交互式计算引擎ROLAP篇
摘自:《大数据技术体系详解:原理、架构与实践》
一.Impala
Impala最初由Cloudera公司开发的,其最初设计动机是充分结合传统数据库与大数据系统Hadoop的优势,构造一个全新的,支持SQL与多租户,并具备良好的灵活性和扩展性的高性能查询引擎。传统数据库与大数据系统Hadoop各有优缺点:
(1)传统关系型数据库对SQL这种最主流的数据分析语言有完好的支持,且支持多租户,能够很好对应并发场景,但灵活性和扩展性较差。
(2)大数据系统Hadoop具备很好的灵活性(支持各种数据存储格式,各种存储系统等)和扩展性(数据规模和计算规模均可以线性扩展),但对SQL及并发的支持较弱。
Cloudera结合传统数据库与大数据系统Hadoop各自优点,利用C++语言构造了一个全新的高性能查询引擎Impala。在Cloudera的测试中,Impala的查询效率比Hadoop生态系统中的SQL引擎Hive有数量级的提升。从技术角度上来看,Imapla之所以有好的性能,主要有以下几个方面:
(1)Impala完全抛弃了MapReduce这个不太适合做SQL查询的范式,而是像Dremel一样借鉴了MPP并行数据库的思想,采用了全服务进程的设计架构,所有计算均在预先启动的一组服务中进行,可支持更好的并发,同时省略掉不必要的shuffe,sort等开销。
(2)Impala采用全内存实现不需要把中间结果写入磁盘,省略了大量的I/O开销。
(3)充分利用本地读(而非远程网络读),尽可能将数据和计算资源分配在同一台机器,减少网络开销。
(4)用C++实现,做了很多针对底层硬件的优化,例如使用SSE指令。
Impala官网网站:http://impala.apache.org/。
1>.基本架构
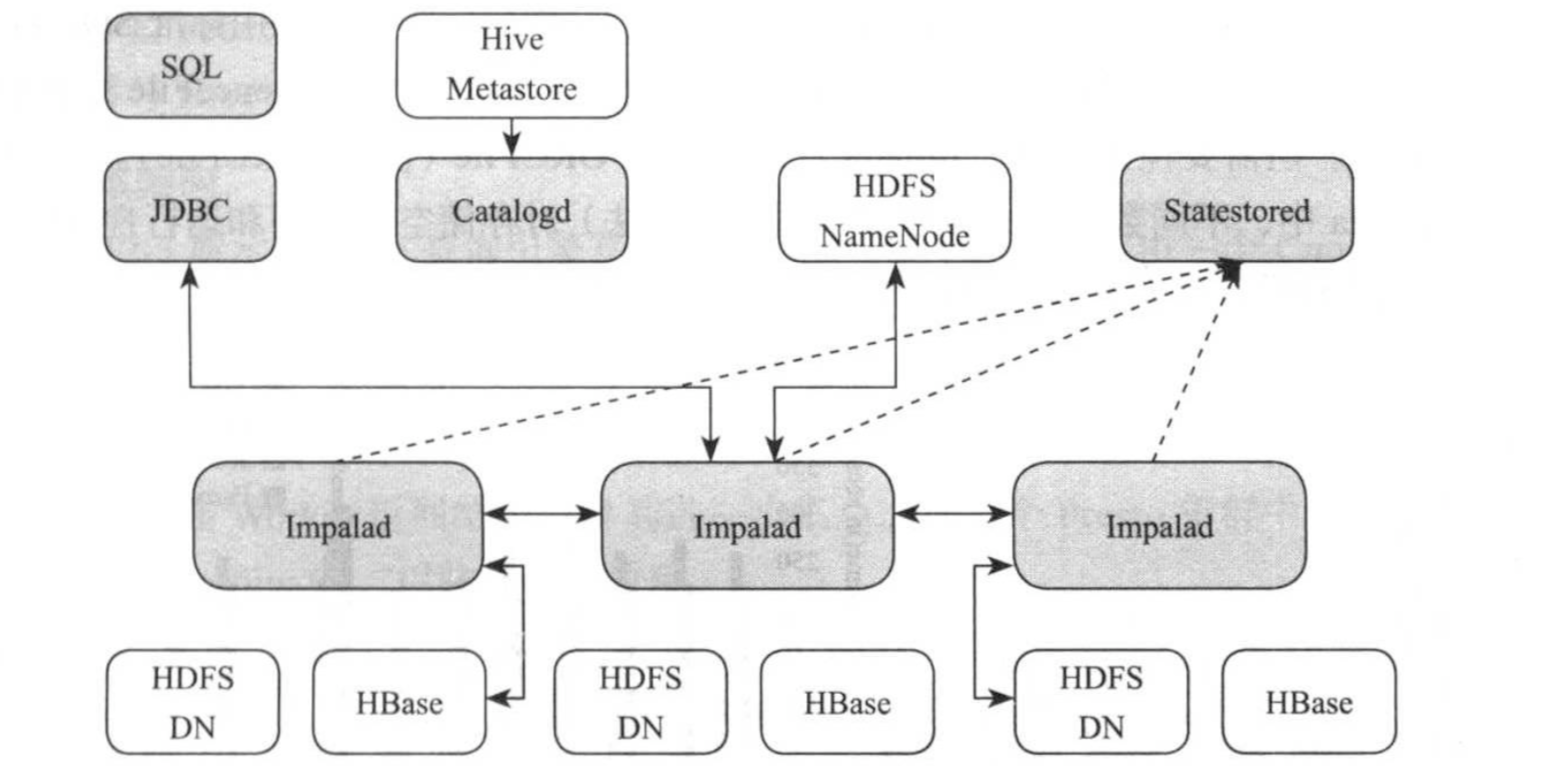
Impala采用了对等式架构,所有角色中间是对等的,没有主从之分,如下图所示,Impala主要由三类服务组成,分别为Catalogd,Statestored和Impalad,接下来依次介绍这几个组件:
(1)Catalogd
元信息管理服务,它从hive metastore中同步表信息,并将任何元数据的改变通过catalogd广播给各个Impala服务。需要注意的是,在一个大数据数据仓库中,元数据一般很大,不同数据表的访问频度不同,为此,Catalogd仅仅载入每张表的概略信息,更为详细的信息由后台进程从第三方存储中延迟载入。
(2)Statestored
状态管理服务器。元数据订阅-发布服务,它是单一实例(存在单点故障问题),将集群元数据传播到所有Impala进程。MPP数据库设计的一大挑战是实现节点见协调和元数据同步,Impala对称的节点架构要求所有的节点必须都能够接受并执行查询,因此所有节点必须有系统目录结构和最新版本和集群成员关系的当前视图,而Statestored正式负责以上这些功能,即将所有元数据及其修改同步到各个Impalad。
(3)Impalad
同时承担协调者和执行者双重角色。首先,对于某一查询,作为协调者,接受客户段查询请求并对其进行分词,语法分析,生成逻辑查询计划以及物理查询计划,之后的各个执行片段(segemet)调度到Impalad上执行;其次,接受从其他Impalad发过来的单个执行片段,利用本地资源(CPU,内存等)处理这些片段,并进一步将查询结果返回给协调者。Impala一般部署在集群中运行Datanode进程的所有机器上,进而利用数据本地化的特点而不必通过网络传输即可在文件系统中读取数据库。
需要注意的是,在内存资源不足时,Impala也支持将中间结果数据写入磁盘,但需要显式启用该功能。
Impala前端负责将SQL编译为可之行的查询计划,它由SQL解析器,基于成本(costbased)的优化器组成。它的查询编译阶段遵循经典的实现方式:分为查询解析,语义分析,查询计划/优化等几个模块。最大挑战啊来自查询计器,它将执行计划分为两个阶段:单点计划;计划并行和分隔。
第一阶段,将解析树转换为单点计划树,这包括如下内容:HDFS/HBase扫描,hashjoin,cronssjoin,union,hash聚集,sort,top-n和分析评估等。它基于分析评估结果,进行谓词下推,相关列投影,分区剪枝,设置限制(limit)/偏移并完成一些基于成本的优化比如排序,合并分析窗口函数和join重排序等。
第二阶段,将单个节点的计划转换分分布式计划,基于目标在与最小化数据移动和最大化本地数据扫描,它通过在计划节点间增加必要的交换实现分布式,通过增加额外的非交换节点最小化网络间的数据移动,在此阶段,生物的物理join策略。Impala支持两种分布式join方式,表广播(broadcast)和哈希重分布两张表数据。
在Impala中,分布式计划中的聚集函数会被分拆为两个阶段执行。第一节点:针对本地数据进行分组聚合降低数据量,并进行数据重分布;第二阶段:进一步汇总之前的局部聚集结果计算处最终结果。
2>.访问方式
Impala定位是为用户提供一套能与商业智能场景结合的查询引擎,它与其他查询引擎类似,支持多种商业标准:通过JDBC/ODBC访问,通过kerberos或LDAP进行认真,遵循标准SQL的角色授权等。为了更好与Hive Metastore结合,它支持大部分HQL(Hive Query Language)语法,用户通过CREATE TABLE创建表,并提供数据逻辑模式,指定物理布局(包括数据存储格式以及数据目录组织方式),创建后的表可 采用标准SQL查询。
Impala支持几乎所有主流的数据存储格式,包括文本格式,SequenceFile,RCFile以及Parquet等。但需要注意的是,Impala目前不支持ORCFile(优化的RCFile)。
下图展示了在Impala中,不同数据格式(结合不同压缩算法)对存储空间占用和运行性能的影响。很明显,列式存储格式在存储空间占用的性能提升方面有明显优势。

Impala支持几乎所有的SQL-92中的SELECT语法以及SQL-2003中的分析型函数,支持几乎所有的标准数据类型,包括INTEGER,FLOAT,STRING,CHAR,VARCHAR,TEIMESTAMP和DECIMAL(最高达38精度)。 此外,Impala也支持用户自定义函数和自定义聚集函数。
由于Impala是传统关系型数据库与大数据系统Hadoop结合的产物,它在一些方面不同于传统关系型数据库:
(1)由于HDFS存储系统自身的限制,Impala目前不支持面向单行的UPDATA和DELETE操作,而只支持按批插入和删除:
按批插入可使用INSERT INTO ... SELECT ...语法。
按批删除可使用ALTER TABLE DROP PARTITION语法。
(2)数据加载速度快,运行时类型校验:
往Impala表中加载数据的速度非常快,只需要在存储层拷贝或移动文件即可,而不会进行任何类型检查。
Impala采用运行时检查的方式,即SQL执行时动态检查每行的数据类系否跟表模式匹配。
(3)不支持事务
Impala是面向OLAP(OnLine Analytical Processing)应用场景的,以只读型的数据分析为主,对OLTP(OnLine Transaction Processing)场景没有直接支持。
二.Presto
Prosto是Facebook开源的交互式计算引擎,能够处理TB甚至PB数据量。由于Presto能够与Hive进行无缝集成,因而以及成为非常主流的OLAP引擎。
Prosto官网网址:https://prestodb.github.io/。
1>.基本架构
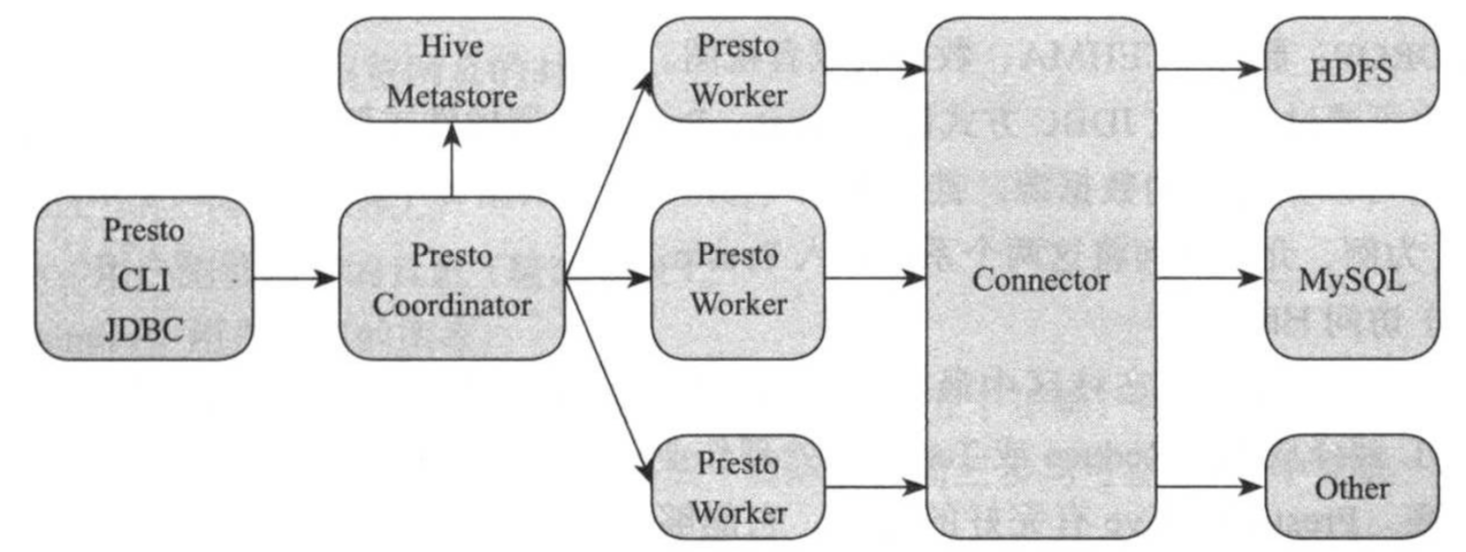
如下图所示,Presto查询引擎是一个Master-Slave的架构,由一个coordinator服务,一个Discovery Server服务,多个Worker服务组成,它们的职责如下:
(1)Coordinator
协调者,接受客户端查询请求(SQL)并对其进行词法分析,语法分析,生成逻辑查询计划以及物理查询计划后,将各个任务调度到Worker上执行,并在Worker返回结果后对其进一步汇总。在Prosto集群中,可以同时存在多个Coordinator,以防止单点故障。
(2)Discovery Server
服务发现组件,各个Worker启动时会像Discovery Server注册,并将状态信息定期汇报给Discovery Server,这样,Coordinator可随时从Discovery Server中获取活跃的Worker劣币阿婆。Discovery Server是一个轻量级的服务,通常内嵌Coordinator节点中。
(3)Worker
任务执行者,接收来自Coordinator任务,利用多线程方式并行执行,并将结果发送给Coordinator。
2>.访问方式
Presto是插拔式架构,通过连接器(Connector)接入外部数据源。为了分区各个数据源的数据,它在数据库之上又引入了一层命名空间:catalog,前面提到的Hive,Cassandra和MySQL等在Presto中均一catalog方式存在。不同的catalog中可以又多个数据库,每个数据库中进一步可以同时存在多张数据表。
Presto支持大部分标准SQL语法,包括SELECT,CREATE,DELETE,ALTER,DROP等。
SELECT其基本语法如下:
[ WITH with_query [,...]]
SELECT [ ALL | DISTINCT] select_expr [,...]
[ FROM from_item [,...]]
[ WHERE conditon]
[ GROUP BY [ALL | DOSTINCT] grouping_element [,...]]
[ ORDER BY expression [ASC | DESC] [,...]]
