Hadoop YARN
一、概述:
Hadoop1.0之前只有MapReduce的运行框架JobTracker,集群里面只有两种节点,一个是master,一个是worker。master既做资源调度又做程序调度,worker只是用来参与计算的。Hadoop2.0之后加入了YARN集群,Yarn集群的主节点承担了资源调度,Yarn集群的从节点中会选出一个节点(这个由redourcemanager决定)进行应用程序的调度。
1、JobTracker(Hadoop1.0)MR1
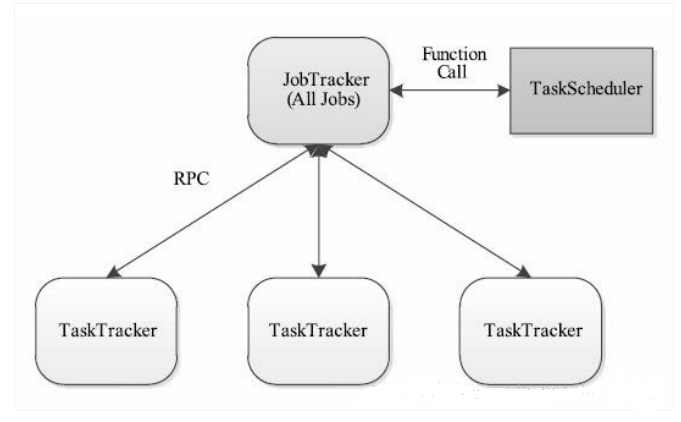
1.1、JobTracker:是集群事务的集中处理点,JobTracker和NameNode是单点,存在单点故障
1.2、JobTracker:既要维护Job的状态又要维护Job的task的状态
1.3、在TaskTracker端,用Map/Reduce Task作为资源的表示过于简单,没有考虑到 CPU、内存等资源情况,两个需要消耗大内存的 Task 调度到一起,很容易出现 OOM!
1.4、TaskTracker 把资源强制划分为 Map/Reduce Slot,当只有 MapTask 时,Reduce Slot 不能用;当只有 Reduce Task 时,Map Slot 不能用,容易造成资源利用不足。
图-1 JobTracker
2、YARN(Hadoop2.0)
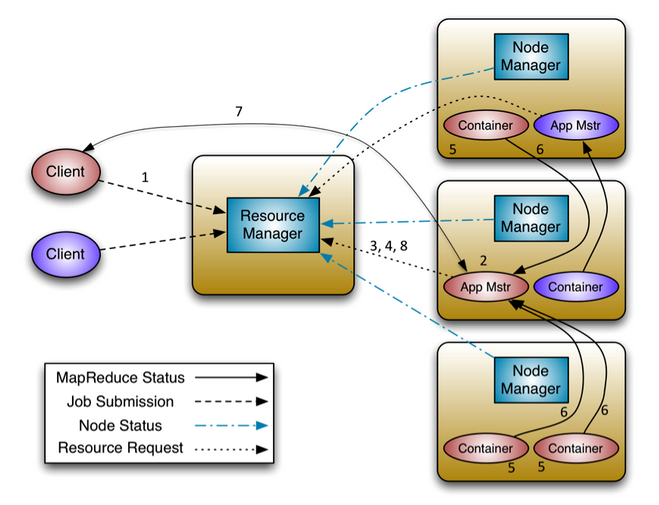
2.1、Yarn架构设计是主从架构:分为 ResourceManager 和 NodeManager 。ResourceManager:负责统计和反馈集群整体信息,Node Manager:负责反馈节点信息和启动/停止。yarn与运行的用户程序完全解耦,可以运行各种类型的分布式运算程序如:mapreduce、storm程序、spark程序、tez等
2.2、YARN/MRv2:将 JobTracker 主要的资源管理功能和作业调度功能分开作为两个独立的进程,即Resource Scheduler和Applications Management
2.3、Resource Scheduler调度资源通过Resource Request和Container
2.4、Client 的各种应用以共享、安全、多租户的形式使用整个集群资源
2.5、Yarn架构中的Resource Manager通过反馈信息感知整个集群拓扑结构,保证集群资源调度和数据访问的高效性
图-2YARN
二、ResourceManager
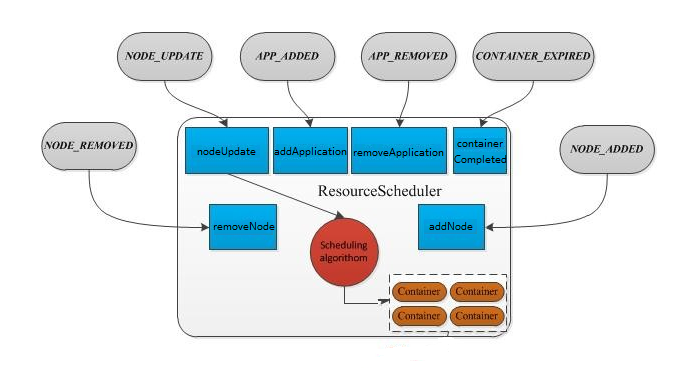
1、ResourceManager主要处理6种事件:NODE_REMOVED、NODE_ADDED、APPLICATION_ADDED、APPLICATION_REMOVED、CONTAINER_EXPIRED、NODE_UPDATE
三、Resource Scheduler
1、调度策略
1.1、FIFO Scheduler(先进先出)
图-3 FIFO Scheduler
1、FIFO Scheduler策略:把提交的应用按先后顺序排成一个FIFO队列。在进行资源分配的时候,Resource Scheduler按队列先后顺序分配资源,待前面的应用需求满足后,再给下一个分配。大的应用可能会占用所有集群资源,这就导致其它应用被阻塞
1.2、Capacity Scheduler(预先分配资源模式)
图-4 Capacity Scheduler
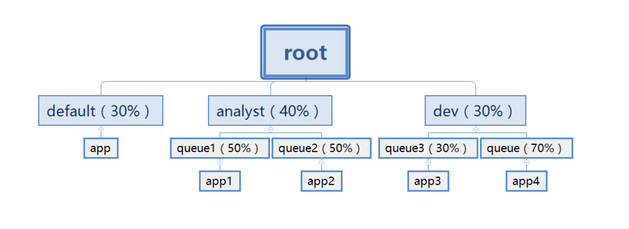
1、Capacity Scheduler策略,支持多队列。每个队列有独立的资源,队列的结构和资源是可以进行配置的(属性yarn.sheduler.capacity..),子队列每个队列的资源是在父队列获得的全部资源的基础上再分配
2、队列以分层方式组织资源,设计了多层级别的资源限制条件,比如队列资源限制、用户资源限制、用户应用程序数目限制,以更好的让多用户共享一个Hadoop集群
3、队列里的应用以FIFO方式调度,每个队列可设定一定比例的资源最低保证和使用上限
4、当一个队列资源不够用而另一个队列的资源有剩余时,Capacity Scheduler根据“弹性队列”(queue elasticity))可暂时将剩余资源共享给资源不够用的队列
5、每个队列有严格的访问控制。用户只能向自己的队列里面提交任务,而且不能修改或者访问其他队列的任务,但是一个用户可属于一个或多个队列
