从用户使用体验的角度来看,200ms是第一个分界点:接口的响应时间在200ms之内,用户是感觉不到延迟的,就像是瞬时发生的一样。而1s是另外一个分界点:接口的响应时间在1s之内时,虽然用户可以感受到一些延迟,但却是可以接受的,超过1s之后用户就会有明显等待的感觉,等待时间越长,用户的使用体验就越差。所以,健康系统的99分位值的响应时间通常需要控制在200ms之内,而不超过1s的请求占比要在99.99%以上。
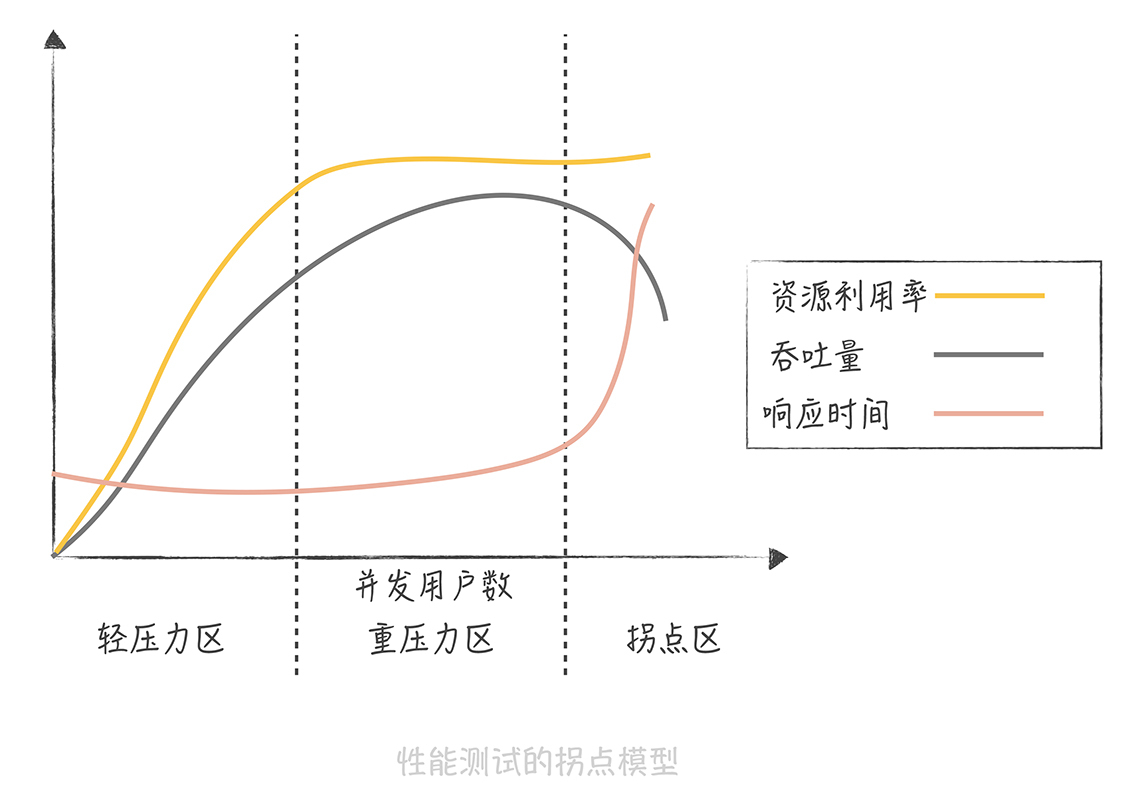
从图中你可以发现,并发用户数处于轻压力区时,响应时间平稳,吞吐量和并发用户数线性相关。而当并发用户数处于重压力区时,系统资源利用率到达极限,吞吐量开始有下降的趋势,响应时间也会略有上升。这个时候,再对系统增加压力,系统就进入拐点区,处于超负荷状态,吞吐量下降,响应时间大幅度上升。
所以我们在评估系统性能时通常需要做压力测试,目的就是找到系统的“拐点”,从而知道系统的承载能力,也便于找到系统的瓶颈,持续优化系统性能。
1.业务价值->承载高并发->性能优化。一切的前提是业务价值需要。如果没有足够的价值,那么可读性才是第一,性能在需要的地方是no.1,但不需要的地方可能就是倒数第一稞。当下技术框架出来的软件差不到哪去,没有这种及时响应诉求的地方,削峰下慢慢跑就是了。(工作需要,常在缺少价值的地方着手性能优化,让我对这种就为个数字的操作很反感。要知道,异步,并发编程,逻辑缓存,算法真的会加剧系统的复杂度,得不偿失。如果没那个价值,简单才是王道)
2.提高并发度。要么加硬件,要么降低服务响应时间。做为开发,我们的目光更聚焦在降低响应时间这块。
1.采用非阻塞的rpc调用(高效的远端请求模式,采用容器的覆盖网络我认为也算)
2.将计算密集和io密集的的逻辑分割开,单独线程池,调整线程比例压榨单机性能(或者说找拐点)。
3.做缓存,io耗时的缓存和计算耗时的缓存(多级缓存,数据压缩降低带宽)。
4.采用享元模式,用好对象池和本地线程空间,尽量减少对象创建与销毁的开销,提高复用。
5.业务拆分,像状态变化后的外部系统通知,业务监控,es或solr等副本数据同步等操作,无需在主流程中做的事都拆掉。走canal监听表数据变化,推mq保最终一致的方式从业务项目完全解偶出来。
6.fork_join,分而治之的处理大任务。并发编程,采用多线程并行的方式处理业务。(规避伪共享,减小锁力度,采用合适的锁)。
7.数据库配置优化,查询优化。(存储优化比较头疼,毕竟不按业务拆单点跑不掉,单点性能就要命。基本只能内存库先行,后台同步数据做持久。然后内存库多副本,自修复,保留一系列自修复失败的修复手段)
高并发:高性能(响应时间)、高可用(down机、故障、维护)、可扩展(应急扩容)
