转自
http://www.ssdfans.com/blog/2017/08/03/蛋蛋读nvme之一/
http://www.ssdfans.com/blog/2017/08/03/蛋蛋读nvme之二/
http://www.ssdfans.com/blog/2017/08/03/蛋蛋读nvme之三/
蛋蛋读NVMe之一
没有前戏,直接进入。蛋蛋就是这么个人。
NVMe是一种Host与SSD之间通讯的协议,它在协议栈中隶属高层。
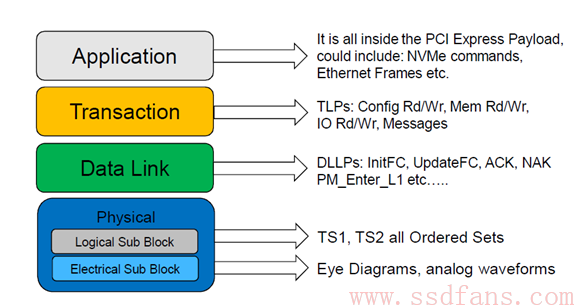
NVMe在协议栈中处于应用层或者命令层,它是指挥官,军师,在三国的话,就是诸葛亮的角色。”运筹帷幄之中,决胜千里之外”。军师设计好计谋,就交由手下五虎大将去执行。NVMe的手下大将就是PCIe,它所制定的任何命令,都交由虎将PCIe去完成。虽然NVMe的命令可能可以由别的接口协议完成,但NVMe与PCIe合作形成的战斗力无疑是最强的。
NVMe是为SSD所生的。NVMe出现之前,SSD绝大多数走的是AHCI和SATA的协议,后者其实是为传统HDD服务的。与HDD相比,SSD具有更低的延时和更高的性能,AHCI已经不能跟上SSD性能发展的步伐了,已经成为制约SSD性能的瓶颈。所有SATA接口的SSD,你去看性能参数,会发现都不会超过600MB/s。如果碰到有人跟你说它的SATA SSD读取性能可以超过600MB/s,直接拨打110报警。不是底层Flash带宽不够,是SATA接口速度限制了,因为SATA现在最高带宽就是600MB/s。OK,既然SATA接口速度太慢,我用PCIe好了,不过上层协议还是AHCI。五虎上将有了,由刘备指挥,让人不禁感叹暴殄天物呀。刘备什么水平,诸葛亮出现之前,居无定所,一会跟着曹操混,一会又跟着吕布混,谁肯收留就跟谁混。惨呀!AHCI和刘备一个德行,只有一个命令队列,最多同时只能发32条命令,HDD时代(群雄逐鹿)还能混混,SSD时代(三足鼎立)就只有被灭的份。刘备需要三顾茅庐,需要诸葛亮的辅佐。同样,SSD需要PCIe,更需要NVMe。
在这样的背景下,Intel等巨头携天子以令诸侯,集大家智慧,制定出了NVMe规范,目的就是释放SSD性能潜力,解SSD倒悬之苦。

上面只列了几个巨头,参与的公司远不止这些。没有上榜的公司不要见怪。
NVMe制定了Host与SSD之间通讯的命令,以及命令如何执行的。
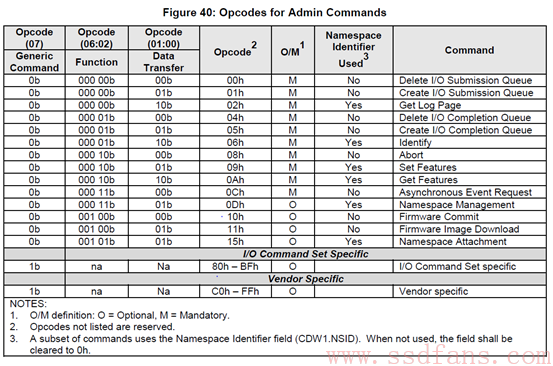
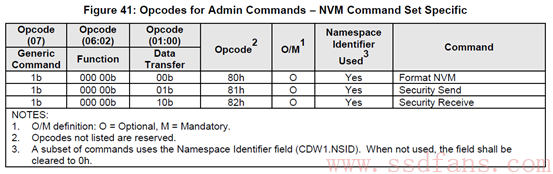
NVMe有两种命令,一种叫Admin Command,用以Host管理和控制SSD;另外一种就是I/O Command,用以Host和SSD之间数据的传输。下面是NVMe1.2支持的命令列表:
NVMe支持的Admin Command:
NVMe支持的I/O Command:
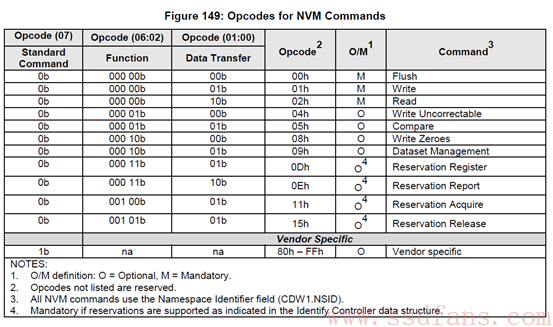
跟ATA spec中定义的命令相比,NVMe的命令个数少了很多,完全是为SSD量身定制的。大家现在别纠结于具体的命令,了解一下就好。老板交代干活的时候,再找spec一个一个看吧。
命令有了,那么,Host又是怎么把这些命令发送给SSD执行呢?
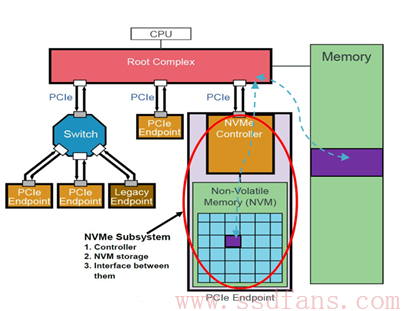
NVMe有三宝:Submission Queue (SQ),Completion Queue(CQ)和Doorbell Register (DB)。 SQ和CQ位于Host的内存中,DB则位于SSD的控制器内部。上图:
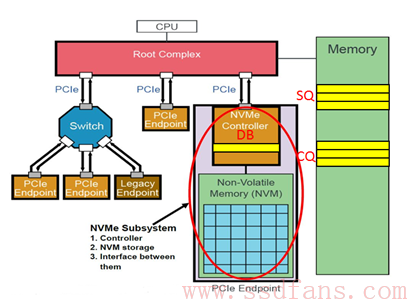
这张图信息量比较大,除了让我们知道SQ和CQ在Host的memory中以及DB在SSD端外,而且让我们对一个PCIe系统有一个具体的认识。上图中的NVMe Subsystem一般就是SSD。请看这张图几秒钟,然后闭上眼,脑补SSD所处的位置:SSD作为一个PCIe Endpoint通过PCIe连着Root Complex (RC), 然后RC连接着CPU和内存。RC是什么?我们可以认为RC就是CPU的代言人,助理,或者小蜜。作为系统中最高层,CPU说:我很忙的,你SSD有什么事情先跟我小蜜说!尽管如此,SSD的地位还是较过去提升了一级,过去SSD别说直接接触霸道总裁,就是连小蜜的面都见不到,SSD和小蜜之间还隔着一座南桥呢。滚蛋吧,南桥君!
扯远了,刚才要说什么来着。对了,是三宝。SQ位于Host内存中,Host要发送命令时,先把准备好的命令放在SQ中,然后通知SSD来取;CQ也是位于Host内存中,一个命令执行完成,成功或失败,SSD总会往CQ中写入命令完成状态。DB(大宝?)又是干什么用的呢?Host发送命令时,不是直接往SSD中发送命令的,而是把命令准备好放在自己的内存中,那怎么通知SSD来获取命令执行呢?Host就是通过写SSD端的大宝寄存器来告知SSD的:饭已OK了,下来密西吧!
OK,具体的我们来看看NVMe是如何处理命令的,看图说话:
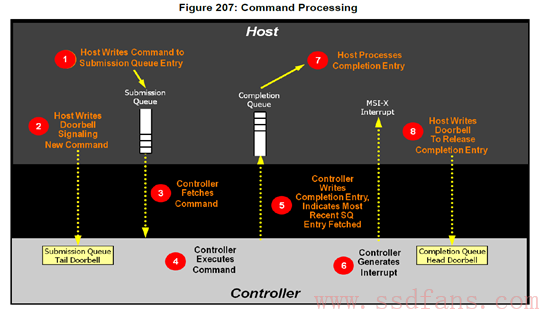
这是NVMe1.2规范中的第207张图。不知道是人家图画得好呢,还是NVMe就是这么简单,抑或是我比较聪明,反正上面的命令处理流程我一看就明白了。好吧,给没我聪明的人再解释一下。
说,把大象放冰箱一共要几步?答:三步。
第一步,打开冰箱门;
第二步,放进大象;
第三步,关上冰箱门。
说,NVMe处理命令需要几步?答:八步:
第一步:Host写命令到SQ;
第二步:Host写DB,通知SSD取指;
第三步:SSD收到通知,于是从SQ中取指;
第四步:SSD执行指令;
第五步:指令执行完成,SSD往CQ中写指令执行结果;
第六步:然后SSD发短信通知Host指令完成;
第七步:收到短信,Host处理CQ,查看指令完成状态;
第八步:Host处理完CQ中的指令执行结果,通过DB回复SSD:指令执行结果已处理,辛苦您了!
曹植七步作诗,NVMe就比曹植差一点,需要八步。
关于NVMe,到现在相信大家有了一些基本认识。关于更多技术细节,今天我不打算讲了。我要吸取之前的教训,比如在一篇文章里就把SSD基本原理介绍了,而不是分别介绍。这样很不讨巧,一口气写完,对自己写文章是压力,对读者读文章也是压力,对网站的浏览量也不好。阿呆的做法值得学习,一个话题,采用连载的方式推出,有朋友也这么向我建议,于是我决定采取类似方式来谈NVMe,毕竟NVMe是个大话题。于是,我把标题从”蛋蛋读NVMe”改成”蛋蛋读NVMe之一”,后面还有之二,之三。。。接下来《蛋蛋读NVMe之二》我会详细解读NVMe的三宝 (SQ,CQ,DB),敬请期待。
蛋蛋读NVMe之二
上回书说道,NVMe有三宝:SQ,CQ和DB。接下来我们就详细的看看这吉祥三宝。
Host往SQ中写入命令, SSD往CQ中写入命令完成结果。SQ与CQ的关系,可以是一对一的关系,也可以是多对一的关系,但不管怎样,他们是成对的:有因就有果,有SQ就必然有CQ。
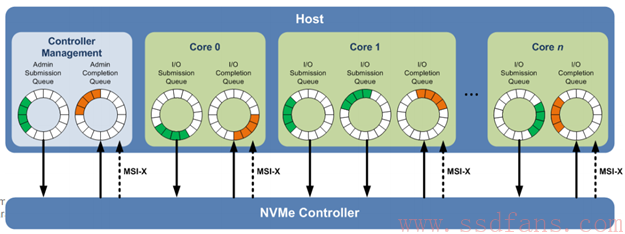
有两种SQ和CQ,一种是Admin,另外一种是I/O,前者放Admin命令,用以Host管理控制SSD,后者放置I/O命令,用以Host与SSD之间传输数据。”你挑着担,我牵着马”(西游记的节奏呀),Admin SQ/CQ 和I/O SQ/CQ各司其职,你不能把Admin命令放到I/O SQ中,同样,你也不能把I/O命令放到Admin SQ里面。如果你不信这个邪,可以不遵守这个规矩试试,看看会发生什么,反正后果自负。
正如上图所示,系统中只有一对Admin SQ/CQ,它们是一一对应的关系;I/O SQ/CQ却可以很多,多达65535(64K减去一个SQ/CQ)。行政人员少,干活的人多,很多公司都是这样的吧,所以Admin SQ/CQ少,I/O SQ/CQ多就不难理解了。Host端每个Core可以有一个或者多个SQ,但只有一个CQ。给每个Core分配一对SQ/CQ好理解,为什么一个Core中还要多个SQ呢?一是性能需求,一个Core中有多线程,可以做到一个线程独享一个SQ;二是QoS需求,什么是QoS?Quality of Service,服务质量。脑补一个场景,蛋蛋一边看小电影,同时迅雷在后台下载小电影,由于电脑配置差,看个小电影都卡。蛋蛋最讨厌看小电影的时候卡顿了,因为你刚刚燃起的激情会被那个缓冲浇灭。所以,蛋蛋不要卡顿!怎么办?NVMe建议,你设置两个SQ,一个赋予高优先级,一个低优先级,把看小电影所需的命令放到高优先级的SQ,迅雷下载所需的命令放到低优先级的SQ,这样,你那破电脑就能把有限的资源优先满足你看小电影了。至于迅雷卡不卡,下载慢不慢,这个时候已经不重要了。能让蛋蛋舒舒服服的看完一个小电影,就是好的QoS。
实际系统中用多少个SQ,取决于系统配置和性能需求,可灵活设置I/O SQ个数。关于系统中I/O SQ的个数,NVMe白皮书给出如下建议:
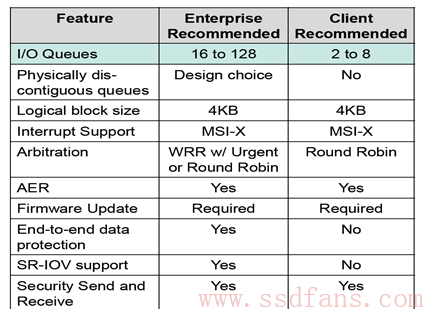
作为队列,每个SQ和CQ都有一定的深度:对Admin SQ/CQ来说,其深度可以是2-4096(4K);对I/O SQ/CQ,深度可以是2-65536(64K)。队列深度也是可以配置的。