6、yarn支持动态修改调整容量、权限等的分配,可以在运行时直接修改。
7、yarn支持管理员操作:在运行时,添加一个队列;但是不能删除一个队列;在运行时暂停某个队列;将一个队列被设置成了stopped,用户不能向次队列或者子队列上提交任务
8、Capacity Scheduler策略:有一个专门的队列用来运行小任务,为小任务专门设置一个队列会预先占用一定的集群资源
1.3、Fair Scheduler(公平调度模式)
图-5 Fair Scheduler
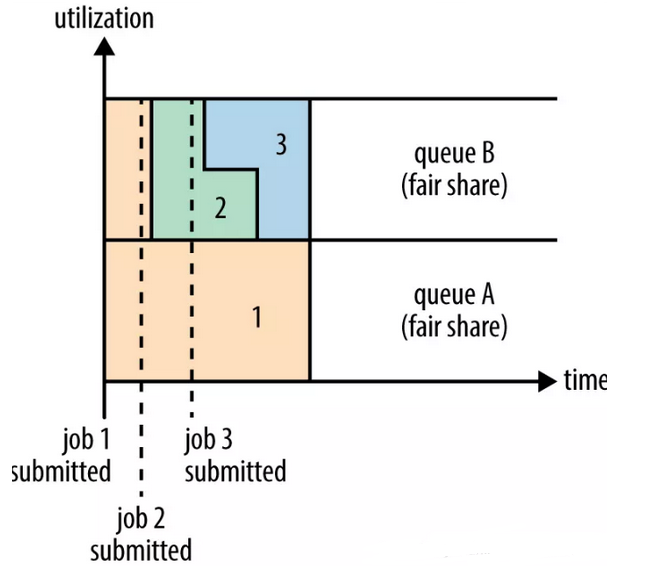
1、Fair Scheduler策略,支持多队列。每个队列有独立的资源,每个队列中的资源可以配置。同一队列中的Job都会分配到资源,但是优先级越高分配的资源越多。
2、Fair Scheduler调度器的使用:通过yarn-site.xml配置文件中的yarn.resourcemanager.scheduler.class参数进行配置配置FairScheduler类的全限定名: org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler
3、Fairs Scheduler策略:不需要预先占用一定的系统资源,Fair Scheduler会为所有运行的Job动态的调整系统资源
2、Resource Request(可序列化Java对象)
2.1、ApplicationMaster向资源调度器申请资源,需向它发送一个ResourceRequest列表,列表中每个ResourceRequest描述了一个资源单元的详细需求
2.2、ResourceRequest示例
message ResourceRequestProto {
optional PriorityProto priority = 1; // 资源优先级
optional string resource_name = 2; // 资源名称(期望资源所在的host、rack名称等)
optional ResourceProto capability = 3; // 资源量(仅支持CPU和内存两种资源)
optional int32 num_containers = 4; // 满足以上条件的资源个数
optional bool relax_locality = 5 [default = true]; //是否支持本地性松弛
3、Container
3.1、一般而言,一个Container可用于运行一个任务(ApplicationMaster、各类Task(map task、reduce task))
3.2、Container可能在任意节点上,它们的位置通常而言是随机的
3.3、Container是动态资源分配的概念。用户可以根据需求,在Yarn设定Container的范围内,设置运行 Application Master 和各类 Task 的Container
3.4、Container只能位于一个节点上。因此,Container包含的资源,最大也就是一个NodeManager的资源大小
3.4、Container分为两大类:
1、运行ApplicationMaster的Container:由ResourceManager申请和启动的,并要求对应的Node Manager启动引用程序的ApplicationMaster
2、运行各类Task的Container:由ApplicationMaster向ResourceManager申请的,并由ApplicationMaster根据反馈信息与NodeManager通信,NodeManager启动。
3.5、资源调度器向申请资源的ApplicationMaster返回分配到的资源描述Container。Container可看做一个可序列化Java对象
message ContainerProto {
optional ContainerIdProto id = 1; //container id,在整个集群中,Id是全局唯一的
optional NodeIdProto nodeId = 2; //container(资源)所在节点,NodeManager的ID
optional string node_http_address = 3;
optional ResourceProto resource = 4; //container资源量,Container具体会占用多少的资源,目前包含:CPU core+ Memory in MB
optional PriorityProto priority = 5; //container优先级,本Container优先分配给哪个任务来运行
optional hadoop.common.TokenProto container_token = 6; //container token,用于安全认证,使用Container之前,必须拥有该Container的token标记
}
四、Application Master
1、用户提交程序时,可指定唯一的Applications Master所需要的资源。默认情况下,运行ApplicationMaster的Container的内存大小是 1.5G,CPU CORE是 1
2、MRAppMaster是MapReduce的ApplicationMaster实现,使得MapReduce计算框架可以运行于YARN之上。
3、MRAppMaster负责管理MapReduce作业的生命周期:创建MapReduce作业----->轮询的方式通过RPC协议向ResourceManager申请资源----->与NodeManage通信要求其启动Container,运行任务----->监控作业的运行状态----->当任务失败时重新启动任务等
4、各个任务通过摸个PRC协议向Application Master汇报自己的状态和进度。如果container出现故障或任务失败,AM会重新向调度器申请资源或重新启动任务。当容器运行完成, ApplicationMaster 将会向 ResourceManager 注销这个容器;如果是整个作业运行完成,其也会向 ResourceManager 注销自己。
5、AM出现故障后,ASM会重启它,而由AM自己从之前保存的应用程序执行状态中恢复应用程序
6、ApplicationMaster需将该任务运行环境(包含运行命令、环境变量、依赖的外部文件等)连同资源调度器返回的Container中的资源信息封装到ContainerLaunchContext对象中。每个ContainerLaunchContext和对应的Container信息(被封装到了ContainerToken中)将再次被封装到StartContainerRequest中,App Mstr通过StartContainerRequest与对应的NodeManager通信,要求NodeManager启动Container,运行task。
message ContainerLaunchContextProto {
repeated StringLocalResourceMapProto localResources = 1; //Container启动以来的外部资源
optional bytes tokens = 2;
repeated StringBytesMapProto service_data = 3;
repeated StringStringMapProto environment = 4; //Container启动所需的环境变量
repeated string command = 5; //Container内部运行的任务启动命令,如果是MapReduce的话,Map/Reduce Task启动命令就在该字段中
repeated ApplicationACLMapProto application_ACLs = 6;
}
五、Node Manager
1、Node Manager提供给Resource Manager的资源包括CPU+内存
1.1、yarn.nodemanager.resource.memory-mb:设定总的内存数量,默认值为8G,该值可以大于实际内存
1.2、yarn.nodemanager.resource.cpu-vcores:设定该节点提供的虚拟CPU数量,默认是8核,该值可以大于实际核心数量
2、一个container所占用的系统资源是根据其运行的程序和启动的程序的命令决定的,这也是为什么Node Manager提供给Resource Manager可以大于系统本身的资源
3、Node Manager与ApplicationMaster和ResourceManager交互,
3.1、主动通过ResourceTrackerProtocol协议向 ResourceManager 注册,并向ResourceManager 汇报各个Container的运行状态和节点健康状态。
Node Manager还会向 ResourceManager 领取 Container 相关命令并执行如:重新初始化Container,清理Container等
