redis的复制技术和高可用(哨兵模式)
1 复制
为什么要复制
实现数据的多副本存储,从而可以实现服务的高可用
提供更好的读性能
复制技术的关键点及难点
如何指定被复制对象
增量还是全量以及如何实现增量?
复制时不影响前端业务的操作
网络被中断后如何处理
如何防止发送出去的数据丢失,没有达到从服务器
如何识别被复制的数据源发生变化,导致数据出错
复制步骤
步骤
1.指定master
配置文件配置slaveof
从节点命令行执行slaveof命令
2.建立socket连接
从服务器根据配置或者命令行命令slaveof创建连向主服务器的socket
3.发送ping命令:当连接创建后发送
通过ping命令检查socket的读写状态是否正常
检查主服务器是否能正常处理命令请求
当从服务器不能在规定时间内得到ping的回复,则表示网络不正常,从服务器会断开socket并重新创建连接
如果从服务器收到主服务器返回一个错误信息,比如BUSY redisis busy running a script,you can …,则从服务器会断开连接并重新创建连接
如果从服务器收到的回应是”PONG”,则表示一切正常,可以执行下一步流程
配置部署
4.身份验证
如果从服务器设置了masterauth选项,则进行身份验证,否则不进行
通过向master发送命令auth来实现认证,比如auth passwd
当master没有设置requirepass时,会提示错误no password is set
如果master的设置与slave的密码不一样,则出现invalid password错误
5.发送端口信息
从服务器执行命令REPLCONF listening-port <port-number>,向主服务器发送从服务器的命令监听端口
这端口号是为了在master上执行info命令时,可以查看到从节点的端口信息
6.同步
主从服务器之间互为客户端,可以彼此发送命令和响应回应
7.命令传播
主服务器执行完命令后会发送给从服务器
配置说明
slaveof <masterip> <masterport> //指定被复制的数据源
masterauth <master-password> //被复制数据源的认证密码
slave-serve-stale-data yes
yes表示当slave与master之间的连接断开或者正在处于复制中时,slave服务器可以接收客户端的请求,缺点是可能会读取到过期的数据
No表示不接收客户端的请求,返回错误信息"SYNC with master in progress"
slave-read-only yes //从服务器是否只读,如果不是只读,可能会从和主之间的数据不一致
repl-ping-slave-period 10 //slave向master发送ping的周期频率,单位是妙
repl-timeout 60 //复制超时时间
slave在与master SYNC期间有大量数据传输,造成超时
在slave角度,master超时,包括数据、ping等
在master角度,slave超时,当master发送REPLCONF 、 ACK pings
repl-disable-tcp-nodelay no
如果你选择“yes”Redis将使用更少的TCP包和带宽来向slaves发送数据,本质就是提高包的有效利用率,但是会导致一定的数据延迟,linux系统是40ms
如果你选择了 “no”,包利用率不高,但是延迟低
repl-backlog-size 1mb //master端的固定缓冲区,影响从节点与主节点网络中断后是否全部同步
repl-backlog-ttl 3600 //当slave与master断开后,一定时间超时后,释放backlog里面的数据
slave-priority 100
用于配置从节点的优先级,当主站不能正常工作时,redis sentinel使用它来选择一个从站并将它提升为主站,低优先级的从站被认为更适合于提升
当满足下面的条件时,主不接收前端的写请求
min-slaves-to-write 3 //最少多少个slave在线,默认是0,表示关闭此功能
min-slaves-max-lag 10//最小时间延迟
心跳检测
从服务器默认每秒一次的频率想主发送心跳命令:REPLCONF ACK <replication_offset>
通过心跳检测可以知道网络状况,通过info命令可以查看到lag参数,表示主从延迟,单位是秒,一般为0或者1
在心跳检测中带有当前从的复制偏移量,当主发送给从的命令有丢失时,可以通过这种高频的心跳检测及时发现偏移量不正确,主服务器可以把缺失的命令重新发给从服务器
通过心跳检查可以实现min-slaves功能,即如果主从状态不正常时,不允许主写入数据
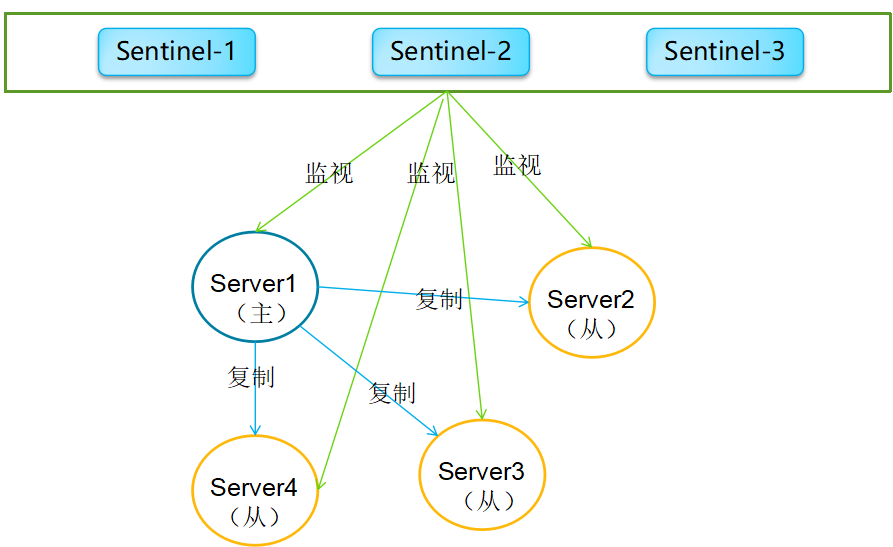
高可用--sentinel
Redis高可用应该解决那些问题
多个节点拥有相同的数据
复制技术
当主节点宕机后,如何产生新的主节点
当主节点宕机后,从节点如何自动连接到新的主节点
如何判断主节点宕机
旧的主节点恢复后,如何处理
如何监控redis所有节点的健康状态
什么是sentinel(哨兵)
本身也就是redis程序的一部分
主要功能
监控redis节点的健康状态
通知,把监控到的变化通知给相关系统或者redis实例,通过redis的订阅机制实现
自动热备(failover),主节点宕机----选举新的主节点
配置管理,redis实例可以通过sentinel获取到某些共享信息
Sentinel本身也是分布式,解决了自身单点问题
安装redis 哨兵
1 ip
role IP port
master 127.0.0.1 6379
slave1 127.0.0.1 6380
slave2 127.0.0.1 6381
Sentinel1 127.0.0.1 26379
Sentinel2 127.0.0.1 26380
Sentinel3 127.0.0.1 26381
2 master节点
配置
daemonize yes
pidfile /var/run/redis_6379.pid
port 6379
logfile "/etc/redis/63079.log"
dbfilename dump.rdb
dir ./
appendonly yes
启动
/usr/local/redis/src/redis-server /etc/redis/6379.conf
/usr/local/redis/src/redis-cli -h 127.0.0.1 -p 6379 ping
启动两个从节点
配置(两个从节点配置相同,除了文件名有区分)
/usr/local/redis/src/redis-server /etc/redis/6380.conf
/usr/local/redis/src/redis-server /etc/redis/6381.conf
/usr/local/redis/src/redis-cli -h 127.0.0.1 -p 6380 ping
daemonize yes
pidfile /var/run/redis_6380.pid
port 6380
logfile "/etc/redis/6380.log"
dbfilename dump-6380.rdb
dir ./
appendonly yes
appendfilename appendonly-6380.aof
slaveof 127.0.0.1 6379 // 从属主节点
3 确认主从关系
主节点视角
/usr/local/redis/src/redis-cli -h 127.0.0.1 -p 6379 INFO replication
[root@hongquan1 redis]# /usr/local/redis/src/redis-cli -h 127.0.0.1 -p 6379 INFO replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=351,lag=1
slave1:ip=127.0.0.1,port=6381,state=online,offset=351,lag=0
master_repl_offset:351
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:350
从节点视角(6380端口)
/usr/local/redis/src/redis-cli -h 127.0.0.1 -p 6380
/usr/local/redis/src/redis-cli -h 127.0.0.1 -p 6380 INFO replication
[root@hongquan1 ~]# /usr/local/redis/src/redis-cli -h 127.0.0.1 -p 6380 INFO replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:6
master_sync_in_progress:0
slave_repl_offset:463
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=109490,lag=1
slave1:ip=127.0.0.1,port=6381,state=online,offset=109490,lag=1
master_repl_offset:109490
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:109489
4 部署Sentinel节点
/usr/local/redis/runtest-sentinel
/usr/local/redis/sentinel.conf
/usr/local/redis/src/redis-sentinel
3个Sentinel节点的部署方法是相同的(端口不同)。以26379为例
// Sentinel节点的端口
port 26379
dir /etc/redis/
logfile "26379.log"
// 当前Sentinel节点监控 127.0.0.1:6379 这个主节点
// 2代表判断主节点失败至少需要2个Sentinel节点节点同意
// mymaster是主节点的别名
sentinel monitor mymaster 127.0.0.1 6379 2
//每个Sentinel节点都要定期PING命令来判断Redis数据节点和其余Sentinel节点是否可达,如果超过30000毫秒且没有回复,则判定不可达
sentinel down-after-milliseconds mymaster 30000
//当Sentinel节点集合对主节点故障判定达成一致时,Sentinel领导者节点会做故障转移操作,选出新的主节点,原来的从节点会向新的
//主节点发起复制操作,限制每次向新的主节点发起复制操作的从节点个数为1
sentinel parallel-syncs mymaster 1
//故障转移超时时间为180000毫秒
sentinel failover-timeout mymaster 180000
启动(两种方法)
/usr/local/redis/src/redis-sentinel sentinel-26379.conf
/usr/local/redis/src/redis-server sentinel-26379.conf --sentinel
确认
/usr/local/redis/src/redis-cli -h 127.0.0.1 -p 26379 INFO Sentinel
[root@hongquan1 src]# /usr/local/redis/src/redis-cli -h 127.0.0.1 -p 26379 INFO Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
master0:name=mymaster,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=3 //sentinels=1表示启动了1个Sentinel
启动另外2节点
/usr/local/redis/src/redis-sentinel sentinel-26380.conf
/usr/local/redis/src/redis-sentinel sentinel-26381.conf
当部署号Redis Sentinel之后,会有如下变化
Sentinel节点自动发现了从节点、其余Sentinel节点。
去掉了默认配置,例如:parallel-syncs、failover-timeout。
新添加了纪元(epoch)参数。
我们拿端口26379的举例,启动所有的Sentinel和数据节点后,配置文件如下
# Generated by CONFIG REWRITE
sentinel known-slave mymaster 127.0.0.1 6381
sentinel known-sentinel mymaster 127.0.0.1 26381 3ffd9dcc66b8f11fbde922e194d60fbe16f112a8
sentinel known-sentinel mymaster 127.0.0.1 26380 1eb9076df7bbdd020895fd3de99e5800f1721ddc
sentinel current-epoch 0
[root@hongquan1 redis]# ps -ef|grep redis
root 632 335 0 07:10 pts/3 00:00:00 /usr/local/redis/src/redis-sentinel *:26380 [sentinel]
root 833 662 0 07:11 pts/4 00:00:00 /usr/local/redis/src/redis-sentinel *:26381 [sentinel]
root 1456 4984 0 07:15 pts/1 00:00:00 grep redis
root 3990 1 0 01:36 ? 00:00:16 /usr/local/redis/src/redis-server *:6379
root 4065 3883 0 01:37 pts/0 00:00:00 /usr/local/redis/src/redis-cli -h 127.0.0.1 -p 6379
root 29361 1 0 06:50 ? 00:00:01 /usr/local/redis/src/redis-server *:6380
root 29826 1 0 06:54 ? 00:00:01 /usr/local/redis/src/redis-server *:6381
root 32566 30303 0 07:07 pts/2 00:00:00 /usr/local/redis/src/redis-sentinel *:26379 [sentinel]
[root@hongquan1 ~]# /usr/local/redis/src/redis-cli -h 127.0.0.1 -p 26379
127.0.0.1:26379> sentinel masters
1) 1) "name"
2) "mymaster"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6379"
7) "runid"
8) "eff98fb5a83314a64958dfe9b8931f90237c1ba6"
9) "flags"
10) "master"
127.0.0.1:26379> sentinel slaves mymaster
1) 1) "name"
2) "127.0.0.1:6380"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6380"
7) "runid"
8) "6e6df117d1d081f554e9f71d29a7cfc9f78e3732"
