Scala进阶之路-I/O流操作之文件处理
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
说起Scala语言操作文件对象其实是很简单的,大部分代码和Java相同。
一.使用Scala拷贝文件实现
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Scala%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.file 7 8 import java.io._ 9 10 object FileDemo { 11 /** 12 * 定义读取文件的方法 13 */ 14 def readFile(filePath:String): Unit ={ 15 val f = new File(filePath) 16 val fis = new FileInputStream(f) 17 val buf = new BufferedReader(new InputStreamReader(fis)) 18 var line = ""; 19 /** 20 * 我这里定义一个标志位,判断文件是否读取完毕,不建议使用break,不仅仅是因为它需要导报,而是因为它是以抛异常的 21 * 方式结束了整个程序!这一点我真的想吐槽Scala啦!比起Python,Java,Golang,Scala是没有continue和break关键字的! 22 */ 23 var flag:Boolean= true 24 while (flag){ 25 line = buf.readLine() 26 //注意,Scala在读取文件时,如果读到最后会返回一个null值,因此,此时我们将标志位改为false,以便下一次结束while循环 27 if (line == null){ 28 flag = false 29 }else{ 30 println(line) 31 } 32 } 33 buf.close() 34 fis.close() 35 } 36 37 /** 38 * 拷贝文本文件 39 */ 40 def copyFile(Input:String)(OutPut:String): Unit ={ 41 val input = new File(Input) 42 val output = new File(OutPut) 43 val fis = new FileInputStream(input) 44 val fos = new FileOutputStream(output) 45 val buf = new BufferedReader(new InputStreamReader(fis)) 46 val cache = new BufferedWriter(new OutputStreamWriter(fos)) 47 var line = ""; 48 var flag:Boolean= true 49 while (flag){ 50 line = buf.readLine() 51 if (line == null){ 52 flag = false 53 }else{ 54 cache.write(line) 55 cache.write(" ") 56 cache.flush() 57 } 58 } 59 cache.close() 60 fos.close() 61 fis.close() 62 println("拷贝完毕") 63 } 64 65 66 /** 67 * 拷贝任意类型文件,包括二进制文件 68 */ 69 def copyFile2(Input:String)(OutPut:String): Unit ={ 70 val fis = new FileInputStream(Input) 71 val fos = new FileOutputStream(OutPut) 72 //定义缓冲区 73 val buf = new Array[Byte](1024) 74 var len = 0 75 76 /** 77 * 注意:len = fis.read(buf)是一个赋值操作,这个赋值操作是没有任何的返回值的哟!因此我们需要返回len的值。 78 */ 79 while ({len = fis.read(buf);len} != -1){ 80 fos.write(buf,0,len) 81 } 82 fos.close() 83 fis.close() 84 println("拷贝完毕") 85 } 86 87 def main(args: Array[String]): Unit = { 88 var input = "D:\BigData\JavaSE\yinzhengjieData\1.java" 89 var output = "D:\BigData\JavaSE\yinzhengjieData\2.java" 90 // readFile(input) 91 copyFile2(input)(output) 92 } 93 } 94 95 96 97 98 /* 99 以上代码输出结果如下 : 100 拷贝完毕 101 */
