内容概要:
1、安装及基本使用
2、起始请求定制
3、解析器/选择器
4、cookie及请求头处理
5、pipeline持久化
6、去重规则
7、深度和优先级
8、中间件
9、定制命令
10、信号
11、scrapy-redis
https://www.cnblogs.com/wupeiqi/articles/6229292.html
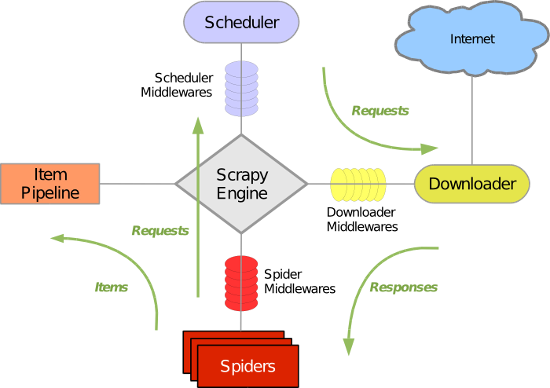
scrapy的组件及执行流程:
-引擎找到要执行的爬虫,并执行爬虫的start_requests方法,并得到一个生成器,里面是Request对象,封装了要访问的url和回调函数。
-循环生成器,将url经过去重后放到调度器中等待下载。
-下载器去调度器中获取要下载的任务(Request对象),下载完成后执行回调函数。
-回到spider的回调函数中,
如果 yield Request(),则继续放到调度器中。
如果 yield Item(),则执行pipelines处理爬取到的数据。
一、安装和基本使用
windows下scrapy的安装比较麻烦,分为4部,参照https://baijiahao.baidu.com/s?id=1597465401467369572&wfr=spider&for=pc
Linux:
1 pip install scrapy
windows:
1 pip install wheel 2 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 3 进入下载目录,执行 pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl 4 pip3 install scrapy 5 下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/
twisted:是基于事件循环的异步非阻塞网络框架
1、创建项目
scrapy startproject 项目名称 - 在当前目录中创建中创建一个项目文件(类似于Django) scrapy genspider [-t template] <name> <domain> - 穿件爬虫应用 如:scrapy gensipider -t basic oldboy oldboy.com scrapy gensipider -t xmlfeed autohome autohome.com.cn 查看所有命令:scrapy gensipider -l 查看模板命令:scrapy gensipider -d 模板名称 scrapy list - 展示爬虫应用列表 scrapy crawl 爬虫应用名称 - 运行单独爬虫应用
2、项目结构以及爬虫应用简介
创建scrapy后会有一个完整的项目框架:
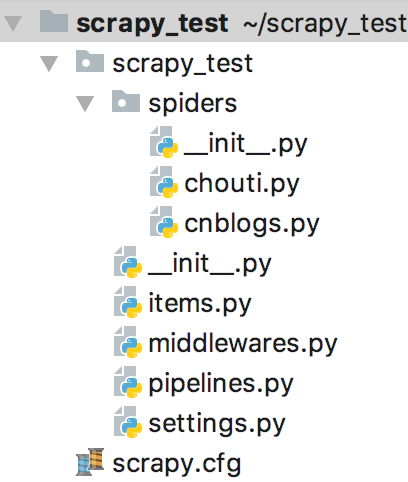
文件说明:
- scrapy.cfg 项目的主配置信息。(真正与爬虫相关的配置在settings.py中)
- items.py 设置数据存储模板,用于结构化数据。如Django中的Model
- pipelines.py 数据处理行为,如一般结构化的数据持久化。
- settings.py 配置文件。如递归的层数、并发数、延迟下载等。
- spiders 爬虫目录
以抽屉为例编写第一个爬虫:
import scrapy class ChoutiSpider(scrapy.Spider): name = 'chouti' # 外部scrapy调用的爬虫应用名称 allowed_domains = ['chouti.com'] # 允许的域名 start_urls = ['http://dig.chouti.com/'] # 起始url def parse(self, response): # 访问起始url并获取结果后的回调函数 print(response.text) # response就是返回结果
注意:
1、在这里默认情况下是打印不出东西的,因为settings里面ROBOTSTXT_OBEY = True,默认遵从协议,所以把这里改成False才行。
2、windows环境下可能会遇到编码问题:
import sys,os sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
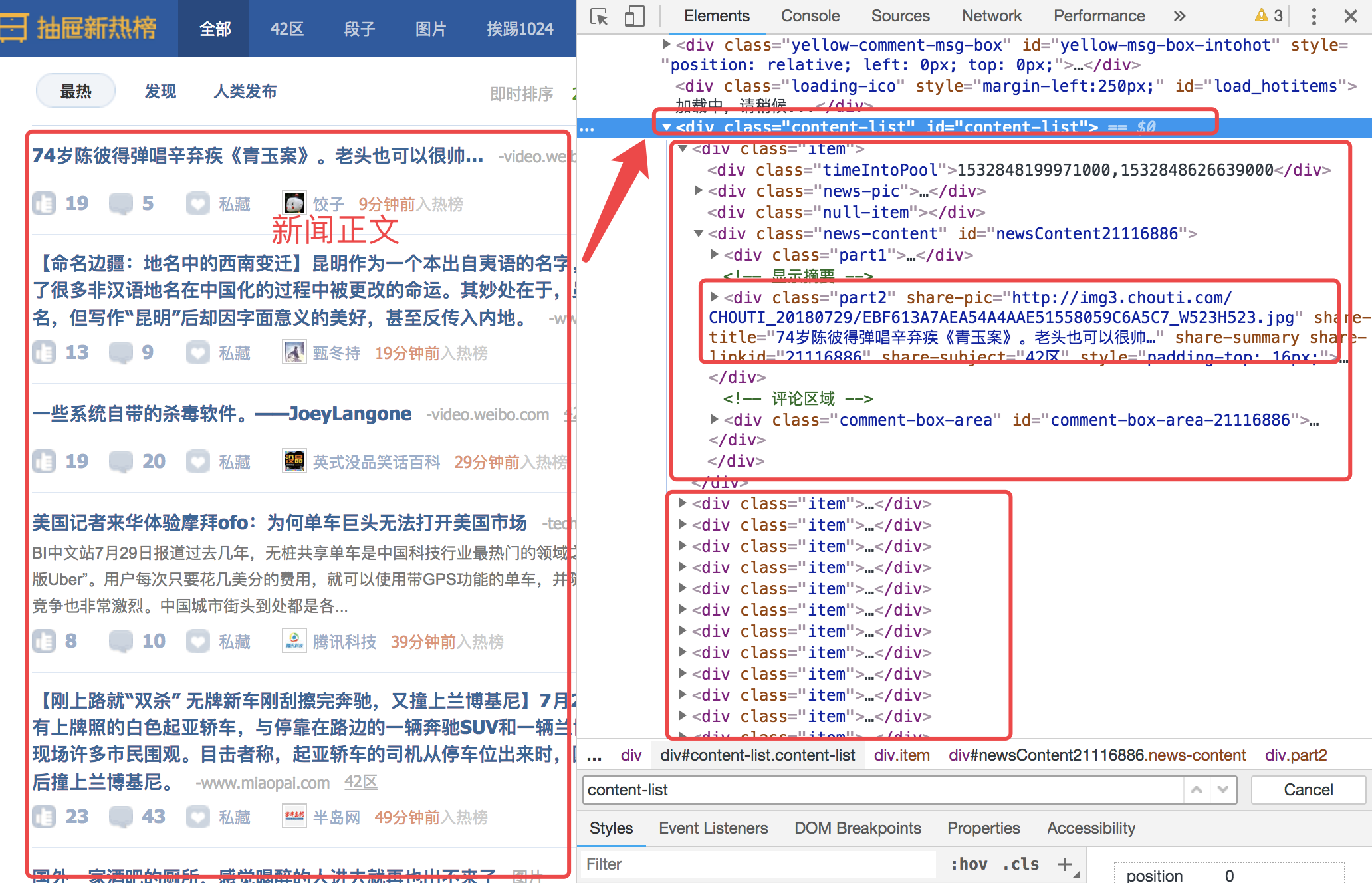
如上,需要在抽屉网中抓去热榜的所有标题,图中的框已经标好,从content-list入手,抓取每一个item中class为part2的share-title
