http://bilibili.com/video/BV184411Q7Ng?p=9




Python程序举例:
""" 对数据进行归一化处理 """ from sklearn.preprocessing import MinMaxScaler def mMinMaxScaler(): """ 对数据进行归一化处理 :return: """ mMinMaxScaler=MinMaxScaler() data=mMinMaxScaler.fit_transform([[90,2,10,40],[60,4,15,45],[75,3,13,46],]) print(data) return None if __name__=="__main__": mMinMaxScaler()
运行结果:
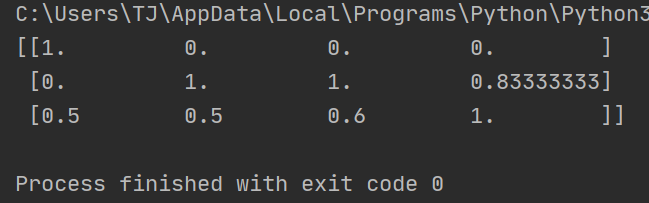
C:UsersTJAppDataLocalProgramsPythonPython37python.exe D:/qcc/python/mnist/data_guiyihua.py
[[1. 0. 0. 0. ]
[0. 1. 1. 0.83333333]
[0.5 0.5 0.6 1. ]]
Process finished with exit code 0
注解:
- 对于每一列特征都要处理。
""" 对数据进行归一化处理 """ from sklearn.preprocessing import MinMaxScaler def mMinMaxScaler(): """ 对数据进行归一化处理 :return: """ mMinMaxScaler=MinMaxScaler(feature_range=(2,3)) data=mMinMaxScaler.fit_transform([[90,2,10,40],[60,4,15,45],[75,3,13,46],]) print(data) return None if __name__=="__main__": mMinMaxScaler()
运行结果:
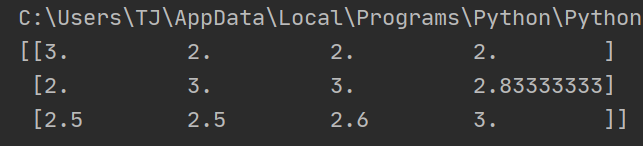
注解:
- 归一化到一个指定的区间。
- 默认是归一化到[0, 1]的。
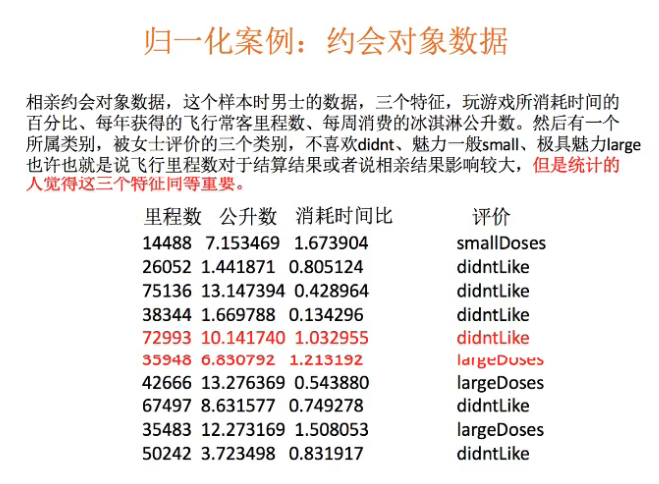
注解:
- 飞行里程数多的话,可能这个人是个商务人士,但同时陪伴家人的时间可能很少。
- 觉得3个特征同等重要的时候,就要对数据进行归一化处理。
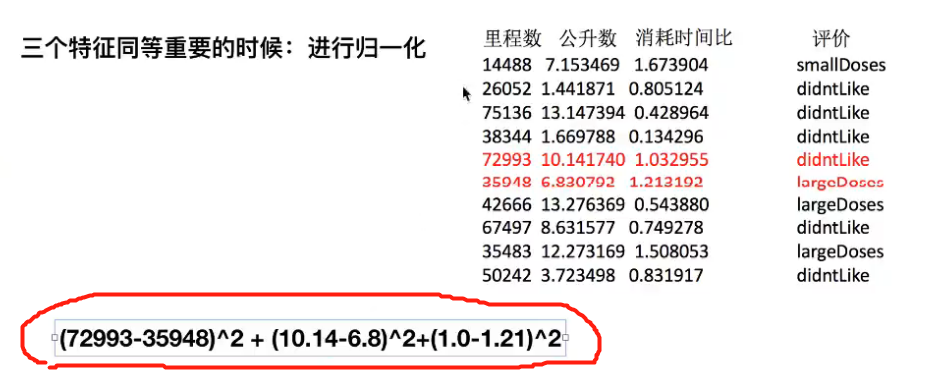
注解:
- 如果不进行归一化,小值将淹没在大值中,小值的参考作用将失去。