SQ/CQ的个数可以配置,每个SQ/CQ的深度又可以配置,因此NVMe的性能是可以通过配置队列个数和队列深度来灵活调节的。NVMe太牛了吧,想胖就胖,想瘦就瘦;想高就高,想矮就矮,整一孙悟空呀!我们已经知道,AHCI只有一个命令队列,且队列深度是固定的32,就凡人一个,和NVMe相比,无论是在命令队列广度还是深度上,都是无法望其项背的;NVMe命令队列的百般变化,更是AHCI无法做到的。说到百般变化,我突然又想到一件残忍的事情:PCIe也是可以的。一个PCIe接口,可以有1,2,4,8,12,16,32条lane!SATA都要哭了,单挑都挑不过你,你还来群殴我。总之AHCI/SATA和NVMe/PCIe 这么一比较,画面太美,蛋蛋不敢看。
蛋蛋在这里总是贬低AHCI/SATA,有人要说蛋蛋忘恩负义,过河拆桥。怎么说?想当年,你SSD刚出来的时候,要不是AHCI/SATA收留了你,辛苦把你养大,都不知道你现在在哪里流浪。现在好了,你SSD翅膀硬了,不说一句感谢的话,倒反过来嫌弃我。各位看官,误会了,前面都是演戏,不说你AHCI/SATA不好,怎么能突出我NVMe/PCIe的好,毕竟后者才是男女一号,这么做完全是剧情需要。戏外,SSD不会忘记你AHCI/SATA的好。忘恩负义?蛋蛋不是那种人。
虽然是在戏里,但总说AHCI/SATA的不好,这样真的好吗?蛋蛋是个怀旧的人,突然就有种蛋蛋的忧伤。好吧,以后就谈NVME,不说AHCI了。孰好孰坏,留与读者评说。
戏还得继续演。
每个SQ放入的是命令条目,无论是Admin还是I/O命令,每个命令条目大小都是64字节;每个CQ放入的是命令完成状态信息条目,每个条目大小是16字节。
在继续谈大宝(DB)之前,先对SQ和CQ做个小结:
-
SQ用以Host发命令,CQ用以SSD回命令完成状态
-
SQ/CQ可以在Host的内存中,也可以在SSD中,但一般在Host 内存中(所有系列文章都是基于SQ/CQ在Host内存中讲的);
-
两种类型的SQ/CQ:Admin和I/O,前者发送Admin命令,后者发送I/O命令;
-
系统中只能有一对Admin SQ/CQ,但可以有很多对I/O SQ/CQ;
-
I/O SQ与CQ可以是一对一的关系,也可以是一对多的关系;
-
I/O SQ是可以赋予不同优先级的;
-
I/O SQ/CQ深度可达64K,Admin SQ/CQ深达4K;
-
I/O SQ/CQ的广度和深度都可以灵活配置;
-
每条命令大小是64字节,每条命令完成状态是16字节;
-
不要过河拆桥。
SQ/CQ中的”Q”,是Queue,队列的意思,无论SQ还是CQ,都是队列,并且是环形队列。队列有几要素,除了队列深度,队列内容,还有两个重要的,就是队列的头(Head)和尾巴(Tail)。大家都排过队,你加入队伍的时候,都是站到队伍的最后,如果你插队,蛋蛋就会鄙视你。队伍最前头的那个,正在被服务或者等待被服务,一旦完成,就离开队伍。队列的头尾很重要,头决定谁会被马上服务,尾巴决定了新来的人站的位置。DB,就是用来记录了一个SQ或者CQ的Head和Tail。每个SQ或者CQ,都有两个对应的DB: Head DB和Tail DB。DB是在SSD端的寄存器,记录SQ和CQ的头和尾巴的位置。

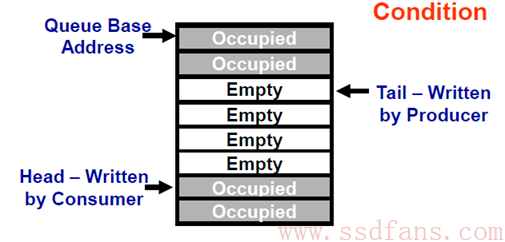
上面是一个队列的生产/消费模型。生产者往队列的Tail写入东西,消费者往队列的Head取出东西。对一个SQ来说,它的生产者是Host,因为它往SQ的Tail位置写入命令,消费者是SSD,因为它往SQ的Head取出指令执行;对一个CQ来说,刚好相反,生产者是SSD,因为它往CQ的Tail写入命令完成信息,消费者则是Host,它从CQ的Head取出命令完成信息。
举个例子,看图说话.
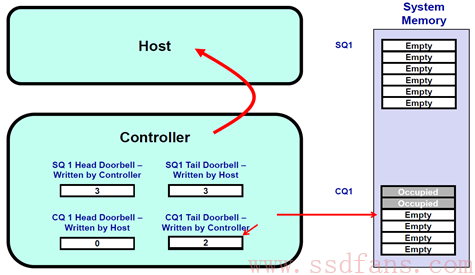
1. 开始假设SQ1和CQ1是空的,Head = Tail = 0.
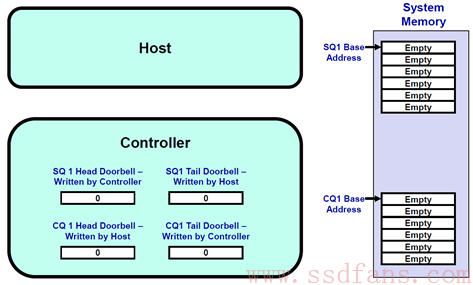
2. 这个时候,Host往SQ1中写入了三个命令,SQ1的Tail则变成3。 Host在往SQ1写入三个命令后,同时漂洋过海去更新SSD Controller端的SQ1 Tail DB寄存器,值为3。Host更新这个寄存器的同时,也是在告诉SSD Controller:有新命令了,需要你去取。
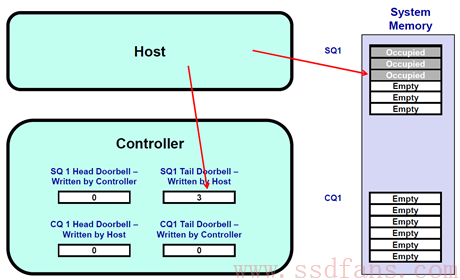
3. SSD Controller收到通知后,于是派人去SQ1把3个命令都取回来执行。SSD把SQ1的三个命令都消费了,SQ1的Head从而也调整为3,SSD Controller会把这个Head值写入到本地的SQ1 Head DB寄存器。
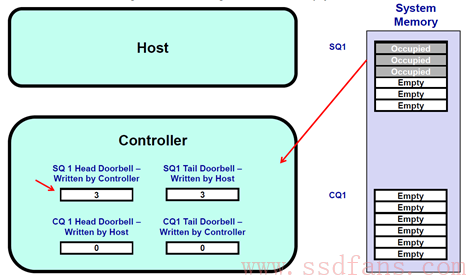
4. SSD执行完了两个命令,于是往CQ1中写入两个命令完成信息,同时更新CQ1对应的Tail DB 寄存器,值为2。SSD并且发消息给Host:有命令完成,请注意查看。
5. Host收到SSD的短信通知,于是从CQ1中取出那两条完成信息处理。处理完毕,Host又漂洋过海的往CQ1 Head DB寄存器中写入CQ1的head,值为2。
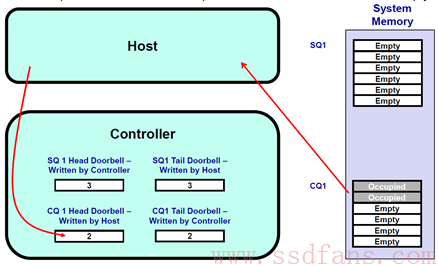
看完这个例子,又重温了一下命令处理流程。之前我们也许只记住了命令处理需要8步(距离曹植一步之遥),看完上面的例子,我们应该对命令处理流程有个更深入具体的认识。
那么,DB在命令处理流程中起了什么作用呢?
首先,如前所示,它记住了SQ和CQ的头和尾。对SQ来说,SSD是消费者,它直接和队列的头打交道,很清楚SQ的头在哪里,所以SQ head DB由SSD自己维护;但它不知道队伍有多长,尾巴在哪,后面还有多少命令等待执行,相反,Host知道,所以SQ Tail DB由Host来更新。SSD结合SQ的头和尾,就知道还有多少命令在SQ中等待执行了。对CQ来说,SSD是生产者,它很清楚CQ的尾巴在哪里,所以CQ Tail DB由自己更新,但是SSD不知道Host处理了多少条命令完成信息,需要Host告知,因此CQ Head DB由Host更新。SSD根据CQ的头和尾,就知道CQ能不能以及能接受多少命令完成信息。
DB的另外一个作用,就是通知作用:Host更新SQ Tail DB的同时,也是在告知SSD有新的命令需要处理;Host更新CQ Head DB的同时,也是在告知SSD,你返回的命令完成状态信息我已经处理,同时表示谢意。
这里有一个对Host不公平的地方,Host对DB只能写,还仅限于写SQ Tail DB和CQ Head DB,不能读取DB。蛋蛋突然想唱首歌:
我俩太不公平
爱和恨全由你操纵
可今天我已离不开你
不管你爱不爱我
Host就是这样痴情。在这个限制下,我们看看Host是怎样维护SQ和CQ的。SQ的尾巴没有问题,Host是生产者,对新命令来说,它清楚自己应该站在队伍哪里。但是Head呢?SSD在取指的时候,是偷偷进行的,Host对此毫不知情。Host发了取指通知后,它并不清楚SSD什么时候去取命令,取了多少命令。怎么破?机智如你,如果是你,你会怎么做?山人自有妙计。给个提示:
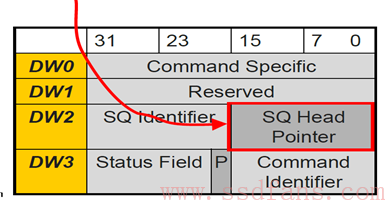
这是什么鬼东西?这是SSD往CQ中写入的命令完成状态信息(16字节)。
是的,SSD往CQ中写入命令状态信息的同时,还把SQ Head DB的信息告知了Host!!这样,Host对SQ中Head和Tail的信息都有了,轻松玩转SQ。
CQ呢?Host知道Head,不知道Tail。那怎么能知道Tail呢?思路很简单,既然你SSD知道,那你告诉我呗!SSD怎么告诉Host呢?还是通过SSD返回命令状态信息中。哈哈,看到上图中的“P”吗?干什么用,做标记用。
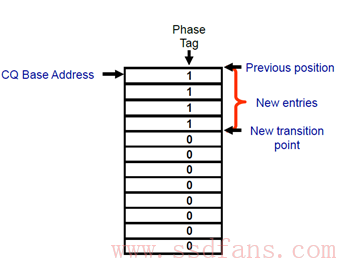
具体是这样的:一开始CQ中每条命令完成条目中的”P” bit初始化为0,SSD在往CQ中写入命令完成条目时,会把”P”写成1。记住一点,CQ是在Host端的内存中,Host可以检查CQ中的所有内容,当然包括”P”了。Host记住上次的Tail,然后往下一个一个检查”P”,就能得出新的Tail了。就是这样。
最后,给大宝做个小结:
-
DB在SSD Controller端,是寄存器
-
DB记录着SQ和CQ的Head和Tail
-
每个SQ或者CQ有两个DB: Head DB 和Tail DB
-
Host只能写DB,不能读DB
-
Host通过SSD往CQ中写入的命令完成状态获取Head或者Tail
蛋蛋读nvme三
相比人的世界,这三个问题在NVMe的世界就很容易得到答案了,至少不会把人逼疯。
我是数据,我从Host来,要到SSD去,或者,我从SSD来,要去到Host。
Host如果想往SSD上写入用户数据,需要告诉SSD写入什么数据,写入多少数据,以及数据源在内存中的什么位置,这些信息包含在Host向SSD发送的Write命令中。每笔用户数据对应着一个叫做LBA(Logical Block Address)的东西,Write命令通过指定LBA来告诉SSD写入的是什么数据。对NVMe/PCIe来说,SSD收到Write命令后,通过PCIe去Host的内存数据所在位置读取数据,然后把这些数据写入到闪存中,同时得到LBA与闪存位置的映射关系。
Host如果想读取SSD上的用户数据,同样需要告诉SSD需要什么数据,需要多少数据,以及数据最后需要放到Host内存的哪个位置上去,这些信息包含在Host向SSD发送的Read命令中。SSD根据LBA,查找映射表,找到对应闪存物理位置,然后读取闪存获得数据。数据从闪存读上来以后,对NVMe/PCIe来说,SSD会通过PCIe把数据写入到Host指定的内存中。这样就完成了Host对SSD的读访问。
在上面的描述中,大家有没有注意到一个问题,那就是Host在与SSD的数据传输过程中,Host是被动的一方,SSD是主动的一方。你Host需要数据,是我SSD主动把数据写入到你的内存中;你Host写数据,同样是我SSD主动去你Host的内存中取数据,然后写入到闪存。SSD跟快递小哥一样辛劳,不仅送货上门,还上门取件。之前蛋蛋还为Host不能读取DB打抱不平,现在看来,Host不值得同情,太懒了。
无论送货上门,还是上门取件,你都需要告诉快递小哥你的地址,不然茫茫人海,快递小哥怎么就能找到你呢?同样的,Host你不亲自传输数据,那总该告诉我SSD去你内存中什么地方取用户数据,或者要把数据写入到你内存中的什么位置。你在告诉快递小哥送货地址或者取件地址时,会说XX路XX号XX弄XX楼XX室,也可能会说XX小区XX楼XX室,anyway,快递小哥能找到就行。Host也有两种方式来告诉SSD数据所在内存位置,一是PRP (Physical Region Page, 不是P2P!),二是SGL (Scatter/Gather List)。不过,后者感觉不怎么友善,因为怎么听起来都像”死过来”(SGL)。当然了,也可能是我误会了,人家只是在说”送过来”。
先说PRP。
NVMe把Host的内存划分为一个一个页(Page),页的大小可以是4KB,8KB,16KB… 128MB。
PRP是什么,长什么样呢?