class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['chouti.com'] start_urls = ['http://dig.chouti.com/'] def parse(self, response): """ 1.获取想要的内容 2.如果分页,继续下载内容 :param response: :return: """ # 获取当前页的内容 item_list = response.xpath('//div[@id="content-list"]/div[@class="item"]') # /子标签 # //起始位置时,是在全局进行查找;非起始位置是在当前标签的子子孙孙内部找 # ./当前对象下面找 # 获取index为0的对象中的第一个满足条件的文本 # obj = item_list[0].xpath('./div[@class="news-content"]//div[@class="part2"]/@share-title').extract_first() obj_list = item_list.xpath('./div[@class="news-content"]//div[@class="part2"]/@share-title').extract() print(obj_list) # 获取的结果是列表 #如果获取的是文本内容不是属性的话 obj = item_list[0].xpath('./div[@class="news-content"]//div[@class="show-content"]/text()').extract()
执行命令:
scrapy crawl chouti --nolog
如果分页的内容也要爬取:
import scrapy class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['chouti.com'] start_urls = ['http://www.chouti.com/'] def parse(self, response): f = open("news.txt","a+") item_list = response.xpath("//div[@id='content-list']/div[@class='item']") for item in item_list: text = item.xpath(".//a/text()").extract_first() href = item.xpath(".//a/@href").extract_first() f.write(href+" ") f.close() page_list = response.xpath("//div[@id='dig_lcpage']//a/@href").extract() for page in page_list: url = "https://dig.chouti.com" + page print(url) from scrapy.http import Request yield Request(url=url, callback=self.parse)
二、起始请求定制
方式一:源码中的方式
class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['chouti.com'] start_urls = ['http://www.chouti.com/'] cookie_dict = {} def start_requests(self): for url in self.start_urls: yield Request(url=url)
方式二:可以自定义
def start_requests(self): url_list = [] for url in self.start_urls: url_list.append(Request(url=url)) return url_list
方式一返回一个生成器,方式二返回一个可迭代对象,都能够实现,其内部是使用了iter()方法,不管是生成器还是可迭代对象,都转换成生成器。
1. 调用start_request方法并获取返回值
2. v = iter(返回值)
3. v.__next__拿到所有结果
4. 放到调度器中
三、选择器 / 解析器


1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 from scrapy.selector import Selector, HtmlXPathSelector 4 from scrapy.http import HtmlResponse 5 html = """<!DOCTYPE html> 6 <html> 7 <head lang="en"> 8 <meta charset="UTF-8"> 9 <title></title> 10 </head> 11 <body> 12 <ul> 13 <li class="item-"><a id='i1' href="link.html">first item</a></li> 14 <li class="item-0"><a id='i2' href="llink.html">first item</a></li> 15 <li class="item-1"><a href="llink2.html">second item<span>vv</span></a></li> 16 </ul> 17 <div><a href="llink2.html">second item</a></div> 18 </body> 19 </html> 20 """ 21 response = HtmlResponse(url='http://example.com', body=html,encoding='utf-8') 22 # hxs = HtmlXPathSelector(response) 23 # print(hxs) 24 # hxs = Selector(response=response).xpath('//a') 25 # print(hxs) 26 # hxs = Selector(response=response).xpath('//a[2]') 27 # print(hxs) 28 # hxs = Selector(response=response).xpath('//a[@id]') 29 # print(hxs) 30 # hxs = Selector(response=response).xpath('//a[@id="i1"]') 31 # print(hxs) 32 # hxs = Selector(response=response).xpath('//a[@href="link.html"][@id="i1"]') 33 # print(hxs) 34 # hxs = Selector(response=response).xpath('//a[contains(@href, "link")]') 35 # print(hxs) 36 # hxs = Selector(response=response).xpath('//a[starts-with(@href, "link")]') 37 # print(hxs) 38 # hxs = Selector(response=response).xpath('//a[re:test(@id, "id+")]') 39 # print(hxs) 40 # hxs = Selector(response=response).xpath('//a[re:test(@id, "id+")]/text()').extract() 41 # print(hxs) 42 # hxs = Selector(response=response).xpath('//a[re:test(@id, "id+")]/@href').extract() 43 # print(hxs) 44 # hxs = Selector(response=response).xpath('/html/body/ul/li/a/@href').extract() 45 # print(hxs) 46 # hxs = Selector(response=response).xpath('//body/ul/li/a/@href').extract_first() 47 # print(hxs) 48 49 # ul_list = Selector(response=response).xpath('//body/ul/li') 50 # for item in ul_list: 51 # v = item.xpath('./a/span') 52 # # 或 53 # # v = item.xpath('a/span') 54 # # 或 55 # # v = item.xpath('*/a/span') 56 # print(v)
抽屉自动点赞项目链接:https://www.cnblogs.com/yinwenjie/p/10861855.html
四、cookie和请求头
方式一:
1 class ChoutiSpider(scrapy.Spider): 2 name = 'chouti' 3 allowed_domains = ['chouti.com'] 4 start_urls = ['http://www.chouti.com/'] 5 cookie_dict = {} 6 7 def parse(self, response): 8 from scrapy.http.cookies import CookieJar 9 10 cookie_jar = CookieJar() 11 cookie_jar.extract_cookies(response, response.request) 12 13 # 去对象中将cookie解析到字典 14 for k, v in cookie_jar._cookies.items(): 15 for i, j in v.items(): 16 for m, n in j.items(): 17 self.cookie_dict[m] = n.value 18 19 from scrapy.http import Request 20 yield Request( 21 url="https://dig.chouti.com/login", 22 method='POST', #默认是GET 23 headers={ 24 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 25 'user-agent': 'xxxx' 26 }, 27 body="phone=8613121758648&password=woshiniba&oneMonth=1", #可以通过urlencode模块把字典自动解析成这样的格式 28 cookies=self.cookie_dict 29 )
在配置中自动设置请求头中的user-agent:
1 USER_AGENT = 'xxxxxx'
urlencode模块解析字典:
