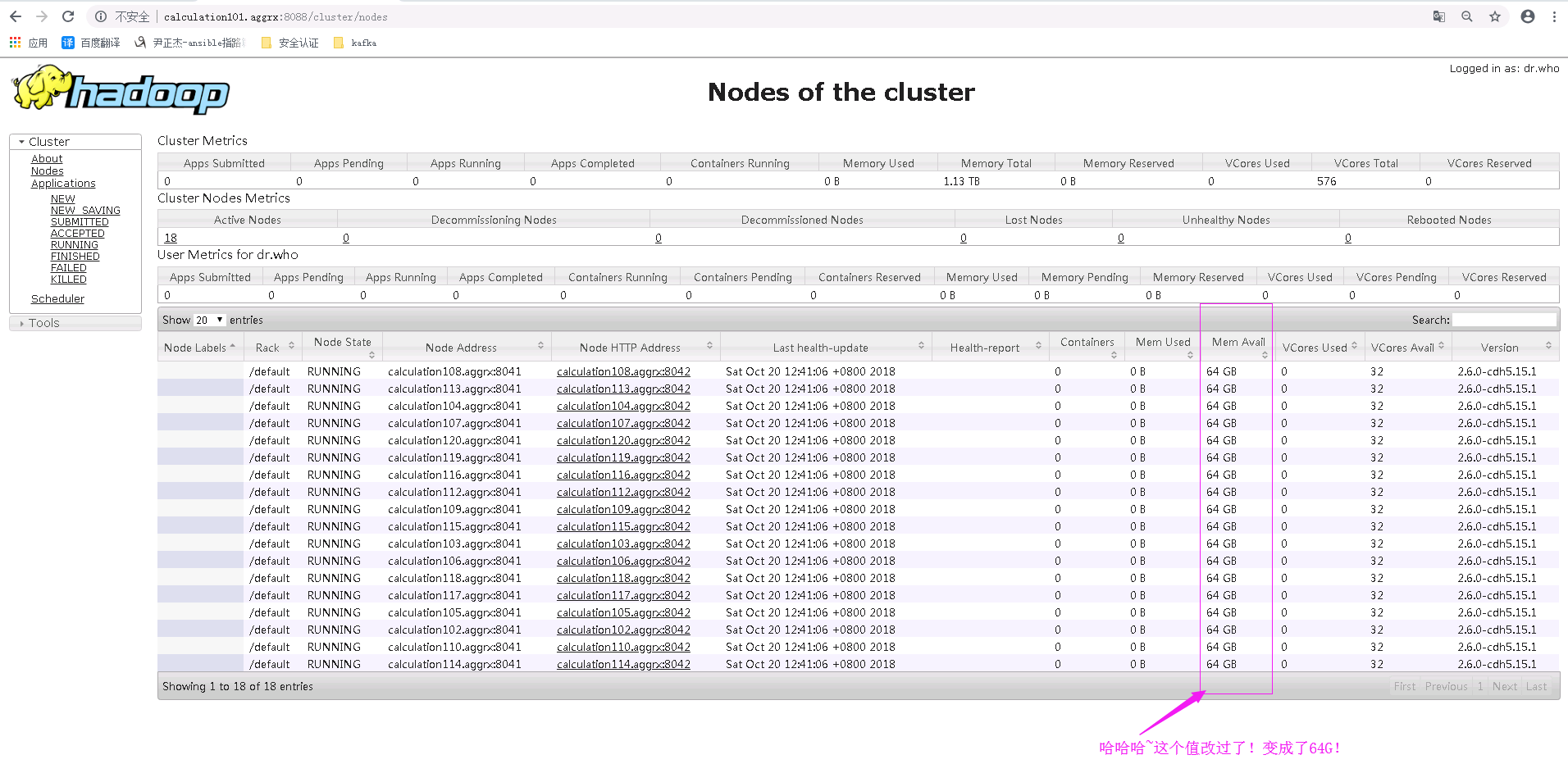
修改后,我们在查看webUI这个值是否有变化,果真,这次就很好使了。
关于memory的调餐我知道在哪调试了,由于我的节点都是128G内存(实际就125G内存),因此我将上面的值改为104G,给操作系统预留了24G,到周一了,开发说Core数应该虚拟出来,这个时候没辙啊,只