响应时间(平均值、最大值、分位值),响应为1s,吞吐量为每秒1次,响应缩短到10ms,吞吐量上升到每秒100次,从用户体验来说:200ms分界点,1s为另一个分界点,健康系统的99分位值的响应时间控制在200ms以内,不超过1s的请求占比要超过99.99%
高并发下的性能优化手段:
1.提高系统的处理核心数(吞吐量=核心数(并发进程数)/响应时间(s))
但并非无限增加核心数就可以增加吞吐量,随着进程数增加,并行的任务对于资源的争夺也增加,在某
个临界点,进程增加导致系统的性能下降,这就是性能测试中的拐点模型,所以在评估系统性能时,需要做压力测试,找到拐点
2.减少单次任务响应时间
cpu密集型:优化算法
io密集型:1.采用工具,linux的工具集
2.通过监控,对任务的每一个步骤做分时统计,从而找到任务中哪一步小号消耗了更多的时间
//-----------------
高可用性(High Availability,HA)是你在系统设计时经常会听到的一个名词,它指的是系统具备较高的无故障运行的能力。
//-------------------------
高可用性:
MTBF(Mean Time Between Failure)平均故障间隔时间越大越好
MTTR(Mean Time To Repair)故障平均恢复时间越小越好
1.系统设计(备用节点顶替故障的服务,丢卒保车)
failover故障转移
超时控制
降级(牺牲非核心服务)
限流(限制每秒请求次数,例如限制在每秒1000次以内,多的请求给用户返回错误提示)
2.系统运维
灰度发布 系统的变更按照一定比例逐步推进上线,如果运行一段时间系统指标平稳且没有大量错误日志出现,则推动全量变更
故障演练 在线上系统上随机关闭节点模拟故障,若你的系统不能够抵御一些异常情况的话,建议在线下部署一套和线上一样的系统进行故障演练
同时要注意不要过度优化,以实际业务需要为准
//-------------------
05系统设计目标(三)如何让系统易于扩展
所以说,数据库、缓存、依赖的第三方、负载均衡、交换机带宽等等都是系统扩展时需要考虑的因素。我们要知道系统并发到了某一个量级之后,哪一个因素会成为我们的瓶颈点,从而针对性地进行扩展。
//-------------------
主从复制问题:主从复制存在延迟,但是有时候需要时时读取当前数据
解决方案:第一种方案是数据的冗余(发送数据的时候带上加入的数据)第二种方案是使用缓存最后一种方案是查询主库
分库分表问题:分区键的问题、分表后ID的全局唯一性
基于snowflake算法搭建发号器
为什么不用uuid:
1、生成的ID做好具有单调递增性,也就是有序的,而UUID不具备这个特点。为什么ID要是有序的呢?因为在系统设计时,ID有可能成为排序的字段/
2、另一个原因在于ID有序也会提升数据的写入性能。
3、UUID不能作为ID的另一个原因是它不具备业务含义。实现实世界中使用的ID中都包含有一些有意义的数据,这些数据会出现在ID的固定的位置上。比如说我们使用的身份证的前六位是地区编号;
4、UUID是由32个16进制数字组成的字符串,如果作为数据库主键使用比较耗费空间。
Snowflake的核心思想是将64bit的二级制数字分成若干部分,每一部分都存储有特定含义的数据,比如说时间戳、机器ID、序列号等等,最终生成全局唯一的有序ID。它的标准算法是这样的:

从上面这张图中我们可以看到,41位的时间戳大概可以支撑pow(2,41)/1000/60/60/24/365年,约等于69年,对于一个系统是足够了。
snowflake算法工程话
一种是嵌入到业务代码里,也就是分布在业务服务器中。这种方案的好处是业务代码在使用的时候不需要跨网络调用,性能上会好一些,但是就需要更多的机器ID位数来支持更多的业务服务器。另外,由于业务服务器的数量很多,我们很难保证机器ID的唯一性,所以就需要引入ZooKeeper等分布式一致性组件来保证每次机器重启时都能获得唯一的机器ID。
另外一个部署方式是作为独立的服务部署,这也就是我们常说的发号器服务。业务在使用发号器的时候就需要多一次的网络调用,但是内网的调用对于性能的损耗有限,却可以减少机器ID的位数,如果发号器以主备方式部署,同时运行的只有一个发号器,那么机器ID可以省略,这样可以留更多的位数给最后的自增信息位。即使需要机器ID,因为发号器部署实例数有限,那么就可以把机器ID写在发号器的配置文件里,这样即可以保证机器ID唯一性,也无需引入第三方组件了。微博和美图都是使用独立服务的方式来部署发号器的,性能上单实例单CPU可以达到两万每秒。
存在问题:
1、依赖于系统的时间戳,一旦系统时间不准,就有可能生成重复的ID。
2、如果请求发号器的QPS不高,比如说发号器每毫秒只发一个ID,就会造成生成ID的末位永远是1,那么在分库分表时如果使用ID作为分区键就会造成库表分配的不均匀。
(1).时间戳不记录毫秒而是记录秒,这样在一个时间区间里可以多发出几个号,避免出现分库分表时数据分配不均。
(2).生成的序列号的起始号可以做一下随机,这一秒是21,下一秒是30,这样就会尽量的均衡了。
//---------------------
在NoSQL数据库刚刚被应用时,它被认为是可以替代关系型数据库的银弹,在我看来,也许因为以下几个方面的原因:
- 弥补了传统数据库在性能方面的不足;
- 数据库变更方便,不需要更改原先的数据结构;
- 适合互联网项目常见的大数据量的场景;
不过,这种看法是个误区,因为慢慢地我们发现在业务开发的场景下还是需要利用SQL语句的强大的查询功能以及传统数据库事务和灵活的索引等功能,NoSQL只能作为一些场景的补充。