二.读取用户的输出
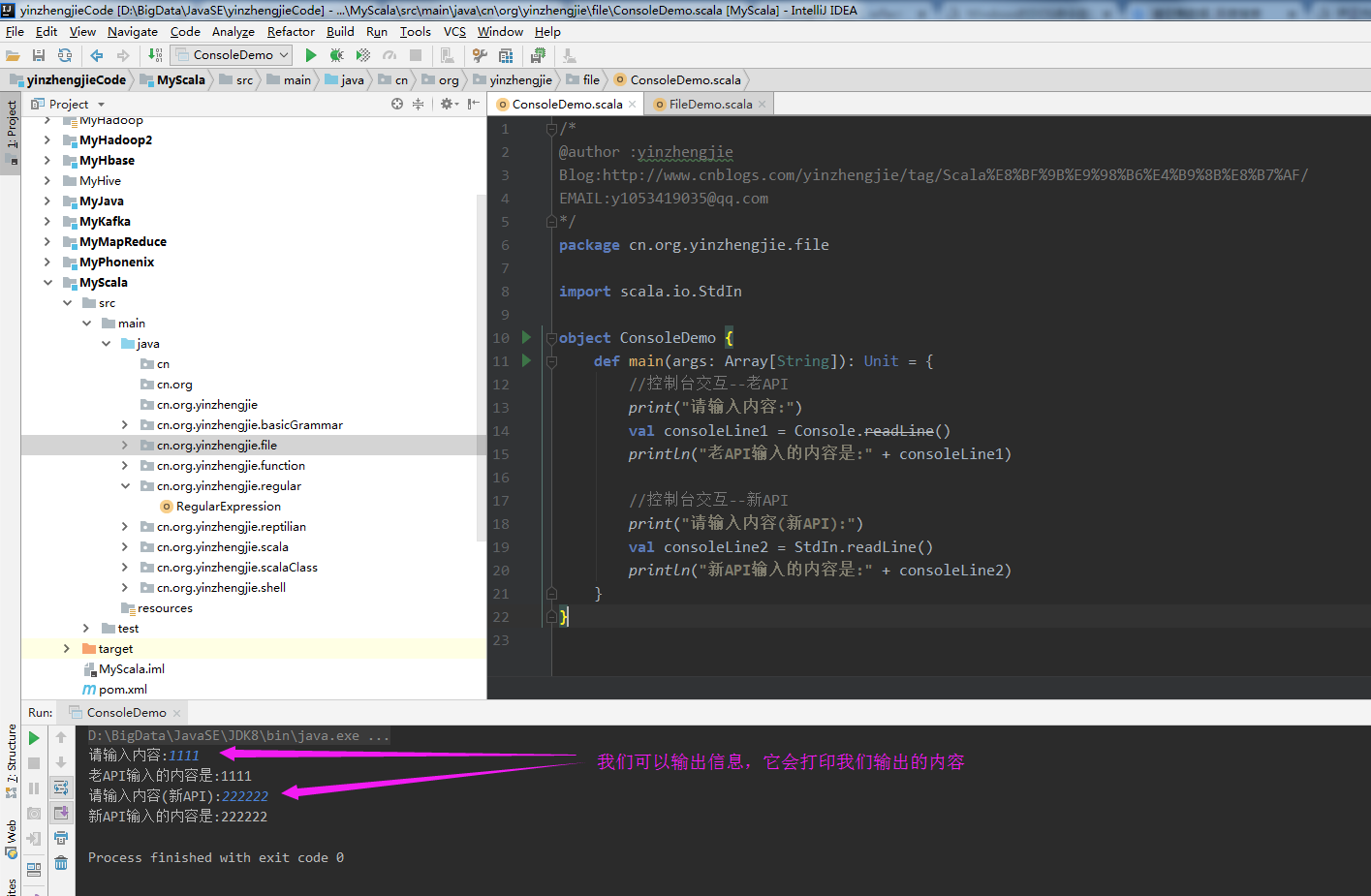
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Scala%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.file 7 8 import scala.io.StdIn 9 10 object ConsoleDemo { 11 def main(args: Array[String]): Unit = { 12 //控制台交互--老API 13 print("请输入内容:") 14 val consoleLine1 = Console.readLine() 15 println("老API输入的内容是:" + consoleLine1) 16 17 //控制台交互--新API 18 print("请输入内容(新API):") 19 val consoleLine2 = StdIn.readLine() 20 println("新API输入的内容是:" + consoleLine2) 21 } 22 }
以上代码执行结果如下:
三.Scala文件处理常用方法
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Scala%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.file 7 8 object SourceDemo { 9 def main(args: Array[String]): Unit = { 10 var input = "D:\BigData\JavaSE\yinzhengjieData\1.java" 11 val f = scala.io.Source.fromFile(input) 12 println(f) 13 14 /** 15 * 迭代打印文件中的每行内容 16 */ 17 // val it = f.getLines() 18 // for(x <- it){ 19 // println(x) 20 // } 21 22 /** 23 * 读取整个文件串 24 */ 25 println(f.mkString) 26 27 /** 28 * 迭代每个字符 29 */ 30 // for(c <- f){ 31 // print(c) 32 // } 33 34 /** 35 * 使用正则 s:空白符 S:非空白符 36 * 所谓的空白符就是指:空格,制表符,换行符等等 37 */ 38 // val arr = f.mkString.split("\s+") 39 // for(a <- arr){ 40 // println(a) 41 // } 42 43 } 44 }
使用Scala爬取网页,在网上找了一些写的都长篇大论,属实懒得看,爬虫的话建议还是用Java或者Python去写,Java爬取网页的笔记可参考:https://www.cnblogs.com/yinzhengjie/p/9366013.html。
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Scala%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.file 7 8 import java.io.FileOutputStream 9 10 object ReptilianDemo { 11 12 def copyFile(Input:String)(OutPut:String): Unit ={ 13 val fos = new FileOutputStream(OutPut) 14 fos.write(Input.getBytes()) 15 println("拷贝完毕") 16 } 17 18 def main(args: Array[String]): Unit = { 19 /** 20 * Scala的fromURL方法我是不推荐使用的,因为爬去的内容不完全,需要设置相应的参数,建议用java代码或者Python去爬取 21 * 可参考:https://www.cnblogs.com/yinzhengjie/p/9366013.html 22 */ 23 val res = scala.io.Source.fromURL("https://www.cnblogs.com/yinzhengjie") 24 val html = res.mkString 25 println(html) 26 var output = "D:\BigData\JavaSE\yinzhengjieData\尹正杰.html" 27 copyFile(html)(output) 28 29 } 30 }
访问成功的话,在控制端会打印如下信息: