我们在上一节最后讲到了,在一个ip下重复向一个URL发送请求,会被封ip,这时候就要用到代理ip了。方法很简单,就是随便找一个ip代理的网站,很多免费的也可以,就是要注意类型,如果我们要爬取的url是https的要找对应的类型。
比方我们从站长之家上爬一下本机的IP
import requests from bs4 import BeautifulSoup url = 'https://ip.tool.chinaz.com/' r = requests.get(url=url) page_html = r.text soup=BeautifulSoup(page_html) tags = soup.find_all('div',class_=['WhwtdWrap','bg-blue08','col-gray03']) for tag in tags: print(tag.text)
然后就能爬到本机的ip

打了个码,然后我们在请求的时候添加一个proxies参数,代理的地址是从网上随便找的!
import requests from bs4 import BeautifulSoup url = 'https://ip.tool.chinaz.com/' r = requests.get(url=url,proxies={'https':'188.165.141.114:3129'}) # r = requests.get(url=url) page_html = r.text soup=BeautifulSoup(page_html,'lxml') tags = soup.find_all('div',class_=['WhwtdWrap','bg-blue08','col-gray03']) for tag in tags: print(tag.text)
看看出来的效果
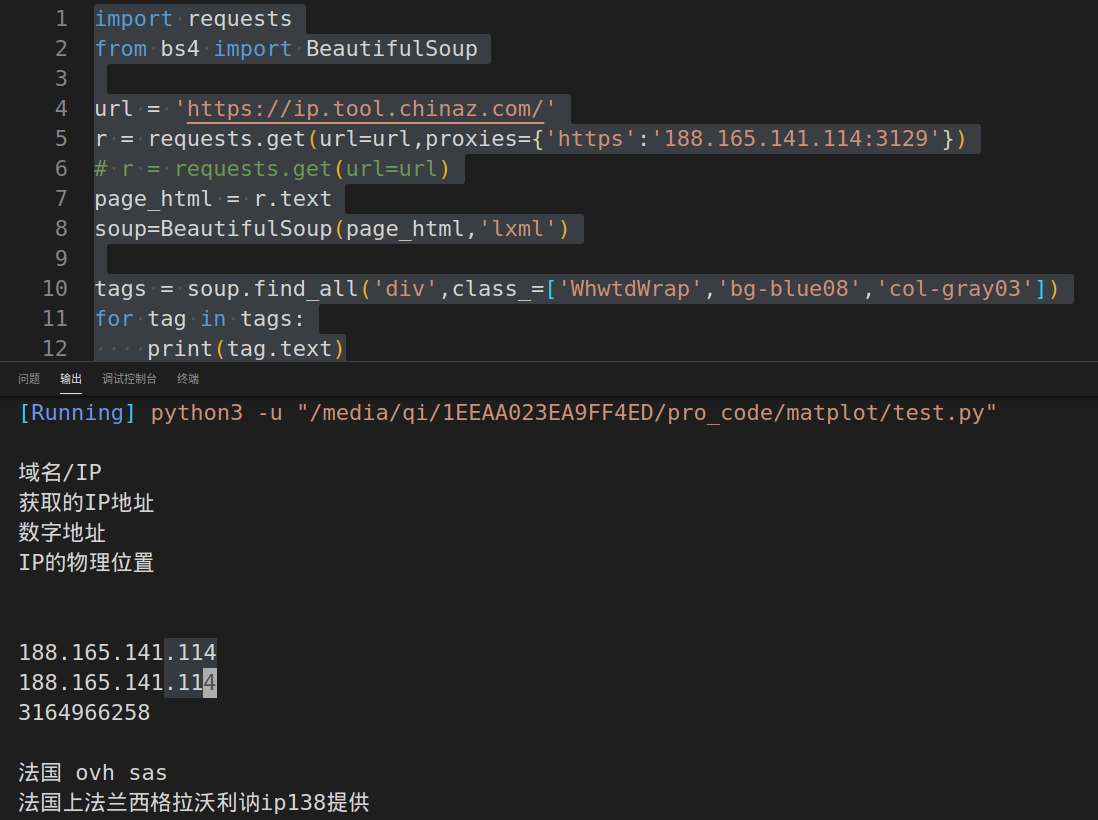
不知道为什么用jupyter一直出不来效果,初步怀疑是和浏览器设置有关系。但是在vscode里就能正常工作,只是时间有些慢,免费的还是不好用。
随机选择代理
即便是使用了代理,我们也不能只用一个,那么和不用的效果是一样的,依旧会被封。所以要建立一个列表,然后把网上找的代理服务器放出来
proxy_list = [ {'https':'120.83.108.207:9999'}, {'https':'171.35.140.65:9999'}, {'https':'183.146.45.2:9999'} ] import random request = requests.get(url=url,headers=header,proxies=random.choice(proxy_list))
然后用random随机抽取就行了。如果还想简单的话就可以把提供代理地址的页面爬下来,把地址放在列表里直接用就好了!