1 from urllib.parse import urlencode 2 data = {'k1': 'v1', 'k2': 'v2'} 3 body = urlencode(data) 4 #得到结果:"k1=v1&k2=v2"
方式二:
#在需要获取cookie值的请求中 Request(url=url, meta={"cookiejar": True}) #在需要用这个cookie值的请求中 Request(url=url, meta={"cookiejar": response.meta["cookiejar"]})
五、pipeline实现持久化(格式化处理)
上面这个程序在每次循环都要打开一次文件,利用pipeline可以实现只打开一次文件,在结尾关闭文件。
chouti.py:
import scrapy from scrapy1.items import Scrapy1Item class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['chouti.com'] start_urls = ['http://www.chouti.com/'] def parse(self, response): # f = open("news.txt","a+") item_list = response.xpath("//div[@id='content-list']/div[@class='item']") for item in item_list: text = item.xpath(".//a/text()").extract_first() href = item.xpath(".//a/@href").extract_first() yield Scrapy1Item(text=text, href=href)
items.py:
import scrapy class Scrapy1Item(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() text = scrapy.Field() href = scrapy.Field()
pipelines.py:
from scrapy.exceptions import DropItem class Scrapy1Pipeline(object): def __init__(self, path): #如果不使用定义from_crawler方法就不能传参数 self.f = None self.path = path @classmethod def from_crawler(cls, crawler): #初始化是用于创建pipeline对象,可以传参数 path = crawler.settings.get("HREF_FILE_PATH") return cls(path) def open_spider(self, spider): self.f = open(self.path, "w+") def process_item(self, item, spider): self.f.write(item["href"] + " ") #raise DropItem() #如果不让后续的pipeline运行就引出异常 return item #把item交给下一个pipeline的process_item方法 def close_spider(self, spider): self.f.close()
pipelines对所有爬虫生效,如果想单独设置,可以通过spider.name来设置条件。
还需要在settings中配置一下,默认这项是被注释的:
ITEM_PIPELINES = { 'xdb.pipelines.XdbPipeline': 300, #数值是优先级,小的先执行 }
六、去重规则
scrapy自动有去重功能,在'scrapy.dupefilters'文件中的BaseDupeFilter和RFPDuperFilter中
自定义一个去重功能:
from scrapy.dupefilters import BaseDupeFilter from scrapy.utils.request import request_fingerprint def ChoutiDupeFilter(BaseDupeFilter): def __init__(self): self.visited_fd = set() @classmethod def from_settings(cls,settings): return cls() def request_seen(self,request): fd = request_fingerprint(request=request) if fd in self.visited_fd: return True self.visited_fd.add(fd) def open(self): print('开始') def close(self,reason): print('结束')
配置文件:
DUPEFILTER_CLASS = 'scrapy1.dupefilters.ChoutiDupeFilter'
七、深度和优先级
深度配置文件:
DEPTH_LIMIT = 3
response.meta.get("depth",0) #获取当前深度,第一次请求取不到,赋值0
