最近开始看一些object detection的文章,顺便整理一下思路。排版比较乱,而且几乎所有图片都是应用的博客或论文,如有侵权请联系我。
文章阅读路线参考
目前已完成的文章如下,后续还会继续补充(其中加粗的为精读文章):
- RCNN
- Overfeat
- MR-CNN
- SPPNet
- Fast RCNN
- A Fast RCNN
- Faster RCNN
- FPN
- R-FCN
- Mask RCNN
- YOLO
- YOLO 9000
- YOLO v3
- SSD
- DSSD
- R-SSD
- RetinaNet(focal loss)
- DSOD
- Cascade R-CNN
(待续)
吐槽一下,博客园的markdown竟然没有补齐功能,我还是先在本地补全再传上来吧。。。
RCNN之前的故事
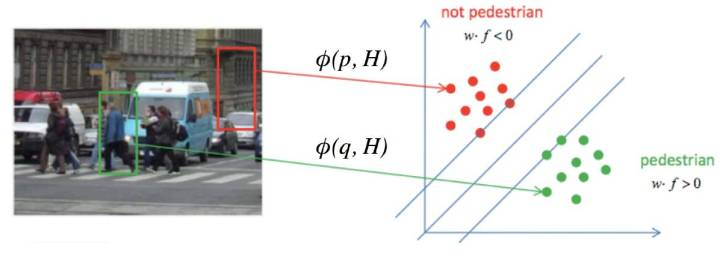
Histogram of Gradient (HOG) 特征
在深度学习应用之前,图像的特征是人工定义的具有鲁棒性的特征,如SIFT,HOG等,下面简要介绍一下HOG。
8x8像素框内计算方向梯度直方图: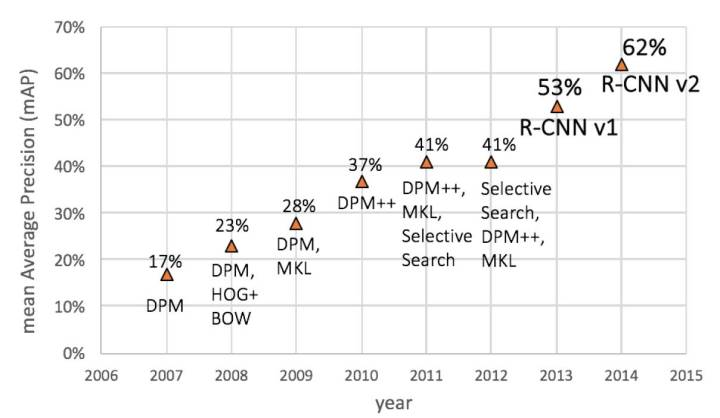
HOG Pyramid
特征金字塔,对于不同大小的物体进行适应,设计尺度不变性特征

HOG特征 -> SVM分类
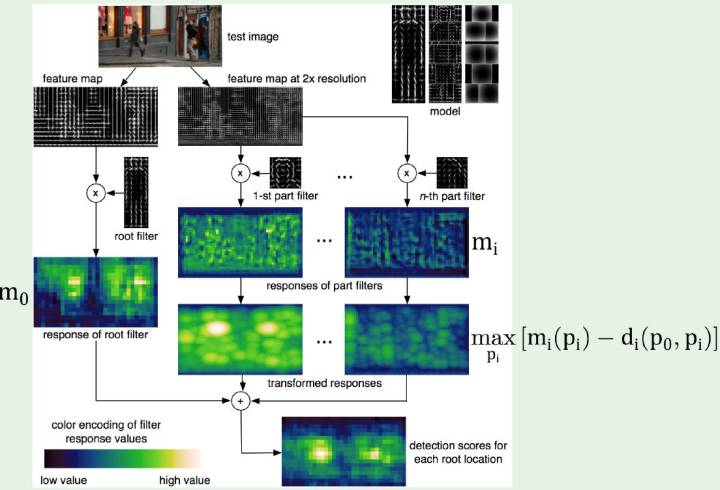
DPM模型 Deformable Part Model
加组件组合的HOG特征, 组件间计算弹性得分,优化可变形参数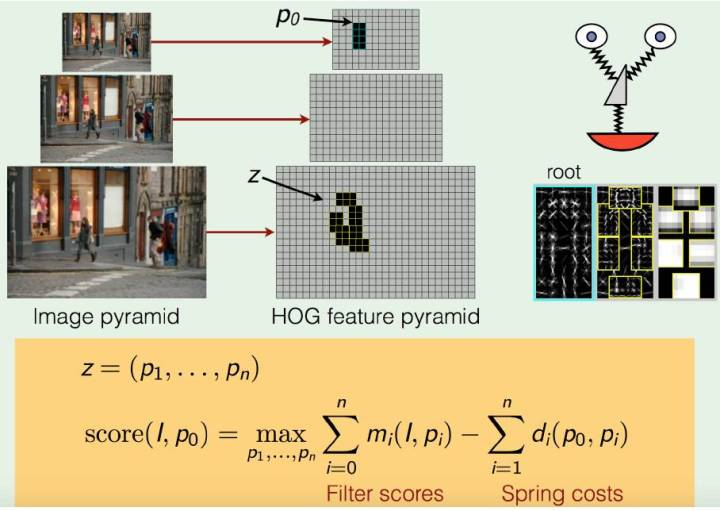
如果没有弹性距离,就是BoW (Bag of Word)模型, 问题很大, 位置全部丢失:

n个组件的DPM计算流程:
Selective Search 思想
过分割后基于颜色纹理等相似度合并,
然后,过分割、分层合并、建议区域排序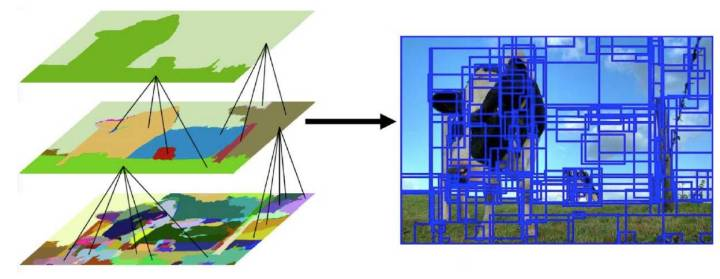
基于Selective Search + DPM/HoG + SVM的物体识别
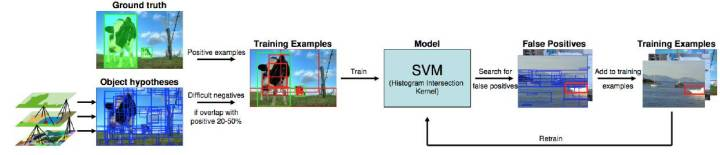
此时的框架就是RCNN的雏形,因为DPM就是基本由RBG和他导师主导,所以大神就是大神。
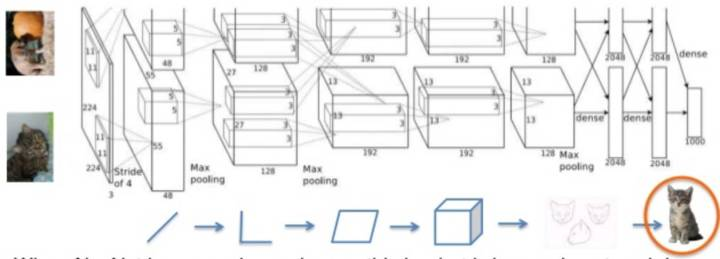
AlexNet的图像分类(深度学习登场)
2012年AlexNet赢得LSVRC的ImageNet分类竞赛。深度CNN结构用来图像特征提取。
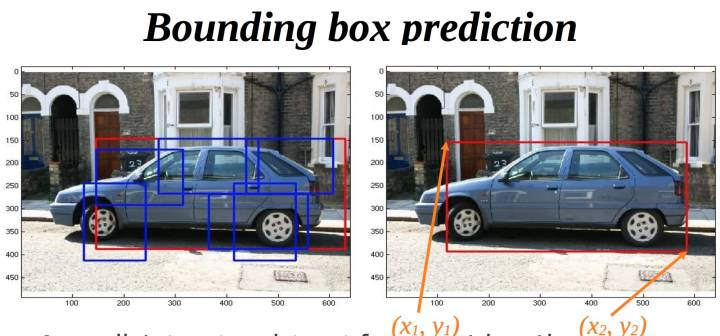
bounding-box regression 框回归
BBR 在DPM时代就和SVM分类结合,一般直接使用线性回归,或者和SVR结合
