前言
线性二分查找在查找目标数据的时候,每次都是进行二等分取区间。但是,当出现某种极端的情况时,这种查找就会显得比较低效。
本文将古典概率模型与线性二分查找算法结合,希望找到一种高效的非线性二分查找算法。
算法思想
我们认为,在每一次进行二分时,前面的二分方式,对本次二分是有影响的。举例来说,在进行一次二分查找时,在此之前查找的结果是【‘左’,‘左’,‘左’】亦或者【‘右’,‘右’,‘右’】。在这两种情形下,前者目标点靠近左端点的概率大幅增加,而后者目标点靠近右端点的概率大幅增加。另外一种情况是【‘左’,‘右’,‘左’,‘右’,‘左’,‘右’】,这说明目标点在下一次二分时,靠近两端的可能性并没有差别。还有一种情况是【‘左’,‘右’,‘左’,‘左’,‘左’】,这说明目标点在下一次二分时,靠近左端点的可能性大幅增加。
由此我们认为,在进行二分时,仅前面连续同符号的分类方式对下一次二分查找有影响。当前面连续同符号的分类方式不止一次时,下一次二分查找便不再采用等分的方式,而是向相应的端点靠近选取。
非线性二分点的确定
假设二分查找的总区间为mn,经过K次查找之后,下一次查找的区间为mq,下一次的二分点假设是p点,x0是的目标点。
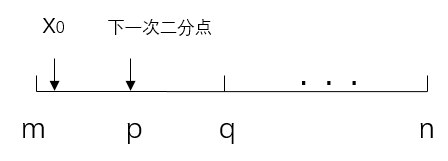
我们希望二分点的位置p,使点x0落在mp段与pq段的概率相等。即:
P(x0 in mp | 前K次分类) = P(x0 in pq | 前K次分类)
而我们认为,只有前面连续同符号的分类方式对下一次二分查找有影响,因此应该为:
P(x0 in mp | 前K次连续同符号分类) =P(x0 in pq | 前K次连续同符号分类)
概率推导
经典的投币问题中,一个硬币连续出现n次,都是某一指定的面,那么这种情况出现的概率为(1/2)^n。
我们根据古典概率进行类推,前K次均为某一指定侧时,这种情况出现的概率为:
P(前K次均为某一指定侧) = (1/2)^K
为满足P(x0 in mp | 前K次连续同符号分类) = P(x0 in pq | 前K次连续同符号分类),不妨设前K次连续同符号分类均为“左”,因此x0 应满足:
P(x0 in mp | 前K次连续同符号分类) = [1 - (1/2)^K] * mp = 0.5
P(x0 in pq | 前K次连续同符号分类) = (1/2)^K * pq = 0.5
简化取代方法
令 α = 本次分类前,连续同符号的分类方式次数
当α = 1时,即下一次分类并没有偏向,仍然采用等分的方式;
当α = 2时,我们将区间段划分为三等分段,选取α偏向的那一侧的等分点作为下一次二分点;
如下类似进行。