爬虫定义
爬虫是一段代码,用来模仿浏览器访问网站的过程,可以从服务器上获取数据。
爬虫分类
按照常规的分类,爬虫可以分为下面几种
- 通用爬虫——抓取系统的重要组成部分,用来抓取一整面的数据
- 聚焦爬虫——建立在通用爬虫的基础上,抓取页面中的局部数据
- 增量式爬虫——用来抓取定期更新的数据
爬虫的矛与盾
反爬机制
门户网站可以通过制定相应的策略或技术手段,防止爬虫程序
反反爬策略
爬虫程序可以通过制定相关的策略或技术手段,啪姐门户网站中的反爬机制,从而获取数据
robots.txt协议
robots.txt是一个君子协议,用来规定网站中哪些数据可以被爬取哪些不可以。我们可以看一下淘宝的这个链接
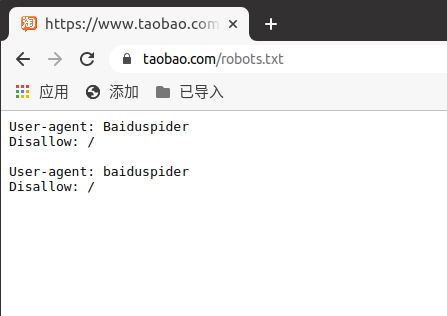
但是这是个防君子不防小人的协议,并没有从实际的技术上做到反爬。
requests模块
requests模块是python原生的一款基于网络请求的模块,功能强大,使用方便。使用的流程
- 指定url
- 发起请求
- 获取响应数据
- 持久化存储