能接着修改core的数来,而我没台机器仅有32个core,如果想要在webUI将这个参数调大,可以通过调大“yarn.nodemanager.resource.cpu-vcores”参数的值。
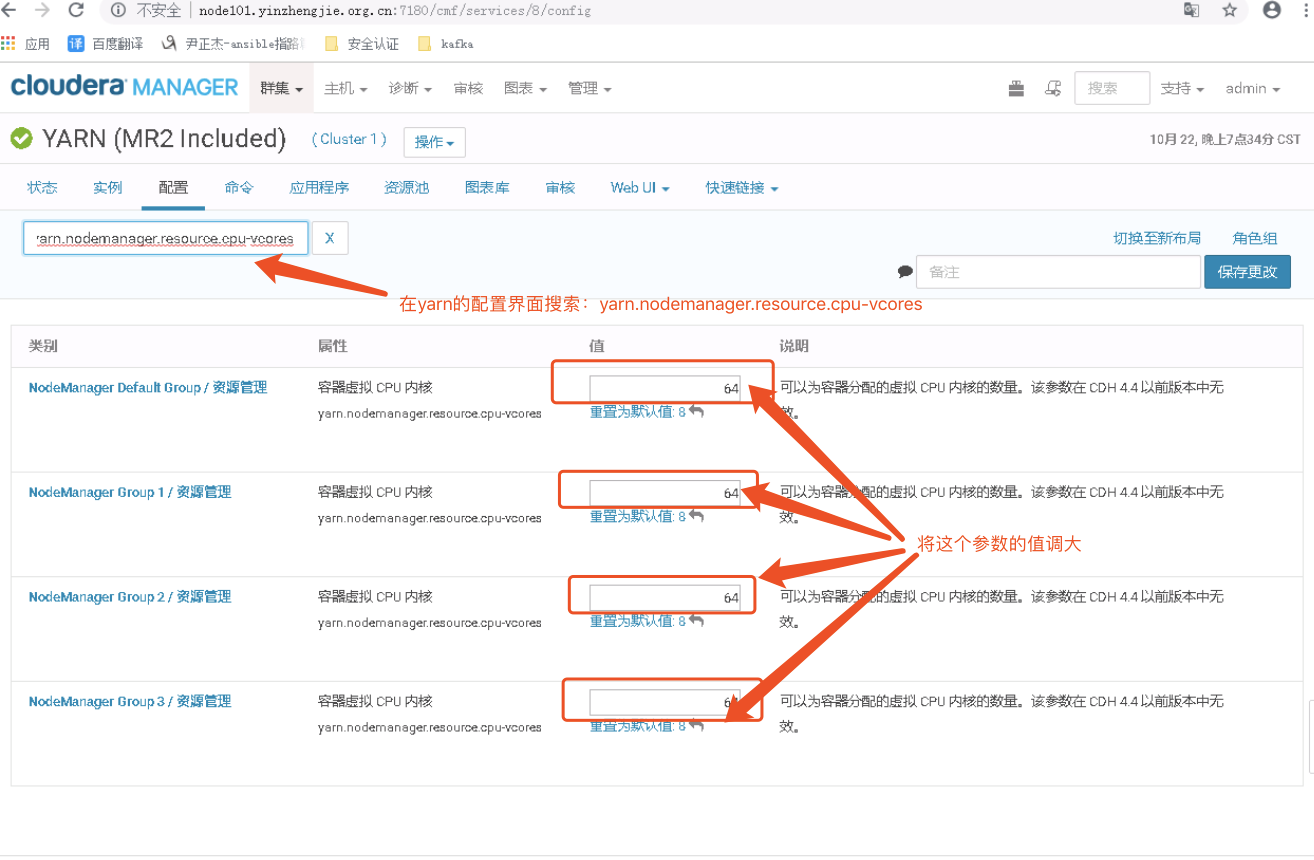
修改过后,我们可以看到webUI的core 总的总数也在发生着吧变化,如下图: