教材内容总结
我们这周学习的内容是教材的第十一章和第十二章。
第十一章
客户端-服务器编程模型:
每个网络应用都是基于客户端-服务器模型的。在该模型中,一个应用是由一个服务器进程和一个或多个客户端进程组成的。
服务器管理某种资源。一个Web服务器管理了一组磁盘文件,它会代表客户端进行检索和执行;一个FTP服务器管理了一组磁盘文件,它会为客户端进行存储和检索;一个Emial服务器管理了一些文件,它为客户端进行读和更新。
客户端-服务器模型中的基本操作是事务,它由四步组成:
客户端向服务器发送一个请求,发起一个事务;
服务器收到请求后,解释之,并操作它的资源;
服务器给客户端发送一个响应,例如将请求的文件发送回客户端;
客户端收到响应并处理它,例如Web浏览器在屏幕上显示网页。
认识到客户端和服务器是进程而不是具体的机器或主机是重要的。
网络
对于一个主机而言,网络只是又一种I/O设备,作为数据源和数据接收方。
最流行的局域网是以太网(Ethernet),一个以太网段包括一些电缆(通常是双绞线)和一个集线器。每根电缆都有相同的带宽,它们一端连接到主机的适配器,另一端则连接到集线器的一个端口上。集线器不加分辨地从一个端口上收到的每个位复制到其他所有的端口上。
每个以太网适配器都有一个全球唯一的48位地址,一台主机可以发送一帧数据到这个网段内的其他主机。每个帧包括了固定数量的头部位,用来标识此帧的源和目的地址,以及此帧的长度,之后便是数据位的有效载荷。每个网络适配器都能看到这个帧,但是只有目的主机才能实际读取它。
通过网桥,多个以太网段可以连接成较大的局域网,称为桥接以太网。网桥比集线器更充分地利用了网线带宽。
在更高的层次中,多个不兼容的局域网可以通过路由器连接,组成一个互联网。
互联网的一个重要特性是,它能连接完全不兼容的局域网和广域网,方法是通过协议软件,它消除了不同网络之间的差异。这种协议必须提供两种基本能力:
命名机制,每台主机被分配至少一个互联网络地址,这个地址唯一地标识了这台主机。
传送机制。定义包含包头和有效载荷的数据包。
因特网域名
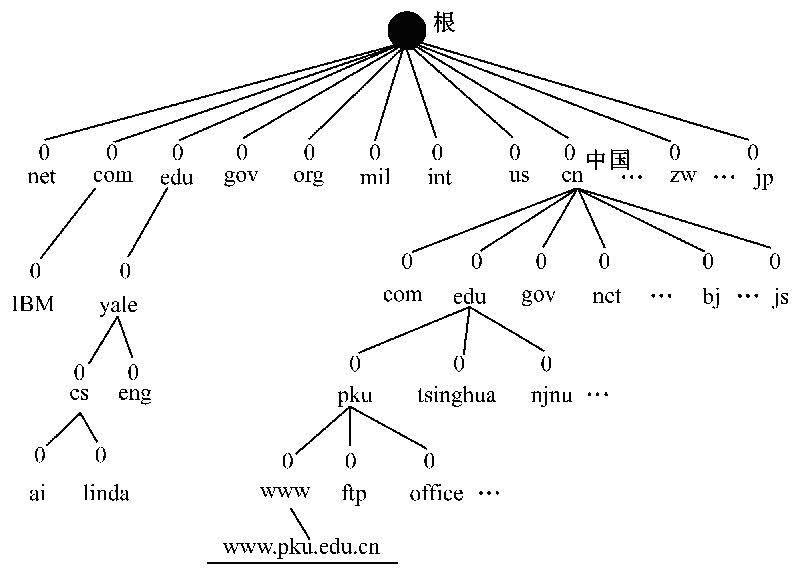
第十二章
线程执行模型:
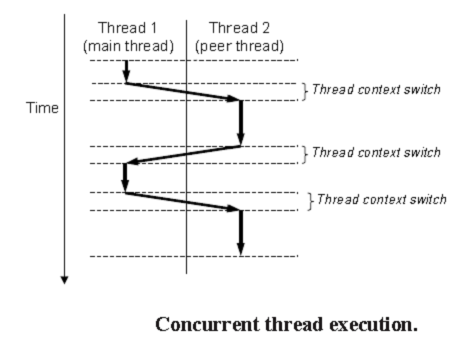

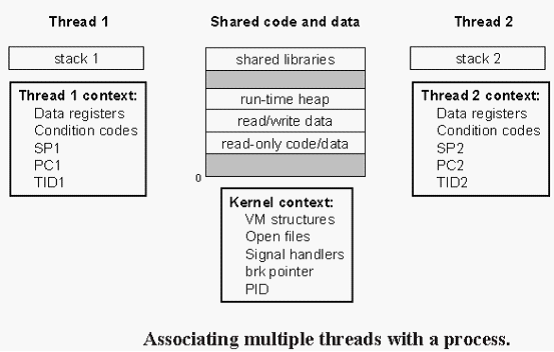
基于进程的并发编程:
构造并发编程最简单的方法就是用进程,使用那些大家都很熟悉的函数,像fork、exec和waitpid。
步骤:
1)服务器监听一个监听描述符上的连接请求。
2)服务器接受了客户端1的连接请求,并返回一个已连接描述符。
3)在接受了连接请求之后,服务器派生一个子进程,这个子进程获得服务器描述符表的完整拷贝。子进程关闭它的拷贝中的监听描述符3,而父进程关闭它的已连接描述符4的拷贝,因为不再需要这些描述符了。
4)子进程正忙于为客户端提供服务,父进程继续监听新的请求。
注意:子进程关闭监听描述符和父进程关闭已连接描述符是很重要的,因为父子进程共用同一文件表,文件表中的引用计数会增加,只有当引用计数减为0时,文件描述符才会真正关闭。所以,如果父子进程不关闭不用的描述符,将永远不会释放这些描述符,最终将引起存储器泄漏而最终消耗尽可以的存储器,是系统崩溃。



教材问题以及解决
1.为什么父进程关闭了已经连接描述符后,子进程仍然能够使用该连接符和客户端通信?
答:当父进程派生子进程时,它得到一个已连接描述符的剧本,并将相关文件表中的引用计数从1增加到2,当父进程关闭它的描述符副本后,引用计数就从2减少到1,因为内核不会关闭一个文件,直到它的引用数完全减少到0,所有子进程的连接端会始终保持打开的状态。
2.有关死锁问题
死锁(Deadlock),这里指的是进程死锁,是个计算机技术名词。它是操作系统或软件运行的一种状态:在多任务系统下,当一个或多个进程等待系统资源,而资源又被进程本身或其它进程占用时,就形成了死锁。有个变种叫活锁。
参考:
(http://blog.csdn.net/joejames/article/details/37960873)
代码调试以及解决
关于fock进程:
#include<unistd.h>
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<stdarg.h>
#include<errno.h>
#define LEN 2
void err_exit(char *fmt,...);
int main(int argc,char *argv[])
{
pid_t pid;
int loop;
for(loop=0;loop<LEN;loop++)
{
if((pid=fork()) < 0)
err_exit("[fork:%d]: ",loop);
else if(pid == 0)
{
printf("Child process
");
}
else
{
sleep(5);
}
}
return 0;
}
第一次看这个多进程代码的时候,自己是有一些疑问的,为什么这段程序会创建3个子进程,而不是两个,为什么在第20行后面加上一个return 0;就创建的又是两个子进程了?原来一直搞不明白,后来了解了C语言程序的存储空间布局以及在fork之后父子进程是共享正文段(代码段CS)之后才明白了道理。
我们可以先从c语言的空间布局去了解。
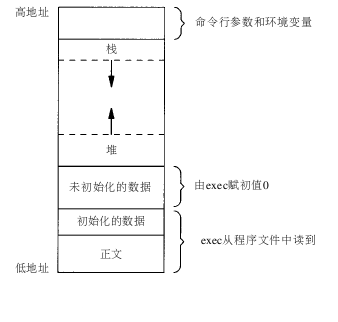
了解了C程序在存储器的布局之后,我们再来了解fork的内存复制机制,关于这个,我们只需要了解一句话就够了,“子进程复制父进程的数据空间(数据段)、栈和堆,父、子进程共享正文段。”也就是说,对于程序中的数据,子进程要复制一份,但是对于指令,子进程并不复制而是和父进程共享。在下面我又重新根据上面的代码改了一份代码。
#include<unistd.h>
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<stdarg.h>
#include<errno.h>
#define BUFSIZE 512
#define LEN 2
void err_exit(char *fmt,...);
int main(int argc,char *argv[])
{
pid_t pid;
int loop;
for(loop=0;loop<LEN;loop++)
{
printf("Now is No.%d loop:
",loop);
if((pid=fork()) < 0)
err_exit("[fork:%d]: ",loop);
else if(pid == 0)
{
printf("[Child process]P:%d C:%d
",getpid(),getppid());
}
else
{
sleep(5);
}
}
return 0;
}
现在我们可以开始解答我们的疑问了,
首先父进程执行循环,通过fork创建一个子进程,然后sleep5秒。
再来看父进程创建的这个子进程,这里我们记为子进程1.子进程1完全复制了这个父进程的数据部分,但是需要注意的是它的正文段是和父进程共享的。也就是说,子进程1开始执行代码的部分并不是从main的 { 开始执行的,而是主函数执行到哪里了,它就接着执行,具体而言就是它会执行fork后面的代码。所以子进程1首先会打印出它的ID和它的父进程的ID。然后继续第二遍循环,然后这个子进程1再来创建一个子进程,我们记为子进程11,子进程1开始sleep。
子进程11接着子进程1执行的代码开始执行(即fork后面),它也是打印出它的ID和父进程ID(子进程1),然后此时loop的值再加1就等于2了,所以子进程2直接就返回了。
那个子进程1sleep完了之后也是loop的值加1之后变成了2,所以子进程1也返回了!
然后我们再返回去看父进程,它仅仅循环了一次,sleep完之后再来进行第二次循环,这次又创建了一个子进程我们记为子进程2。然后父进程开始sleep,sleep完了之后也结束了。
那么那个子进程2怎么样了呢?它从fork后开始执行,此时loop等于1,它打印完它的ID和父进程ID之后,就结束循环了,整个子进程2就直接结束了!

这样就可以很好的解释进程的问题了。
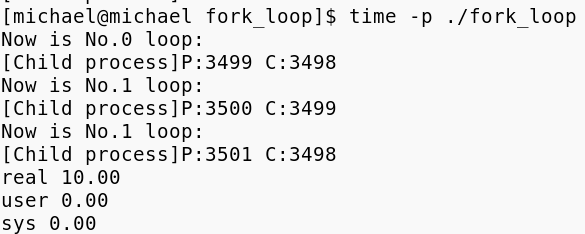
从代码运行的截图中,我们可以清晰地看出,3498进程就是我们的主进程,3499就是子进程1,3500就是子进程11,3501就是子进程2。
代码托管

学习与感悟
本周主要学习代码的部分,经过自己的探索了解了每个代码的具体含义,并把每个代码都进行了实际操作,达到了正确的结果,不足之处在于细节上还不是很理解,还需要慢慢消化
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 |
|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 |
| 第一周 | 10 /10 | 1/1 | 10/10 |
| 第二周 | 40 /70 | 2/4 | 18/38 |
| 第三周 | 150/200 | 3/7 | 15/60 |
| 第四周 | 160/210 | 6/8 | 23/70 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式
:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
参考:软件工程软件的估计为什么这么难,软件工程 估计方法
计划学习时间:20小时
实际学习时间:23小时
改进情况:
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)
参考资料
《深入理解计算机系统V3》学习指导