第一个请求到来,depth赋值为0,后面每次的深度在上一个请求的基础上+1
优先级
DEPTH_PRIORITY = XX
优先级 = 原来的优先级 - depth * 优先级,结果是负值,越来越小,优先级也越来越低。
八、中间件
1.下载中间件
当调度器把Request对象送给下载器下载时经过中间件。
有三种不常用的返回值:
- return HtmlResponse(url="xxx", status=200, headers=None, body=b'xxx') 不去下载器中下载,直接伪造一个响应结果,并走到第一个process_response
- return Request(url="xxx") 重新返回到调度器中,这样不会有结果,因为调度器接收后到达中间件时又会返回到调度器,陷入循环。
- raise IgnoreRequest 报错,执行process_exception
一般使用下载中间件对请求进行加工。比如在settings中有一个USER_AGENT,设置之后请求会在动在请求头中加上,就是利用的中间件添加的。
配置:
DOWNLOADER_MIDDLEWARES = { "chouti.middlewares.xxxxx": 100, "chouti.middlewares.xxxxx": 120 }# 数值越小,优先级越高
2.爬虫中间件
配置:
SPIDER_MIDDLEWARES = {
XXXXXX
}
代理中间件
方式一:自带的代理
在httpproxy.py文件的HttpProxyMiddleware类中定义里代理,在爬虫启动时在os.environ中设置即可,os.environ保存着进程的相关信息。
import os
os.environ["HTTPS_PROXIES"] = "https://root:mima@192.168.1.1:9999/"
os.environ["HTTP_PROXIES"] = "19.11.2.12"
或者可以用meta传参
yield Request(url=url, callback=xxx, meta={"proxy":"19.12.2.1"})
由于内置的代理只能使用一个代理,如果频率太快会被封,所以需要自定义代理,实现每次随机使用一个代理。
方式二:自定义代理
九、定制命令
单爬虫运行:
#在文件夹下创建一个py文件from scrapy.cmdline import execute if __name__ == "__main__": execute(["scrapy". "crawl", "chouti", "--nolog"])
多爬虫运行:
- 在spider的同级目录下创建任意目录,如:commands
- 在其中创建crawlall.py文件(文件名就是自定制的命令),如果创建了多个文件,就是创建了多个命令
View Code
1 from scrapy.commands import ScrapyCommand 2 from scrapy.utils.project import get_project_settings 3 4 5 class Command(ScrapyCommand): 6 7 requires_project = True 8 9 def syntax(self): 10 return '[options]' 11 12 def short_desc(self): 13 return 'Runs all of the spiders' 14 15 def run(self, args, opts): 16 spider_list = self.crawler_process.spiders.list() # 去spiders文件夹下获取所有的爬虫文件 17 for name in spider_list: 18 self.crawler_process.crawl(name, **opts.__dict__) # 为所有的爬虫创建任务 19 self.crawler_process.start() # 并发的开始执行 20 21 crawlall.py
- 在settings中配置
COMMANDS_MODULE = 'chouti.commands' - 执行 scrapy crawlall(就是执行文件里的run方法)
十、信号
信号是框架给用户提供的可扩展部分,可以在请求开始前、结束时、报错时等等情况下添加一些功能。
1 from scrapy import signals 2 3 class MyExtension(object): 4 def __init__(self, value): 5 self.value = value 6 7 @classmethod 8 def from_crawler(cls, crawler): 9 self = cls() 10 11 crawler.signals.connect(ext.openn, signal=signals.spider_opened) 12 crawler.signals.connect(ext.closee, signal=signals.spider_closed) 13 14 return self 15 16 def openn(self, spider): 17 print('open') 18 19 def closee(self, spider): 20 print('close')
