本描述了“RSDS”或“DS”类型的pdb(程序数据库)文件的格式,这些文件是由Miscrosoft的link.exe从版本7及更高版本发出的。
什么是PDB文件?
如果选择了/DEBUG选项或/DEBUG:FULL选项,则最新的Microsoft链接器将在链接时创建程序数据库(pdb)文件。pdb文件包含有关创建可执行文件的信息,还包含最新CodeView格式的符号信息。可执行文件包含本地计算机上pdb文件的路径和文件名,以及标识码,以便可以找到正确的pdb文件。pdb文件本身的格式和最新的CodeView格式都没有文档记录。据我所知,格式已经改变了两次,而且很可能会再次改变。Microsoft提供API来分析和报告其Debug Information Access(DIA)SDK中pdb文件的内容。
可执行文件中的PDB文件信息
如果“CODEVIEW”调试目录不包含pdb文件信息,则其格式如下:-
+0h dword "RSDS" signature +4h GUID 16-byte Globally Unique Identifier +14h dword "age" +18h byte string zero terminated UTF8 path and file name
这里RSDS签名标识格式。全局唯一标识符是特定于计算机的唯一值。它在这里被写入可执行文件和pdb文件中,以便将两者标识为匹配。“age”是一个值,每当链接器重新生成可执行文件及其关联的pdb文件时,该值都会递增。
查看“CODEVIEW”调试目录
最简单的方法之一是使用一个能够可视化显示可执行文件内容的工具。其中一个这样的工具是韦恩·J·拉德伯恩的PEview。
使用此工具,打开可执行文件并打开左窗格上的“IMAGE_NT_HEADERS”标题。单击IMAGE_OPTIONAL_HEADER并向下滚动,直到到达调试目录条目。这将给出您感兴趣的信息的RVA(相对虚拟地址)。确保工具栏切换到RVA值,以便您可以继续(RVA是一个地址,如果可执行文件加载到内存中准备运行,则会应用该地址)。您正在可执行文件中查找DEBUG目录,它很可能会隐藏在其中一个部分的数据中。最有可能是“rdata”部分。单击左侧窗格中的那个,并检查DEBUG目录是否现在出现。如果没有,请尝试其他部分,以查找IMAGE_OPTIONAL_HEADER中给定的RVA。调试目录包含指向调试信息的指针。如果文件中有一个“CODEVIEW”调试目录,它将出现在调试目录中,并且也将出现在PEview的左窗格中。单击左窗格中的此项可查看其内容。
下面是“CODEVIEW”调试目录内容的典型示例:-
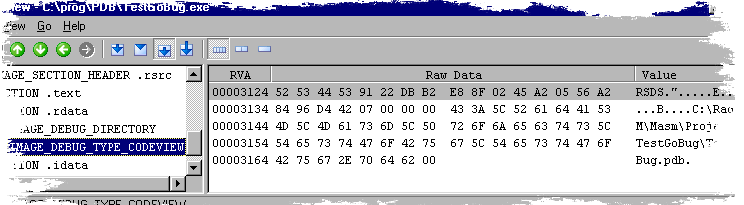
这里的GUID是“B2DB2291-8FE8-4502-A20556A28496D442”“age”是7岁。接下来是pdb文件的路径和文件名。注意,这应该是UTF-8格式,这意味着可以使用非罗马字符的文件名。
查看PDB文件
由于PDB格式不断变化,您不能期望可视化工具跟上变化,最好使用十六进制编辑器(如Paws)查看文件,或转储到文件或使用十六进制文件转储程序(如Borland的tdump)打印文件。
PDB文件的性质
正如Sven B.Schreiber所做的那样,pdb文件格式与磁盘文件系统所使用的格式类似。磁盘文件系统将被划分为固定大小的称为“扇区”的数据块。文件中的数据包含在文件写入磁盘时标识为备用的扇区中,但它们在磁盘上不一定是连续的。文件目录跟踪数据在磁盘上的位置。在pdb文件中,可能更适合将数据块称为“页面”,将文件中的数据称为“流”,将文件目录称为“流目录”。
PDB文件头
pdb文件顶部是此转储中显示的头:-
Turbo Dump Version 4.2.16.1 Copyright (c) 1988, 1996 Borland International
Display of File TESTGOBUG.PDB
000000: 4D 69 63 72 6F 73 6F 66 74 20 43 2F 43 2B 2B 20 Microsoft C/C++
000010: 4D 53 46 20 37 2E 30 30 0D 0A 1A 44 53 00 00 00 MSF 7.00...DS...
000020: 00 04 00 00 02 00 00 00 E3 00 00 00 B4 04 00 00 ................
000030: 00 00 00 00 E1 00 00 00 00 00 00 00 00 00 00 00 ................
000040: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
这里要查找的字符是1Ah,它(用ascii术语)是一个“文件结束”字符。在这种情况下(巧合地)出现在文件中的偏移+1AH中,并标记字符串“微软C/C++ +MSF 7”的结尾。应该注意的是,这个字符串的长度在不同的pdb版本之间是不同的。文件结束字符紧接着是签名,在本例中是“DS”,然后是空终止符,然后是足够的填充,将头带到下一个dword,在本例中是+20h。
在+20h,我们找到了dword值400h,这是每个数据块的大小,我们可以称之为“页面大小”。换句话说,pdb文件被分成400h字节(十进制为1024字节)的块。
在+24h是2h。我还不确定这代表什么。
在+28h处有值0E3h。这表示整个文件中有多少页。如果乘以400h的页面大小,则生成38C00h或232448,这是pdb文件的字节大小。
在+2Ch处有值4B4h(十进制1204)。这是流目录的总大小(字节)。因为每个页面是1024字节,我们现在知道流目录覆盖一个完整的页面加上180字节。这一点很重要,因为流目录在文件中也不一定是连续的。
在+30h,值为零。我还没有发现这代表什么。
+34h是值0E1h。这是指向流目录指针的指针。乘以400h的页面大小,值0E1h变为38400h。因此在38400h时,我们希望在文件中找到流目录指针。
在PDB文件中的流目录指针
下面是文件在38400h的转储,其中包含流目录指针:-
038400: DF 00 00 00 E0 00 00 00 00 00 00 00 00 00 00 00 ................ 038410: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ 038420: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
流目录指针的结构非常简单。从pdb头我们知道流目录在两个页面中,所以我们希望有两个指针。我们可以看到指针是0DFh和0E0h。需要指针,因为流目录在文件中不一定是连续的。为了得到正确的地址,每个指针都需要乘以400h的页面大小,这样我们就可以看到流目录的第一页是0DFh*400h=37000h,然后继续是0E0h*400h=38000h。
PDB文件流目录
流目录是以下形式的结构:-
+0h数据流数
+4h每个流的dword,给出流的字节大小
0=无流
-1=无流
+?指向流的指针的数组
这是在文件3700h处的转储:-
037C00: 15 00 00 00 48 03 00 00 59 00 00 00 98 F2 02 00 ....H...Y....... 037C10: D7 07 00 00 00 00 00 00 D0 0A 00 00 6C 03 00 00 ............l... 037C20: 18 11 00 00 AA 14 00 00 FF FF FF FF 19 00 00 00 ................ 037C30: 70 00 00 00 B4 05 00 00 68 01 00 00 1C 00 00 00 p.......h....... 037C40: FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF ................ 037C50: FF FF FF FF C8 00 00 00 D9 00 00 00 DE 00 00 00 ................ 037C60: DC 00 00 00 18 00 00 00 19 00 00 00 1A 00 00 00 ................ 037C70: 1B 00 00 00 1C 00 00 00 1D 00 00 00 1E 00 00 00 ................ 037C80: 1F 00 00 00 20 00 00 00 21 00 00 00 22 00 00 00 .... ...!..."... 037C90: 23 00 00 00 24 00 00 00 25 00 00 00 26 00 00 00 #...$...%...&... 037CA0: 27 00 00 00 28 00 00 00 29 00 00 00 2A 00 00 00 '...(...)...*... 037CB0: 2B 00 00 00 2C 00 00 00 2D 00 00 00 2E 00 00 00 +...,...-....... 037CC0: 2F 00 00 00 30 00 00 00 31 00 00 00 32 00 00 00 /...0...1...2... 037CD0: 33 00 00 00 34 00 00 00 35 00 00 00 36 00 00 00 3...4...5...6... 037CE0: 37 00 00 00 38 00 00 00 39 00 00 00 3A 00 00 00 7...8...9...:...
第一个dword包含值15h。这表示文件中有21个数据流。这也意味着有21个dword跟随(给出流大小)。因此,页面指针从+58h开始,即文件中的37C58h。流大小指示每个流有多少页指针。这与用于指示流目录本身有多少指针的系统相同。
例如,我们可以看到流1的长度是348h字节。这可以安装到一个页面中,因此我们只希望找到指向流1的一个指针。该指针(37C58h)为0D9h,乘以400h的页面大小即为36400h。流2的长度为59h字节,其指针为0DEh*400h=37800h。流3的长度为2F298h字节(十进制193176)。因此,它有189页,从37C5Ch开始有189个指针,第一页是0DEh(37800h),第二页是0DCh(37000h),第三页是18h(6000h),以此类推。有些流大小不是0就是-1,这些可以忽略。这些流根本就没有页面指针。
The streams
我并没有非常努力地去识别这些流的内容,因为找到感兴趣的主要内容(符号)相当容易。与“JG”类型的pdb文件一样,符号流是第八流或第九流。流1到流4似乎总是包含相同类型的信息。在流4以上,流的内容趋于变化。有时流完全丢失或添加了其他流。到目前为止,我还没有找到指示流包含什么内容的索引。到目前为止,我确定的是:-
- 流1—(可能)上一个流目录。
- 流2-pdb文件真实性。
- 流3-来自对象文件中.debug$S和.debug$T节的材料。这可能非常庞大,因为它将包含许多未使用的材料,例如源脚本中引用的include文件中的结构和结构成员。
- 流4-生成过程中使用的文件。
- 流8或流9-符号。
- 在流8之上,您将发现节数据、其他调试符号、链接器自身文件信息和链接的导入信息。
流2-pdb文件真实性
这些字段很重要,因为它允许进行检查以确保pdb文件与相关的可执行文件
037800: 94 2E 31 01 25 55 1A 40 07 00 00 00 91 22 DB B2 ..1.%U.@....."..
037810: E8 8F 02 45 A2 05 56 A2 84 96 D4 42 11 00 00 00 ...E..V....B....
037820: 2F 4C 69 6E 6B 49 6E 66 6F 00 2F 6E 61 6D 65 73 /LinkInfo./names
037830: 00 02 00 00 00 04 00 00 00 01 00 00 00 06 00 00 ................
037840: 00 00 00 00 00 0A 00 00 00 0A 00 00 00 00 00 00 ................
037850: 00 04 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
如果您将其与我们在可执行文件中看到的“CODEVIEW”调试目录中的“age”和GUID进行比较,您可以看到完全匹配。这里的age是+8h,GUID是+Ch。这里还有一个时间日期是+4h,但这不一定与可执行文件中的时间匹配。
符号流
在“DS”文件中,每个符号都采用以下结构,与以前的“JG”文件中的结构类似,只是符号类型号已更改,包含符号名的字符串不再以大小字节开头(即不再是pascal字符串):-
In "DS" files each symbol is in the following structure which is similar to that found in the earlier "JG" files, except that the symbol type numbers have changed and the string containing the symbol name is no longer preceded by a size byte (ie. it's no longer a pascal string):-
+0h word - size of structure not including this word but
including the padding after the string
+2h word - type of symbol. So far the following are known:-
1108h = data type (from h or inc file)
110Ch = symbol marked as "static" in the object file
110Eh = global data variables, function names, imported functions
local variables
1125h = function prototype
+4h dword - reserved
+8h dword - offset value
+0Ch word - section number
+0Eh bytes - null terminated string containing symbol name
+?h bytes - padding to next dword