PRP Entry本质就是一个64位内存物理地址,只不过把这个物理地址分成两部分:页起始地址和页内偏移。最后两bit是0,说明PRP表示的物理地址只能四字节对齐访问。页内偏移可以是0,也可以是个非零的值。
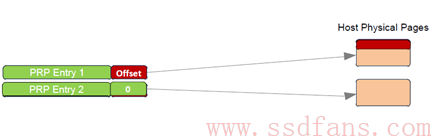
PRP Entry描述的是一段连续的物理内存的起始地址。如果需要描述若干个不连续的物理内存呢?那就需要若干个PRP Entry。把若干个PRP Entry链接起来,就成了PRP List。
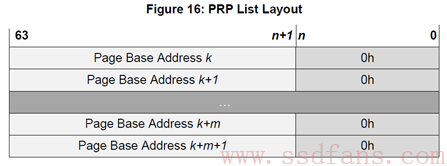
是的,正如你所见,PRP List中的每个PRP Entry的偏移量都必须是0,PRP List中的每个PRP Entry都是描述一个物理页。它们不允许有相同的物理页,不然SSD往同一个物理页写入几次的数据,导致先写入的数据被覆盖。
每个NVMe命令中有两个域:PRP1和PRP2,Host就是通过这两个域告诉SSD数据在内存中的位置或者数据需要写入的地址。

PRP1和PRP2有可能指向数据所在位置,也可能指向PRP List。类似C语言中的指针概念,PRP1和PRP2可能是指针,也可能是指针的指针,还有可能是指针的指针的指针。别管你包的有多严实,根据不同的命令,SSD总能一层一层的剥下包装,找到数据在内存的真正物理地址。SSD善解人衣。
下面是一个PRP1指向PRP List的示例:
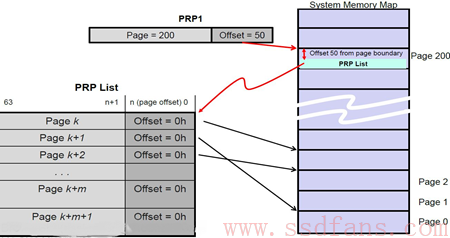
PRP1指向一个PRP List,PRP List位于Page 200,页内偏移50的位置。SSD确定PRP1是个指向PRP List的指针后,就会去Host内存中(Page 200,Offset 50)把PRP List取过来。获得PRP List后,就获得数据的真正物理地址,SSD然后就会往这些物理地址读入或者写入数据。
对Admin命令来说,它只用PRP告诉SSD内存物理地址;对I/O 命令来说,除了用PRP,Host还可以用SGL的方式来告诉SSD数据在内存中写入或者读取的物理地址。
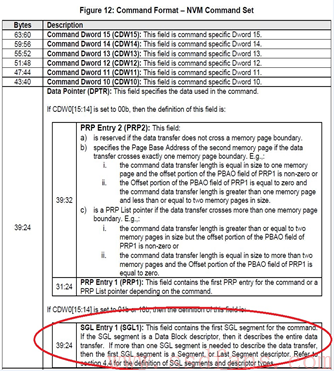
Host在命令中会告诉SSD采用何种方式。具体来说,如果命令当中DW0[15:14]是0,就是PRP的方式,否则就是SGL的方式。
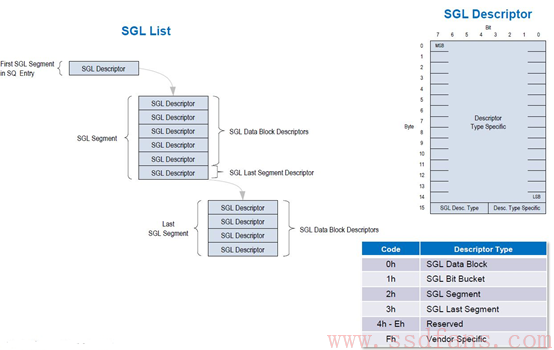
SGL是什么?SGL是一个数据结构,用以描述一段数据空间,这个空间可以是数据源所在的空间,也可以是数据目标空间。SGL(Scatter Gather List)首先是个List,是个链表,由一个或者多个SGL Segment组成,而每个SGL Segment又由一个或者多个SGL Descriptor组成。SGL Descriptor是SGL最基本的单元,它描述了一段连续的物理内存空间:起始地址+空间大小。