3.1、接受来自ApplicationMaster的ContainerManagementProtocol协议,获取Container的运行状态或执行与 Container 相关的命令如启动,杀死Container等
4、NodeManager内部架构:
图-6 NodeManager内部架构
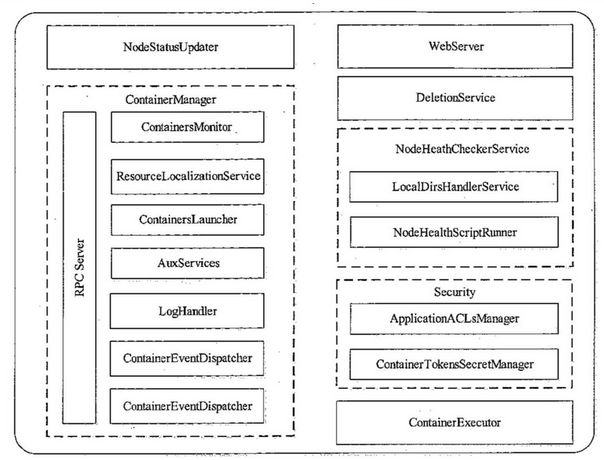
4.1、NodeStatusUpdater: 这个组件是NodeManager与RM通信的唯一通道,包括NM注册之后向RM的注册汇报资源,以及周期性的汇报节点信息和Container的运行状态,同时RM会返回给待清理的Container列表,待清理的应用程序,诊断信息等
4.2、ContainerManager: 该组件是NodeManager最核心的组件之一,它内部有很多子组件组成,如上图所示
-RPC Server:该协议实现了ContainerManagementProtocol协议,实现AM与NM之前的通信通道,通过该协议接受来自各个AM的启动或者杀死Container的命令
-ResourceLocalizationService:负责Container所需资源的本地化,按照资源描述将资源从HDFS上下载所需资源,并将这些资源均摊给各个磁盘以防数据热点
-ContainerLauncher: 维护一个线程池以并行的方式完成Container的操作,比如来自AM的启动Container,来自AM或者RM的kill Container
-AuxServices:NM允许用户添加附属服务
-ContainersMonitor: 监控Container资源的使用状况,周期性的检查Container资源使用情况,一旦有Container超过它允许使用资源的上限则kill掉
-Loghandler:可插拔的组件,控制Container日志保存的方式
-ContainerEventDispatcher: Container的事件调度器,负责将ContainerEvent类型的事件调度给对应Container的状态机ContainerImpl
-ApplicationEventDispatcher:Application的事件调度器,负责将ApplicationEvent类型的事件调度给Application的状态机ApplicationImpl
4.3、ContainerExecutor:它可与底层的操作系统交互,安全存放Container的文件和目录,进而安全的启动和清理Container
4.4、NodeHealthCheckerService: 周期性的运行一个向磁盘写文件的脚本,检测节点的健康状态,并汇报给RM
4.5、DeletionService:NodeManager删除文件组件
4.6、Security: 安全模块
4.7、WebServer: web页面展示该节点上应用程序的状态
六、附录
第一部分:yarn的内存管理
1、yarn.nodemanager.resource.memory-mb 该节点上yarn可以使用的物理内存总量
2、yarn.scheduler.minimum-allocation-mb 单个任务可以使用最小物理内存量,默认1024m
3、yarn.scheduler.maximum-allocation-mb 单个任务可以申请的最多的内存量,默认8192m
4、yarn.scheduler.increment-allocation-mb: 2048
5、yarn.nodemanager.vmem-pmem-ratio 任务使用1m物理内存最多可以使用虚拟内存量,默认是2.1
6、yarn.nodemanager.pmem-check-enabled 是否启用一个线程检查每个任务证使用的物理内存量,如果任务超出了分配值,则直接将其kill,默认是true
7、yarn.nodemanager.vmem-check-enabled 是否启用一个线程检查每个任务证使用的虚拟内存量,如果任务超出了分配值,则直接将其kill,默认是true
第二部分:yarn cpu的管理
1、yarn.nodemanager.resource.cpu-vcores 该节点上yarn可使用的虚拟cpu个数,默认是8个。推荐将该值为与物理cpu核数相同
2、yarn.scheduler.minimum-allocation-vcores 单个任务可申请最小cpu个数,默认1
3、yarn.scheduler.maximum-allocation-vcores 单个任务可以申请最多虚拟cpu个数,默认是32.
4、vcore : 虚拟核 1个物理核为2个虚拟核