EXTENSIONS = { 'chouti.ext.MyExtension' : 666 }
""" Scrapy signals These signals are documented in docs/topics/signals.rst. Please don't add new signals here without documenting them there. """ engine_started = object() engine_stopped = object() spider_opened = object() spider_idle = object() spider_closed = object() spider_error = object() request_scheduled = object() request_dropped = object() response_received = object() response_downloaded = object() item_scraped = object() item_dropped = object() # for backwards compatibility stats_spider_opened = spider_opened stats_spider_closing = spider_closed stats_spider_closed = spider_closed item_passed = item_scraped request_received = request_scheduled
十一、、scrapy-redis(分布式爬虫的组件)
1、redis连接配置
REDIS_HOST = '140.143.227.206' # 主机名 REDIS_PORT = 8888 # 端口 REDIS_PARAMS = {'password': 'beta'} # Redis连接参数 默认:REDIS_PARAMS = {'socket_timeout': 30,'socket_connect_timeout': 30,'retry_on_timeout': True,'encoding': REDIS_ENCODING,}) REDIS_ENCODING = "utf-8" # REDIS_URL = 'redis://user:pass@hostname:9001' # 连接URL(优先于以上配置)
2、在redis中保存去重记录:
DUPEFILTER_KEY = 'dupefilter:%(timestamp)s' DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
但是默认的去重,在把url保存到redis中时,使用的key是用时间戳拼接的,造成key值不确定,所以可以通过自定制的方式,定制一个确定的key方便取值:
from scrapy_redis.dupefilter import RFPDupeFilter from scrapy_redis.connection import get_redis_from_settings from scrapy_redis import defaults class RedisDupeFilter(RFPDupeFilter): @classmethod def from_settings(cls, settings): server = get_redis_from_settings(settings) key = defaults.DUPEFILTER_KEY % {'timestamp': 'xxx'} debug = settings.getbool('DUPEFILTER_DEBUG') return cls(server, key=key, debug=debug)
scrapy-redis的去重是把访问过的链接放在redis中一个key为 "duperfilter:xxx" 的字典中,字典中维护一个集合,如果已有该链接则返回0,如果没有则返回1。
3、将调度器放到redis中
SCHEDULER = "scrapy_redis.scheduler.Scheduler" DEPTH_PRIORITY = 1 # 广度优先 # DEPTH_PRIORITY = -1 # 深度优先 SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' # 默认使用优先级队列(默认),其他:PriorityQueue(有序集合),FifoQueue(列表)、LifoQueue(列表) # 广度优先 # SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.FifoQueue' # 默认使用优先级队列(默认),其他:PriorityQueue(有序集合),FifoQueue(列表)、LifoQueue(列表) # 深度优先 # SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.LifoQueue' # 