RCNN: Rich feature hierarchies for accurate object detection and semantic segmentation
RCNN作为深度学习用于目标检测的开山之作,可以看出是基于Selective Search + DPM/HoG + SVM框架,只不过将是将手工特征转变为CNN提取特征,本文主要贡献如下:
- CNN用于object detection
- 解决数据集不足的问题
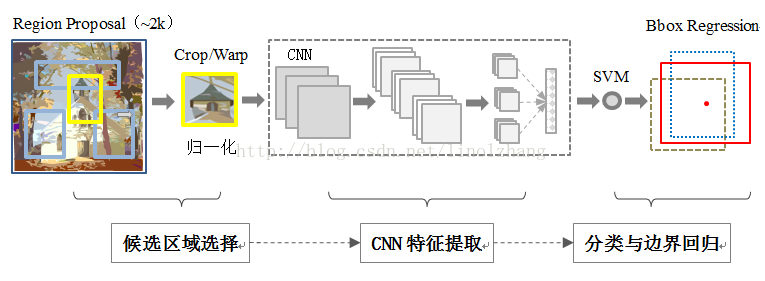
主要流程如下:
-
regional preposals(selective research)
-
CNN feature extraction
-
SVM Classification
-
NMS
-
bounding-box regression(BBR)
为啥能work?
- 优秀的目标检测框架,region proposal 和 regression offset降低了目标检测的难度,
- 强大的CNN特征提取器,代替传统的已经到瓶颈的手工特征
- 迁移训练降低了对数据集的要求
MR-CNN:Object detection via a multi-region & semantic segmentation-aware CNN model
Multi-Region的提出, 开始对Box进一步做文章, 相当于对Box进一步做增强,希望改进增强后的效果,主要改善了部分重叠交叉的情况。

特征拼接后使得空间变大,再使用SVM处理, 效果和R-CNN基本类似.
OverFeat:Integrated Recognition, Localization and Detection using Convolutional Networks
不得不说虽然OverFeat在但是比赛成绩不是太好,但是它的思想还是很有启发性的。
OverFeat直接抛弃了Selective Search,采用CNN上slide windows来进行框推荐,并且把Bounding box Regression整合一起使用全连接层搞定, 解决了后面一端的问题(取代了SVM分类器和BBR线性回归器),这个思想影响了后来的Fast RCNN。是第一个End to End 的目标检测模型,模型虽然简陋,但是可以验证网络强大的拟合能力注意整合目标检测的各项功能(分类,回归)。
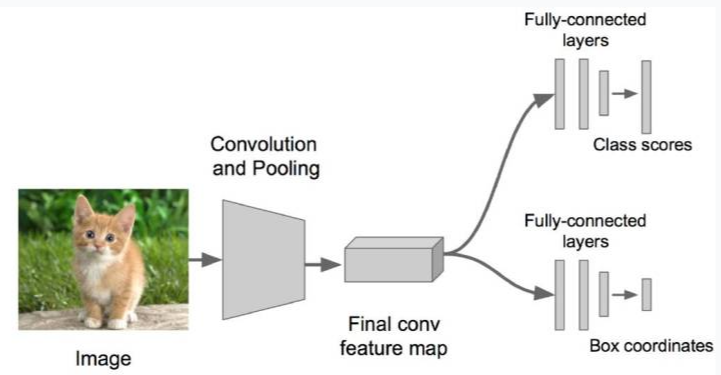
亮点:
- 先用CNN得到feature map再做slide windows推荐区域,避免了特征重复计算。
- 设计了End to End模型,方便优化和加快检测速度
- 设计全卷积网络,并进行多尺度图像训练
- maxpool offset(没有Fast RCNN的ROI Pooling自然)
为啥能work?
可以看出OverFeat将不同的两个问题物体分类和位置回归采用了两个分支网络,共用前面的CNN特征表述,而CNN提取的特征正如OverFeat所言,是一种类似于SIFT,HOG等人工描述子的一种稳定的描述子(底层抽象),可以用于构建不同的任务(高层表述),也就是模型为什么能work的原因。
SPPNet
R-CNN和Overfeat都存在部分多尺度,重叠效果的问题。 某种意义上, 应对了HoG特征, 这样对于物体来说类似BoW模型, 我们知道DPM里面,是带有组件空间分布的弹性得分的, 另外也有HoG Pyramid的思想。 如何把Pyramid思想和空间限制得分加入改善多尺度和重叠的效果呢? MR-CNN里面尝试了区域增强, Overfeat里面尝试了多尺度输入。 但是效果都一般。 这里我们介绍另外一个技术Spatial Pyramid Matching, SPM,是采用了空间尺度金字塔的特点。和R-CNN相比做到了先特征后区域, 和Overfeat相比自带Multi-Scale。
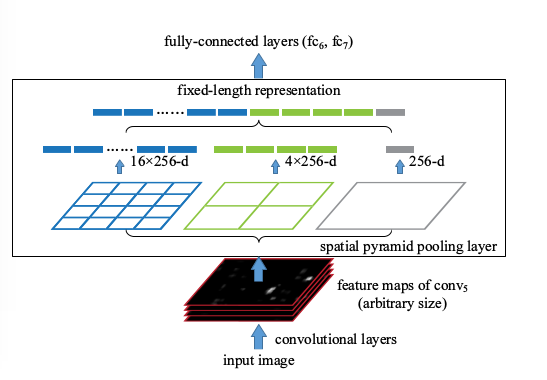
SPP pooling layer 的优势:
- 解决了卷积层到全连接层需要固定图片大小的问题,方便多尺度训练。
- 能够对于任意大小的输入产生固定的输出,这样使得一幅图片的多个region proposal提取一次特征成为可能。
- 进一步强调了CNN特征计算前移, 区域处理后移的思想, 极大节省计算量
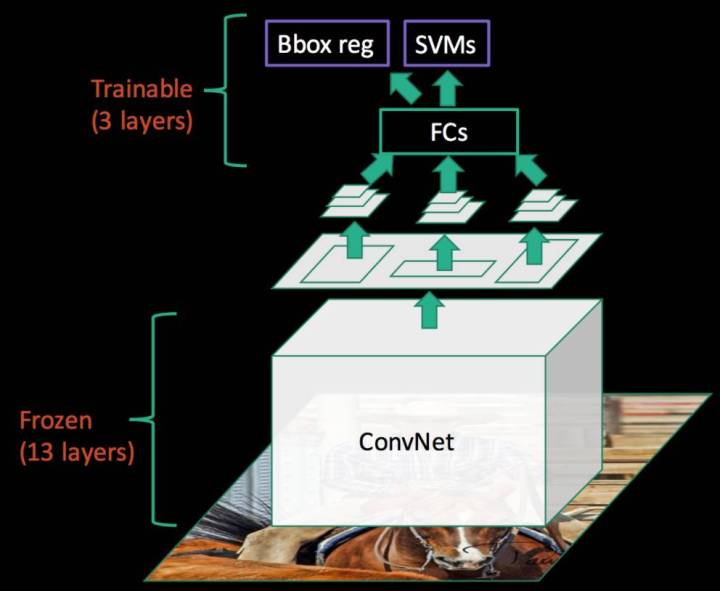
也能看出文章还是强调用CNN做特征的提取,还是用的BBR和SVM完成回归和分类的问题
Fast RCNN
可以看出Fast RCNN结合了OverFeat和Sppnet的实现,打通了高层表述和底层特征之间的联系

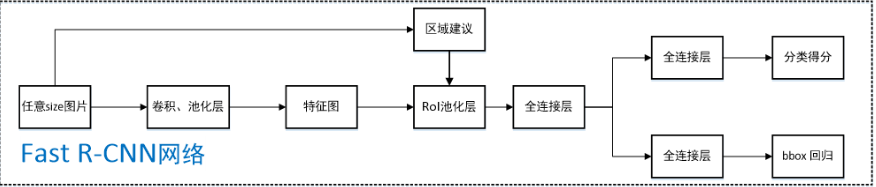
主要流程:
-
任意size图片输入CNN网络,经过若干卷积层与池化层,得到特征图;
-
在任意size图片上采用selective search算法提取约2k个建议框;
-
根据原图中建议框到特征图映射关系,在特征图中找到每个建议框对应的特征框【深度和特征图一致】,并在RoI池化层中将每个特征框池化到H×W【VGG-16网络是7×7】的size;
-
固定H×W【VGG-16网络是7×7】大小的特征框经过全连接层得到固定大小的特征向量;
-
将上一步所得特征向量经由各自的全连接层【由SVD分解实现(全连接层加速)】,分别得到两个输出向量:一个是softmax的分类得分,一个是Bounding-box窗口回归;
-
利用窗口得分分别对每一类物体进行非极大值抑制剔除重叠建议框
其中ROI POOL层是将每一个候选框映射到feature map上得到的特征框经池化到固定的大小,其次用了SVD近似求解实现全连接层加速。
这里需要注意的一点,作者在文中说道即使进行多尺度训练,map只有微小的提升,scale对Fast RCNN的影响并不是很大,反而在测试时需要构建图像金字塔使得检测效率降低。这也为下一步的多尺度改进埋下了伏笔。
为啥能更好的work?
也是结合了OverFeat的和SPPnet的work,同时规范了正负样本的判定(之前由于SVM和CNN对区域样本的阈值划分不同而无法统一网络,当然这只是其中的一个原因。更多的估计是作者当时没想到),将网络的特征抽取和分类回归统一到了一个网络中。
A Fast RCNN: Hard Positive Generation via Adversary for Object Detection
这篇论文是对,CMU与rbg的online hard example mining(OHEM)改进,hard example mining是一个针对目标检测的难例挖掘的过程,这是一个更充分利用数据集的过程。实际上在RCNN训练SVM时就已经用到,但是OHEM强调的是online,即如何在训练过程中选择样本。同期还有S-OHEM的改进。
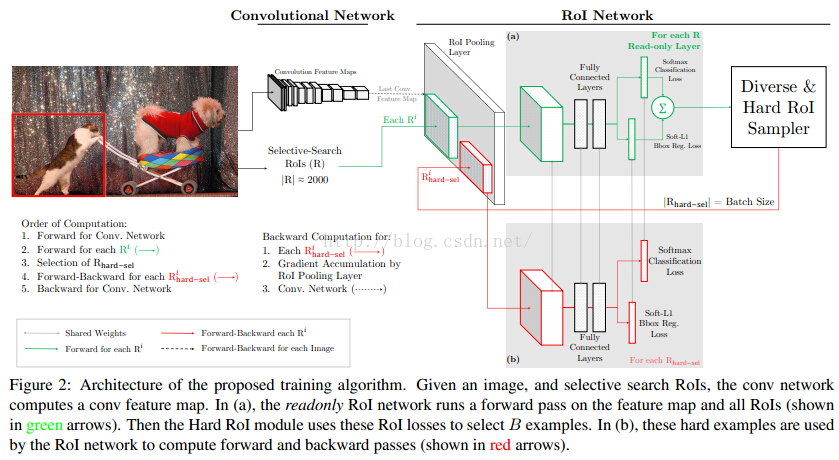
而随着但是GAN的火热,A-Fast-RCNN尝试生成hard example(使用对抗网络生成有遮挡和有形变的两种特征,分别对应网络ASDN和ASTN)
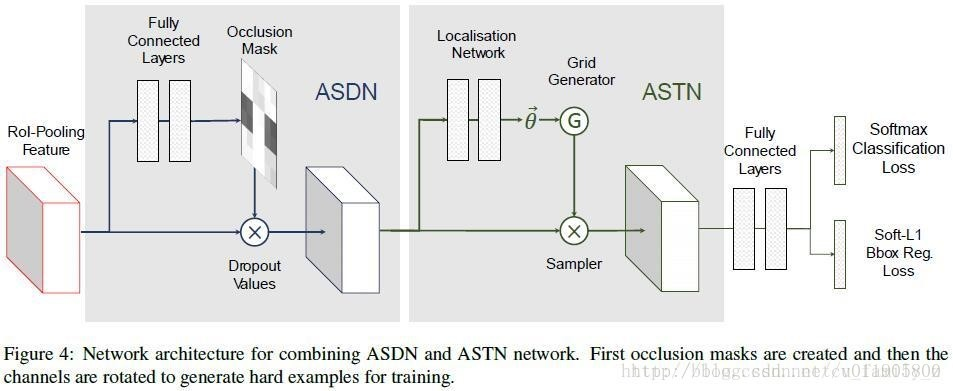
结论如下:
ASTN 和 随机抖动(random jittering)做了对比,发现使用AlexNet,mAP分别是58.1%h和57.3%,使用VGG16,mAP分别是69.9%和68.6%,ASTN 的表现都比比随机抖动效果好。作者又和OHEM对比,在VOC 2007数据集上,本文方法略好(71.4% vs. 69.9%),而在VOC 2012数据集上,OHEM更好(69.0% vs. 69.8%)。gan用于目标检测还没有很好的idea,这篇论文相当于抛砖引玉了。
同时需要注意的一个问题,网络对于比较多的遮挡和形变情况识别情况更好;但是对于正常目标的特征抽象能力下降,所以有时候创造难例也要注意样本的数量。下面是一些由于遮挡原因造成的误判。

Faster RCNN:Towards Real-Time Object Detection with Region Proposal Networks
这篇文章标志着two-stage目标检测的相对成熟,其主要改进是对候选区域的改进,将候选区域推荐整合进了网络中。
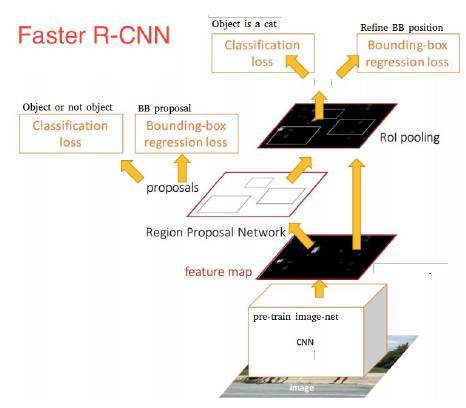
结合后面的一系列文章,可以马后炮一下它的缺点:
- 虽然Faster RCNN已经共享了绝大部分卷积层运算,但是RoI之后还有部分ConvNet的计算,有没有可能把ROI之上的计算进一步前移? 请看R-FCN
- Faster RCNN还是没有很好的解决多尺度问题,如何解决,请看FPN
YOLO:You Only Look Once
作者的论文简直是一股论文界的泥石流,作者本身是一个喜欢粉红小马的大叔,萌萌哒。实际上YOLO一直发展到v3都是简单粗暴的目标检测方法,虽然学术界模型繁杂多样,但是在实际应用工业应用上YOLO绝对是一个首选的推荐。YOLO v1版本现在看来真是简单粗暴,也印证了网络抽象的强大之处。可以看出作者没有受到太多前辈的影响,将对象检测重新定义为单个回归问题,直接从图像像素到边界框坐标和类概率(当然这也是一个缺少坐标约束也是一个缺点)。

YOLO的明显缺点,如多尺度问题,密集物体,检测框耦合,直接回归坐标等在yolo 9000中也做了比较好的改进。
SSD:Single Shot MultiBox Detector
SSD作为one stage的代表模型之一,省去了判断推荐候选区域的步骤(实际上可以认为one-stage就是以feature map cell来抽象代替ROI Pooling功能) ,虽然SSD和Faster RCNN在Anchor box上一脉相承,但是Faster RCNN却还是有一个推荐候选区域(含有物体的区域)的监督部分(注意后面其实也是整合到了最终Loss中),因此one-stage优势是更快,而含有区域推荐的two-stage目前是更加准确一些。(更看好one-stage,其实区域推荐不太符合视觉系统,但是可以简化目标检测问题),主要贡献:
- 用多尺度feature map来预测,也生成了更多的default box
- 检测框对每一类对象产生分数(低耦合,对比yolo)

缺点:
- 底层feature map高级语义不足 (FPN)
- 正负样本影响 (focal loss)
- feature map抽象分类和回归任务只用了两个卷积核抽象性不足(DSSD)
为啥能更好的工作?
SSD的出现对多尺度目标检测有了突破性进展,利用卷积层的天然金字塔形状,设定roi scale让底层学习小物体识别,顶层学习大物体识别
FPN:feature pyramid networks
SSD网络引入了多尺度feature map,效果显著。那Faster RCNN自然也不能落后,如何在Faster RCNN中引入多尺度呢?自然有FPN结构
同时FPN也指出了SSD因为底层语义不足导致无法作为目标检测的feature map
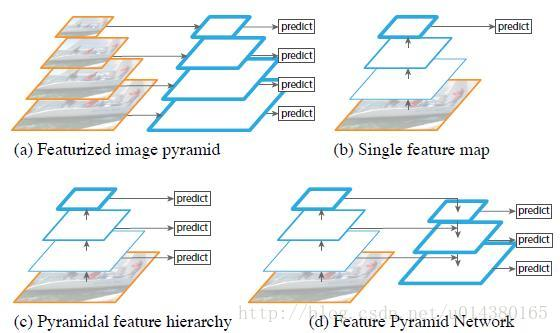
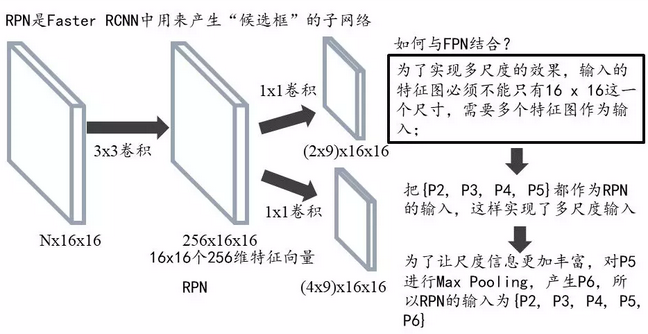
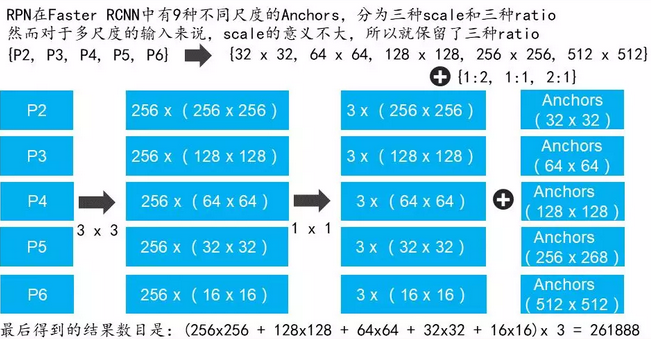
注意原图的候选框在Faster RCNN中只固定映射到同一个ROI Pooling中,而现在如果某个anchor和一个给定的ground truth有最高的IOU或者和任意一个Ground truth的IOU都大于0.7,则是正样本。如果一个anchor和任意一个ground truth的IOU都小于0.3,则为负样本。
本文算法在小物体检测上的提升是比较明显的,另外作者强调这些实验并没有采用其他的提升方法(比如增加数据集,迭代回归,hard negative mining),因此能达到这样的结果实属不易。
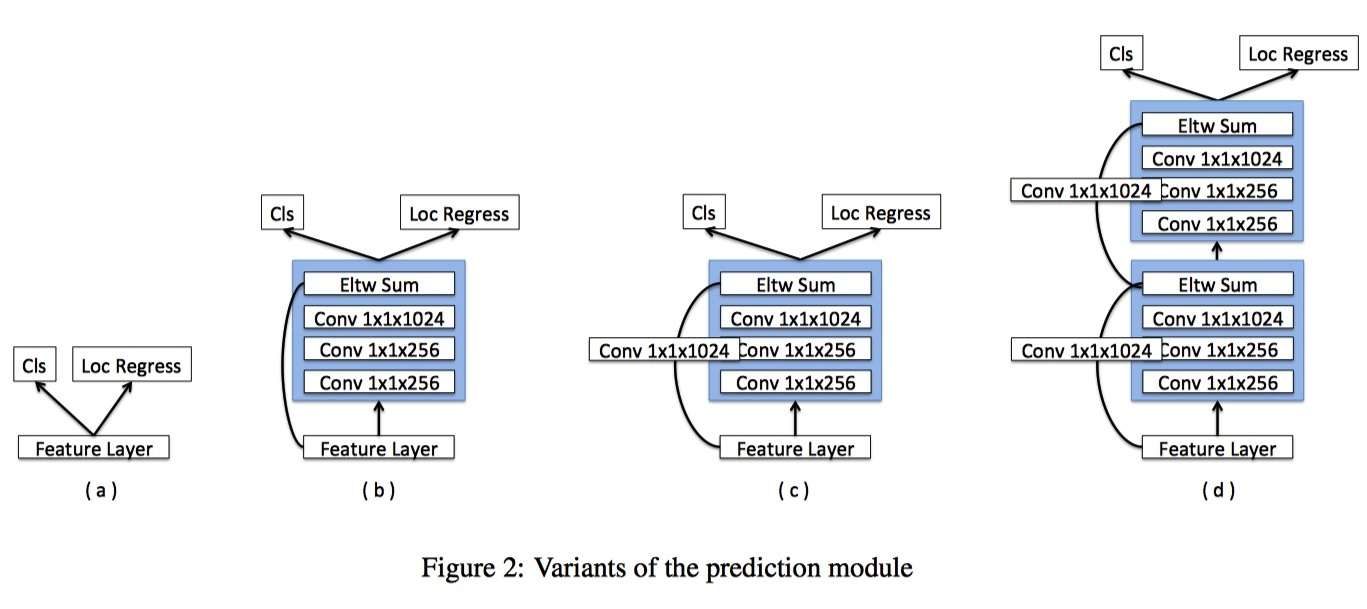
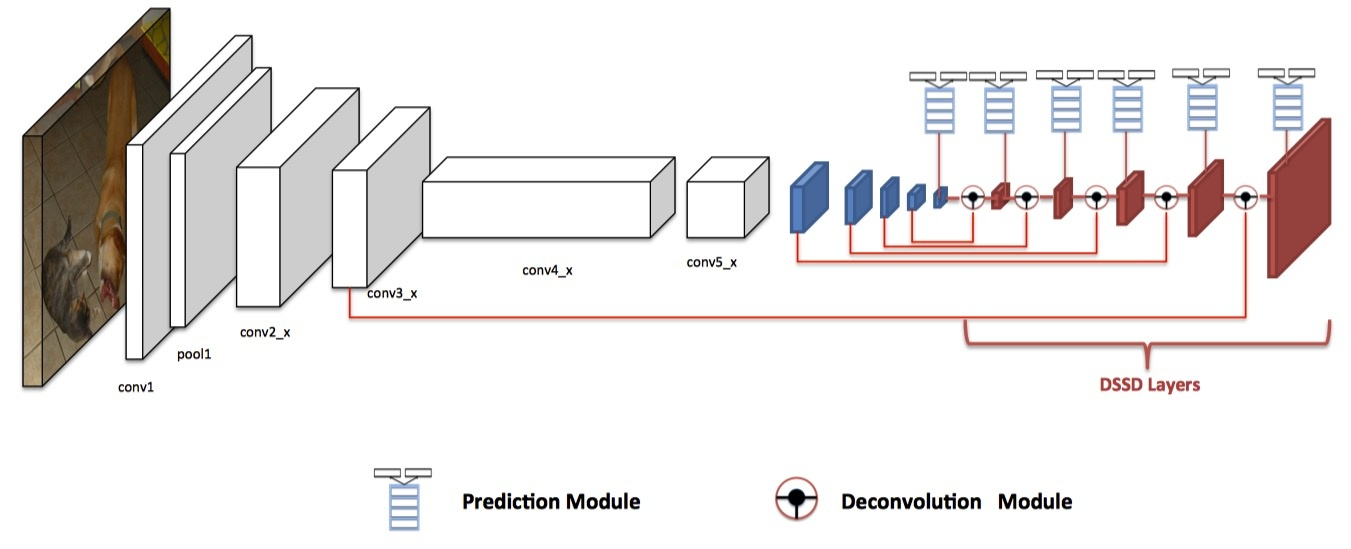
DSSD:Deconvolutional Single Shot Detector
一个SSD上移植FPN的典型例子,作者主要有一下改动:
- 将FPN的Upsampling变成deconv
- 复杂了高层表述分支(分类,回归)网络的复杂度
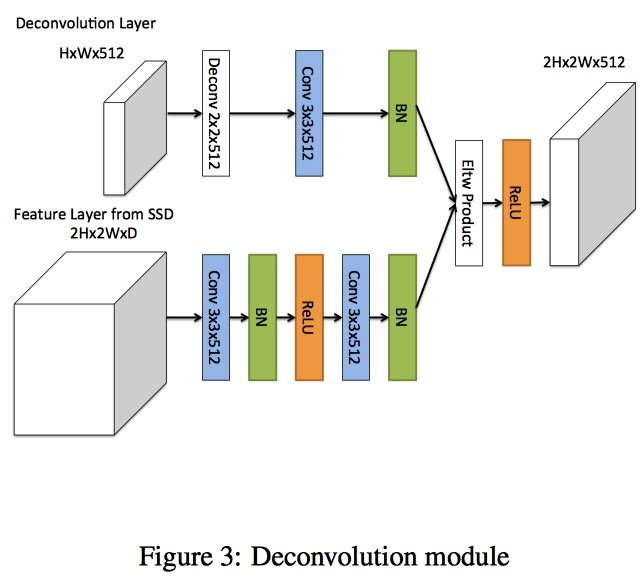
R-SSD:Enhancement of SSD by concatenating feature maps for object detection
本文着重讨论了不同特征图之间的融合对SSD的影响(水论文三大法宝),这篇论文创新点不是太多,就不说了
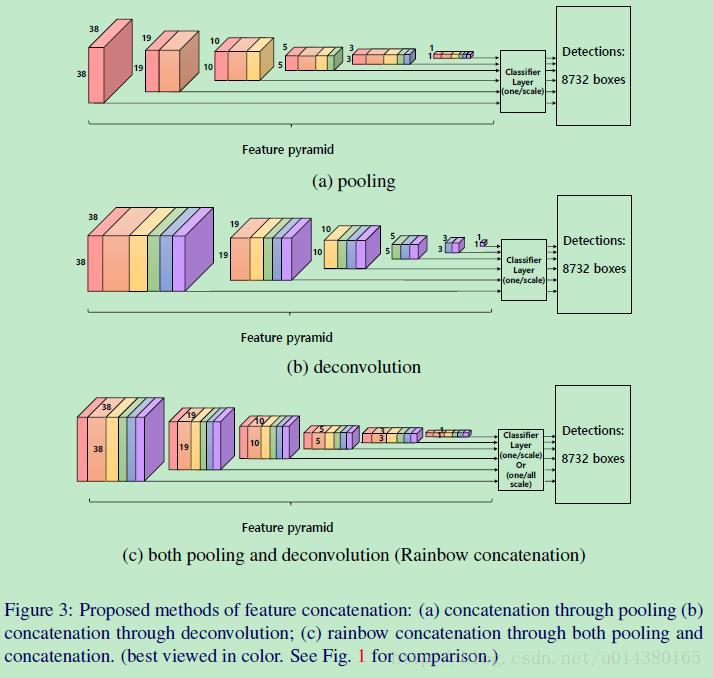
DSOD: Learning Deeply Supervised Object Detectors from Scratch
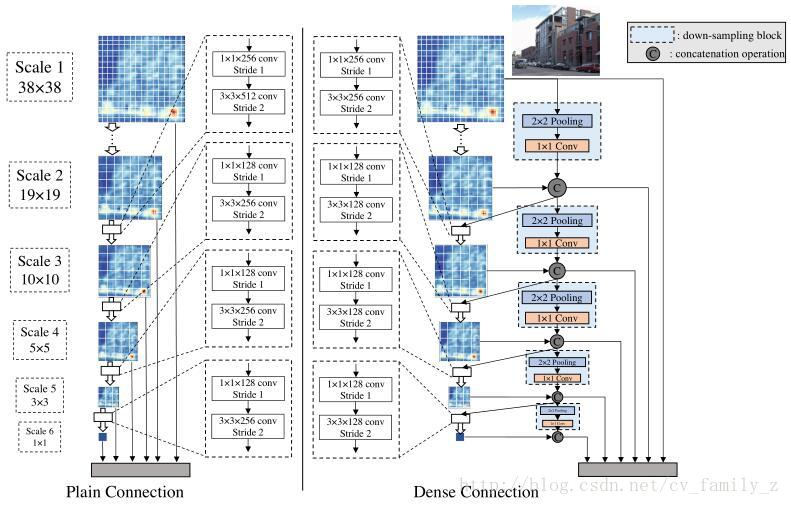
这篇文章的亮点:
- 提出来了不需要预训练的网络模型
- DSOD实际上是densenet思想+SSD,只不过并不是在base model中采用densenet,而是密集连接提取default dox的层,这样有一个好处:通过更少的连接路径,loss能够更直接的监督前面基础层的优化,这实际上是DSOD能够直接训练也能取得很好效果的最主要原因,另外,SSD和Faster RCNN直接训练无法取得很好的效果果然还是因为网络太深(Loss监督不到)或者网络太复杂。
- Dense Prediction Structure 也是参考的densenet
- stem能保留更多的信息,好吧,这也行,但是对效果还是有提升的。