注解:
- 在做归一化的时候,如果有异常点,会怎样?
- 归一化对异常点无法抵抗,会造成数据归一化错误。

""" 对数据进行归一化处理 """ from sklearn.preprocessing import MinMaxScaler def mMinMaxScaler(): """ 对数据进行归一化处理 :return: """ mMinMaxScaler=MinMaxScaler(feature_range=(0,1)) data=mMinMaxScaler.fit_transform([[90,2,10,40],[60,4,15,45],[75,3,13,46],]) print(data) return None if __name__=="__main__": mMinMaxScaler()
无异常数据的归一化结果:
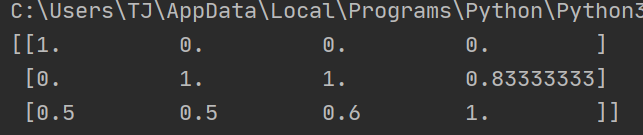
""" 对数据进行归一化处理 """ from sklearn.preprocessing import MinMaxScaler def mMinMaxScaler(): """ 对数据进行归一化处理 :return: """ mMinMaxScaler=MinMaxScaler(feature_range=(0,1)) data=mMinMaxScaler.fit_transform([[90,2,10,1040],[60,4,15,45],[75,3,13,46],]) print(data) return None if __name__=="__main__": mMinMaxScaler()
有异常数据之后的归一化结果:
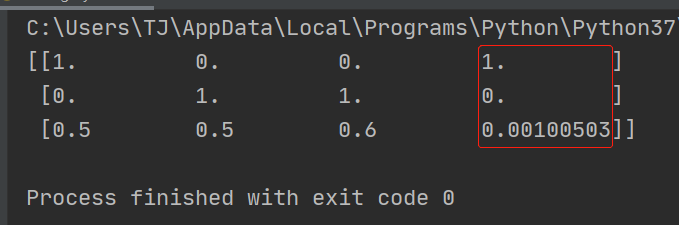
解决办法:标准化。





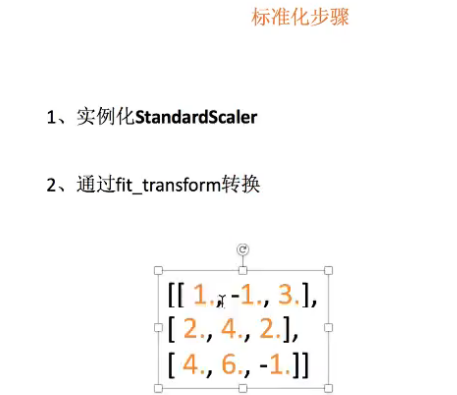
数据标准化示例代码:
""" 对数据进行标准化处理 """ from sklearn.preprocessing import MinMaxScaler, StandardScaler def stdardScaler(): """ 对数据进行标准化处理,即处理成均值为0,标准差为1的数据 :return: """ std=StandardScaler() data=std.fit_transform([[1.,-1.,3.],[2.,4.,2.],[4.,6.,-1.]]) print(data) return None if __name__=="__main__": stdardScaler()
运行结果:
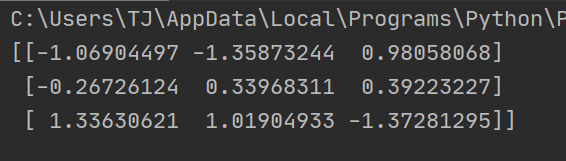
注解:
- 可以看到,没一列的平均值都是0.
- 相对于对数据进行归一化,对数据进行标准化的好处是不容易受到异常点的影响。

注解:
- 并不是所有数据都要进行归一化、标准化的。