默认使用优先级队列(默认),其他:PriorityQueue(有序集合),FifoQueue(列表)、LifoQueue(列表) SCHEDULER_QUEUE_KEY = '%(spider)s:requests' # 调度器中请求存放在redis中的key SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat" # 对保存到redis中的数据进行序列化,默认使用pickle SCHEDULER_PERSIST = False # 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空 SCHEDULER_FLUSH_ON_START = True # 是否在开始之前清空 调度器和去重记录,True=清空,False=不清空 # SCHEDULER_IDLE_BEFORE_CLOSE = 10 # 去调度器中获取数据时,如果为空,最多等待时间(最后没数据,未获取到)。 SCHEDULER_DUPEFILTER_KEY = '%(spider)s:dupefilter' # 去重规则,在redis中保存时对应的key # 优先使用DUPEFILTER_CLASS,如果么有就是用SCHEDULER_DUPEFILTER_CLASS SCHEDULER_DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter' # 去重规则对应处理的类
4、起始url放到redis中
源码流程:
1、scrapy crawl chouti --nolog
2、找到 SCHEDULER = "scrapy_redis.scheduler.Scheduler"配置,并实例化调度器对象。
#执行Scheduler.from_crawler @classmethod def from_crawler(cls, crawler): instance = cls.from_settings(crawler.settings) instance.stats = crawler.stats return instance #执行Scheduler.from_settings - 读取配置文件: SCHEDULER_PERSIST # 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空 SCHEDULER_FLUSH_ON_START # 是否在开始之前清空 调度器和去重记录,True=清空,False=不清空 SCHEDULER_IDLE_BEFORE_CLOSE # 去调度器中获取数据时,如果为空,最多等待时间(最后没数据,未获取到)。 - 读取配置文件: SCHEDULER_QUEUE_KEY # %(spider)s:requests SCHEDULER_QUEUE_CLASS # scrapy_redis.queue.FifoQueue SCHEDULER_DUPEFILTER_KEY # '%(spider)s:dupefilter' DUPEFILTER_CLASS # 'scrapy_redis.dupefilter.RFPDupeFilter' SCHEDULER_SERIALIZER # "scrapy_redis.picklecompat" - 读取配置文件: REDIS_HOST = '140.143.227.206' # 主机名 REDIS_PORT = 8888 # 端口 REDIS_PARAMS = { 'password': 'beta'} # Redis连接参数 默认:REDIS_PARAMS = {'socket_timeout': 30,'socket_connect_timeout': 30,'retry_on_timeout': True,'encoding': REDIS_ENCODING,}) REDIS_ENCODING = "utf-8" - 实例化Scheduler对象
3、爬虫开始执行起始url
#调用Scheduler.enqueue_request() def enqueue_request(self, request): #判断请求是否需要过滤 #判断去重规则是否已经存在 if not request.dont_filter and self.df.request_seen(request): self.df.log(request, self.spider) return Flase #已经访问过,不需要再访问 if self.stats: self.stats.inc_value('scheduler/enqueued/redis', spider=self.spider) self.queue.push(request) return True
4、下载器去调度器中获取任务
def next_request(self): block_pop_timeout = self.idle_before_close request = self.queue.pop(block_pop_timeout) if request and self.stats: self.stats.inc_value('scheduler/dequeued/redis', spider=self.spider) return request
相关问题:
十二、其他配置文件