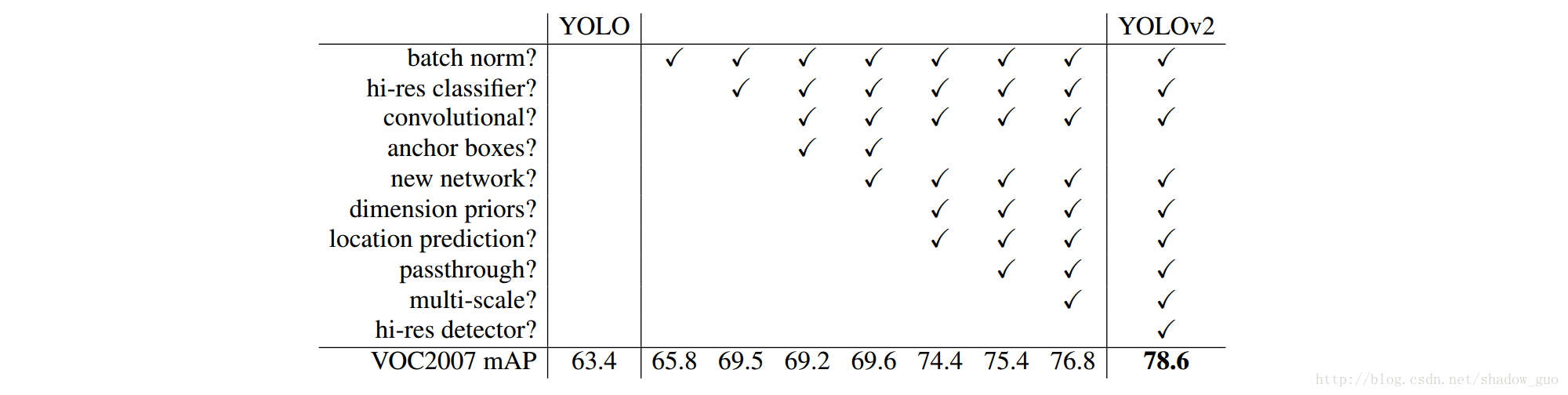
YOLO 9000:Better, Faster, Stronger
很喜欢这个作者的论文风格,要是大家都这么写也会少一点套路,多一点真诚。。。。文章针对yolo做了较多的实验和改进,简单粗暴的列出每项改进提升的map。这个建议详细的看论文。下面列举几个亮点:
- 如何用结合分类的数据集训练检测的网络来获得更好的鲁棒性
- 将全连接层改为卷积层并结合了细粒度信息(passthrough layer)
- Multi-Scale Traning
- Dimension Clusters
- darknet-19更少的参数
- Direct locaion prediction对offset进行约束

R-FCN:Object Detection via Region-based Fully Convolutional Networks
本文提出了一个问题,base CNN网络是为分类而设计的(pooling 实际上是反应了位置的不变性,我一张人脸图片只要存在鼻子,两只眼睛,分类网络就认为它是人脸,这也就是Geoffrey Hinton 在Capsule中吐槽卷积的缺陷),而目标检测则要求对目标的平移做出准确响应。Faster RCNN是通过ROI pooling让其网络学习位置可变得能力的,再次之前的base CNN还是分类的结构,之前讲过R-FCN将Faster RCNN ROI提取出来的部分的卷积计算共享了,那共享的分类和回归功能的卷积一定在划分ROI之前,那么问题来了,如何设计让卷积对位置敏感?