每个SGL Descriptor大小是16字节。一块内存空间,可以用来放用户数据,也可以用来放SGL Segment,根据这段空间的不同用途,SGL Descriptor也分几种类型。

有4种SGL Descriptor,一种是Data Block,这个好理解,就是描述的这段空间是用户数据空间;一种是Segment描述符。SGL不是由SGL Segment组成的链表吗?既然是链表,前面一个Segment就需要有个指针指向下一个Segment,这个指针就是SGL Segment描述符,它描述的是它下个Segment所在的空间。特别地,对链表当中倒数第二个Segment,它的SGL Segment描述符我们把它叫做SGL Last Segment描述符。它本质还是SGL Segment描述符,描述的还是SGL Segment所在的空间。为什么需要把倒数第二个SGL Segment描述符单独的定义成一种类型呢?我认为是让SSD在解析SGL的时候,碰到SGL Last Segment描述符,就知道链表快到头了,后面只有一个Segement了。那么,SGL Bit Bucket是什么鬼?它只对Host读有用,用以告诉SSD,你往这个内存写入的东西我是不要的。好吧,你既然不要,我也就不传了。
说了这么多,可能有点晕,结合下张图,可能会更明白点。
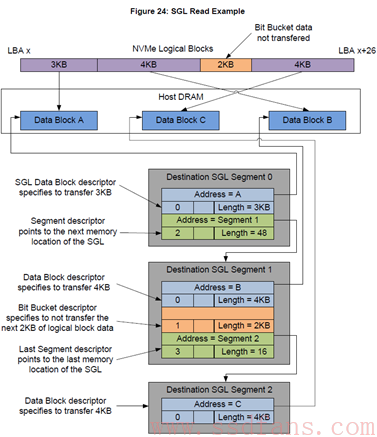
如果还是晕,看个例子吧。
这个例子中,假设Host需要往SSD中读取13KB的数据,其中真正只需要11KB数据,这11KB的数据需要放到3个大小不同的内存中,分别是:3KB,4KB和4KB。
无论是PRP还是SGL,本质都是描述内存中的一段数据空间,这段数据空间在物理上可能连续的,也可能是不连续的。Host在命令中设置好PRP或者SGL,告诉SSD数据源在内存的什么位置,或者从闪存上读取的数据应该放到内存的什么位置。
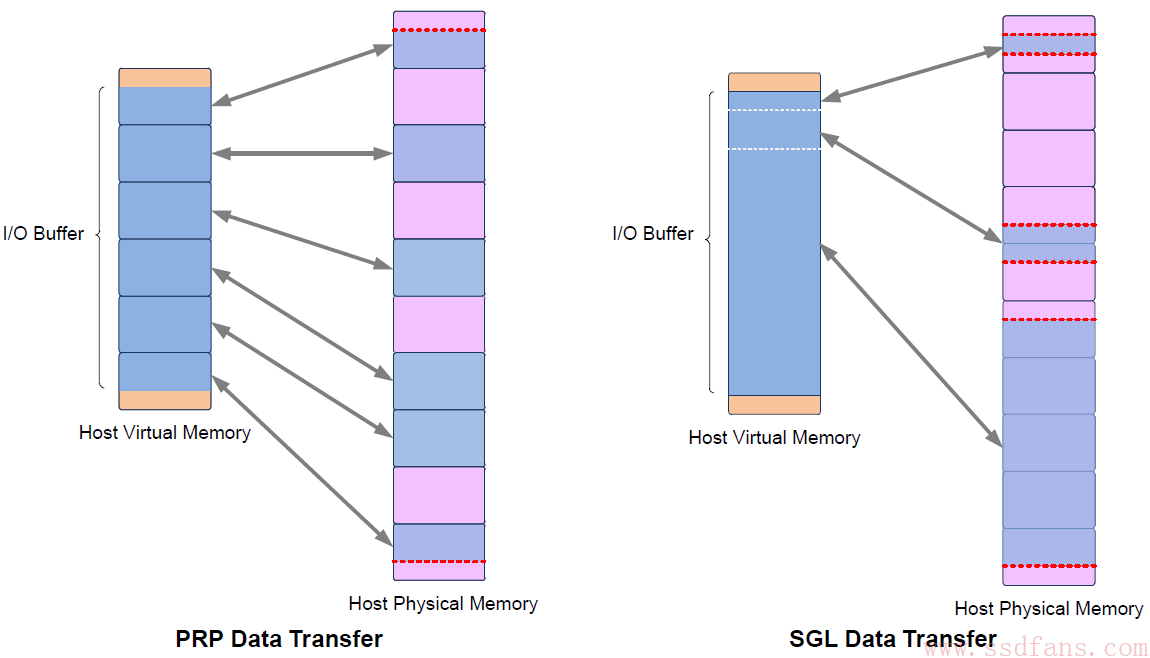
大家也许跟我有个同样的疑问(自作多情?),那就是,既然有PRP,为什么还需要SGL?事实上,NVMe1.0的时候的确只有PRP,SGL是NVMe1.1之后引入的。SGL和PRP本质的区别在哪?下图道出了真相:一段数据空间,对PRP来说,它只能映射到一个个物理页,而对SGL来说,它可以映射到任意大小的连续物理空间。
这章就到这吧。下面《蛋蛋读NVMe之四》,蛋蛋会带大家走基层,看看一个NVMe读写命令在PCIe层是怎样实现的。精彩继续,不要错过。