[LIMIT [count | ALL]]
支持五种JOIN操作,包括内链接,左外链接,右外链接,全外链接以及笛卡尔积,除此之外,它还支持CUBE,ROLLUP等数据仓库操作;
CREATE :可创建SCHEMA(可容纳类似数据表和视图德国数据库对象的容器),TABLE,VIEW。
DELETE :删除数据库表特定的行,有些connector不支持该操作。
ALTER :修改SCHEMA或数据表的元信息,包括重命名SCHEMA或数据表,为数据表增加新列等。
DROP :删除SCHEHMA,数据表或者视图。
用户可通过CLI或JDBC访问Presto。Presto采用了插件式架构,可支持多种数据源,这使得它可以集成异构数据源,甚至连接(join)不用数据源中的数据。接下里以Hive和MySQL为例,介绍如何将这两个系统接入Presto。
(1)Presto访问Hive
Hive是Hadoop生态社区中最早的分布式SQL查询引擎,它并未采用MPP架构,而是将SQL翻译成MapReduce或者Tez等批处理作业运行在Hadoop集群中,因而数据处理效率并不高。Presto与Hive有完好的支持,它能够直接读取Hive只能够已经存在的表,并使用MPP引擎进行高效处理。
Hive主要有三个组件组成:
数据存储:Hive使用分布式文件系统HDFS或S3存储数据,并支持包括文本文件,SequenceFile,RCFile,ORCFile以及Parquet等数据格式。
元数据管理:Hive中记录数据和表之间映射关系的元数据由Hive Metastore管理,它将这些元数据保存到关系型数据库中(比如MySQL)。
查询语言HQL与分布式计算引擎:Hive中定义了一种类似于SQL的查询语言HQL,它能将这种语言翻译成MapReduce或Tez分布式作业,并运行在Hadoop集群中。
Presto只用到了Hive中的前两个组件:数据存储和元数据管理,但并为使用HQL以及查询引擎,而是采用了自己定义但SQL查询语言和分布式查询引擎。
Hive支持多个Hadoop版本,包括Apache Hadoop 1.x,Apache Hadoop 2.x,CDH4.x以及CDH5.x,以CDH5.x为例,你可以在"/etc/catalog"下创建文件"hive.properties"以配置对应但Hive Connecor,并在该文件中增加以下两个配置属性:connector名称和Hive Metastore地址:
#connector名称,如果是Apache Hadoop2.x,则为hive-hadoop2,如果是cloudera CDH 5,则为hive-cdh5
connector.name=hive-cdh5
#hive metastore地址
hive.metasore.uri=thrift://example.net:9083
如果你有多个Hive实例,可在"etc/catalog/"下创建其他以“.properties”结尾的配置文件,每个配置文件对应一个Connector。
一旦创建好Connector,重启Prestor集群才可以启用它,之后变可以使用CLI或JDBC创建数据表,进而查询数据。
(2)Presto访问MySQL
Persto内置了MySQL connector,允许用户通过Presto引擎读取并分析MySQL数据库中的数据,甚至连接MySQL与其他数据源(比如Hive)中的数据表。
用户可以在“etc/catalog”下创建一个配置文件,比如“mysqltest.properties”,进而将MySQL Connector绑定到名为mysqltest的catalog下,mysqltest.properties内容如下:
#connector名称,一般为“mysql”
connector.name=mysql
#JDBC地址
connector-url=jdbc:mysql://example.net:3306