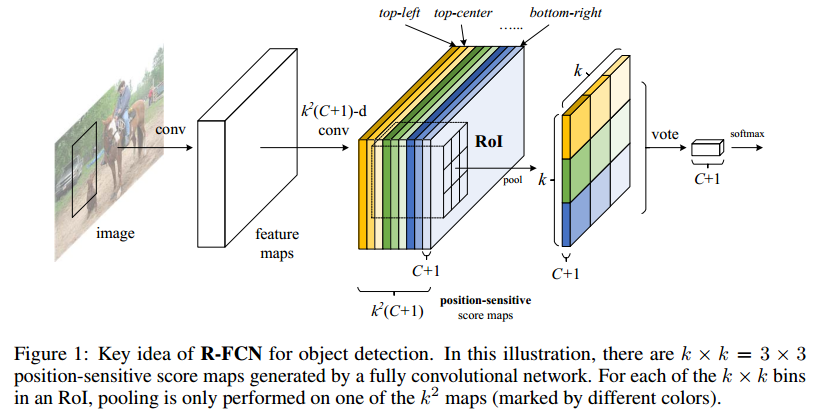
主要贡献:
- 将用来回归位置和类别的卷积前置共享计算,提高了速度。
- 巧妙设计score map(feature map)的意义(感觉设计思想和yolo v1最后的全连接层一样),让其何以获得位置信息,之后在经过ROI pooling和vote得到结果
为啥能work?
实际上rfcn的feature map设计表达目标检测问题的方式更加抽象(ROI pool前的feature map中每一个cell的channel代表定义都很明确),loss在监督该层时更能通过论文中关于ROI pool和vote设计,在不同的channel上获得高的响应,这种设计方式可能更好优化(这个是需要大量的实验得出的结论),至于前面的resnet-base 自然是抽象监督,我们本身是无法理解的,只是作为fintuning。实际上fpn的loss监督也是非常浅和明确的,感觉这种可以理解的优化模块设计比较能work。
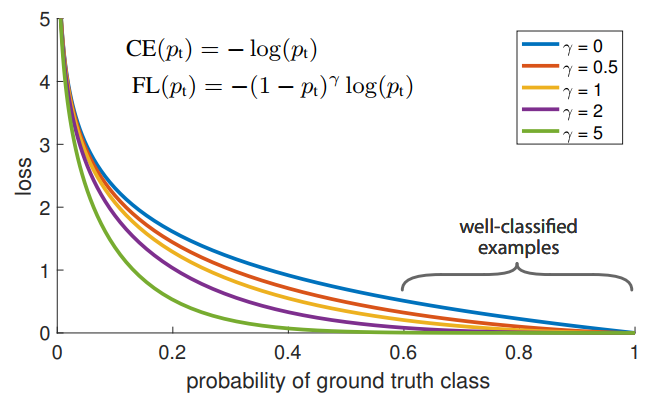
Focal Loss: Focal Loss for Dense Object Detection
这篇文章实际上提供了另外一个角度,之前一直认为Single stage detector结果不够好的原因是使用的feature不够准确(使用一个位置上的feature),所以需要Roi Pooling这样的feature aggregation办法得到更准确的表示。但是这篇文章基本否认了这个观点,提出Single stage detector不好的原因完全在于:
-
极度不平衡的正负样本比例: anchor近似于sliding window的方式会使正负样本接近1000:1,而且绝大部分负样本都是easy example,这就导致下面一个问题:gradient被easy example dominant的问题:往往这些easy example虽然loss很低,但由于数 量众多,对于loss依旧有很大贡献,从而导致收敛到不够好的一个结果。
所以作者的解决方案也很直接:直接按照loss decay掉那些easy example的权重,这样使训练更加bias到更有意义的样本中去。很直接地,如下图所示:
实验中作者比较了已有的各种样本选择方式: -
按照class比例加权重:最常用处理类别不平衡问题的方式
-
OHEM:只保留loss最高的那些样本,完全忽略掉简单样本
-
OHEM+按class比例sample:在前者基础上,再保证正负样本的比例(1:3)
Focal loss各种吊打这三种方式,coco上AP的提升都在3个点左右,非常显著。值得注意的是,3的结果比2要更差,其实这也表明,其实正负样本不平衡不是最核心的因素,而是由这个因素导出的easy example dominant的问题。
RetinaNet 结构如下
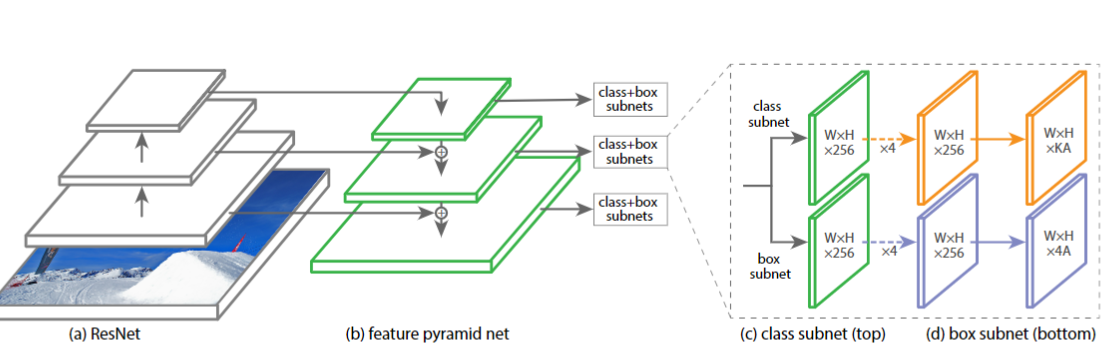
实际上就是SSD+FPN的改进版