#访问MySQL的用户名
connector-user=presto
#访问MySQL的密码
connector-password=yinzhengjie
之后便可以使用SQL访问MySQL:
#显示mysqltest中所有的数据库
SHOW SCHEMEAS FROM mysqltest;
#显示数据库mysqltest.web下所有的数据表
SHOW TABLES FROM mysqltest.web;
SELECT * FROM mysql.web.clicks;
3>.Presto实战案例
某公司收集到一批用户浏览网页分行为数据,以文本格式保存在HDFS上,如何使用Prosto对这些数据进行高效的分析?
解决思路:
在hive中将建一个名为web的SCHEMA,并创建了一个名为web的SCHEMA,并创建一个ORC格式的分区表paga_views,用以存储用户浏览网页的行为数据,该表包含了以下五个字段(其中ds和country为分区字段):
view_time : 用户浏览网页的时间。
user_id : 用户ID。
page_url : 网页的URL。
ds :用户浏览网页的日志(精确到天)。
country :用户所在国家。
为了解决这类问题,可以分成如下图所示的五个步骤。

由于Prosto为提供数据加载的语句,所以该步骤需要在Hive中完成(实际上,前三步均可在Hive中完成,但为了演示Presto功能,前两步也在Presto中完成)。
(1)创建一张文本格式的分区数据表tmp_page_views:
CREATE SCHEMA hive.web;
CREATE TABLE hive.web.tmp_page_views(
view_time timestamp,
user_id bigint,
page_url varchar,
ds date,
country varchar
)
WITH (
format = 'TEXTFILE',
partitioned_by = ARRAY['ds','country']
)
通过WITH语句设置表的属性,包括存储格式(format)和分区字段(parititioned_by),用户可通过以下语句查看所有可设置的属性列表:
SELECT * FROM system.metadata.table_properties;
(2)使用HIVE HQL中的LOAD语句,在Hive中将数据倒入数据表tmp_page_views总。
(3)使用“CREATE TABLE ... AS”语句,创建一个ORC表page_views,它拥有跟"tmp_page_views"一样的元信息(除数据格式)和数据:
CREATE TABLE page_views
WITH (
format = 'ORC',
partitioned_by = ARRAY['ds','country']
)
AS
SELECT * FROM tmp_page_views;
(4)使用SQL查询表中的数据
SELECT view_time,user_id
FROM page_views
WHERE ds = DATA '2016-08-09' AND country = 'US';
(5)删除临时数据表tmp_page_views
DROP TABLE hive.web.tmp_page_views;
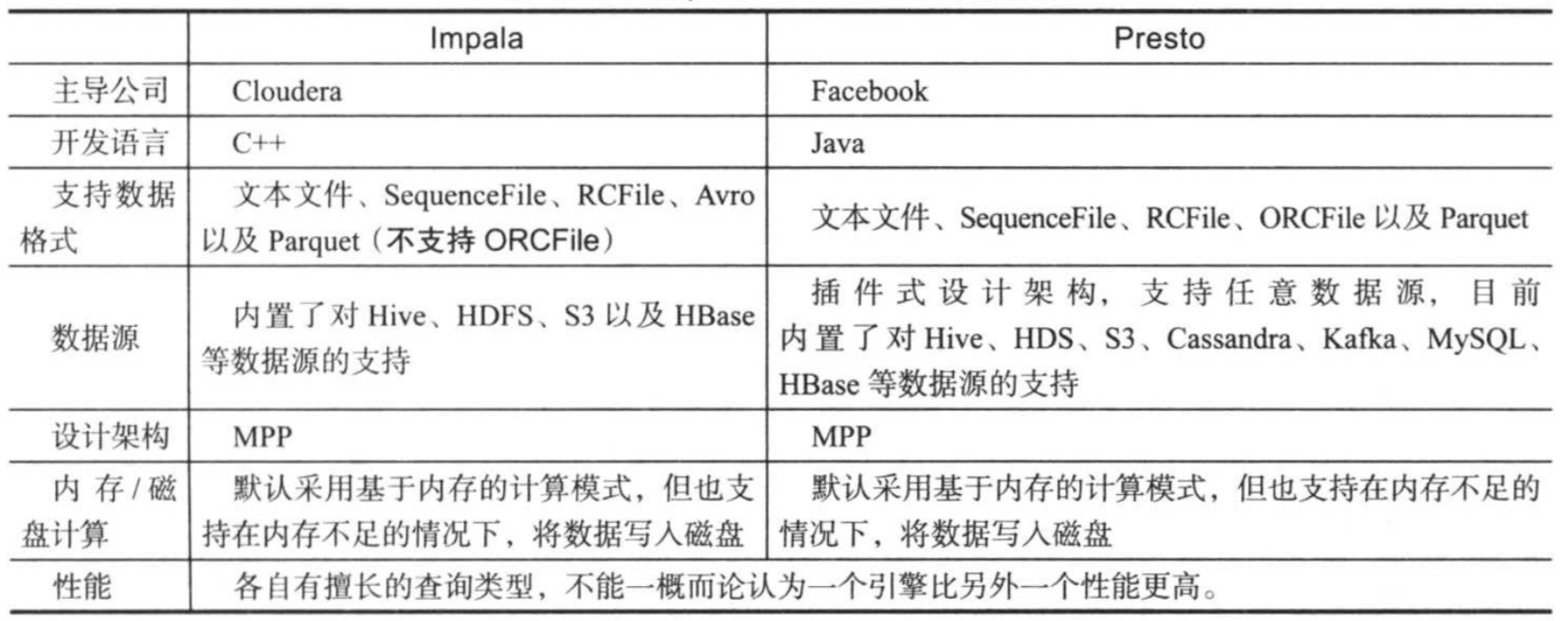
三.Impala与Presto对比
Imapla与Presto均是为了克服Hive性能地下而提出来的SQL查询引擎,它们在设计架构和查询性能优化上做了大量工作。它们两个拥有很多相同特色,但也各自有特色,它们的异同对比如下表所示。
四.博主推荐阅读
链接一:Impala快速上手教程:https://www.w3cschool.cn/impala/impala_overview.html。