9) "flags"
10) "slave"
2) 1) "name"
2) "127.0.0.1:6381"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6381"
7) "runid"
8) "a412ffbbf89b45776e21bc98ceffa4a47f890f74"
9) "flags"
10) "slave"
我们干掉端口6379的主节点
[root@hongquan1 redis]# kill 3990
127.0.0.1:26379> sentinel masters
1) 1) "name"
2) "mymaster"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6380" //可以看到主节点已经成为6380端口的节点
7) "runid"
8) "6e6df117d1d081f554e9f71d29a7cfc9f78e3732"
9) "flags"
10) "master"
127.0.0.1:26379> sentinel slaves mymaster
1) 1) "name"
2) "127.0.0.1:6379"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6379"
7) "runid"
8) ""
9) "flags"
10) "slave,disconnected" //端口6379的原主节点已经断开了连接
11) "pending-commands"
12) "0"
2) 1) "name"
2) "127.0.0.1:6381"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6381"
7) "runid"
8) "a412ffbbf89b45776e21bc98ceffa4a47f890f74"
9) "flags"
10) "slave" //本来的从节点,还是从节点的role
我们在试着重启端口6379的数据节点。
/usr/local/redis/src/redis-server /etc/redis/6379.conf
[root@hongquan1 redis]# ps -ef|grep redis
root 632 335 0 07:10 pts/3 00:00:01 /usr/local/redis/src/redis-sentinel *:26380 [sentinel]
root 833 662 0 07:11 pts/4 00:00:01 /usr/local/redis/src/redis-sentinel *:26381 [sentinel]
root 2475 3883 0 07:20 pts/0 00:00:00 /usr/local/redis/src/redis-cli -h 127.0.0.1 -p 26379
root 3429 1 0 07:25 ? 00:00:00 /usr/local/redis/src/redis-server *:6379
root 3550 4984 0 07:25 pts/1 00:00:00 grep redis
root 29361 1 0 06:50 ? 00:00:01 /usr/local/redis/src/redis-server *:6380
root 29826 1 0 06:54 ? 00:00:01 /usr/local/redis/src/redis-server *:6381
root 32566 30303 0 07:07 pts/2 00:00:01 /usr/local/redis/src/redis-sentinel *:26379 [sentinel]
127.0.0.1:26379> sentinel slaves mymaster
1) 1) "name"
2) "127.0.0.1:6379" //6379端口的节点重启后,变成了"活"的从节点
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6379"
7) "runid"
8) "7b6a9883cd40391047a7a5effa70971e888a8de5"
9) "flags"
10) "slave"
2) 1) "name"
2) "127.0.0.1:6381" //6381端口的节点没有变化,仍是从节点
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6381"
7) "runid"
8) "a412ffbbf89b45776e21bc98ceffa4a47f890f74"
9) "flags"
[root@hongquan1 ~]# /usr/local/redis/src/redis-cli -h 127.0.0.1 -p 6380
127.0.0.1:6380> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6381,state=online,offset=50937,lag=0
slave1:ip=127.0.0.1,port=6379,state=online,offset=50671,lag=1
master_repl_offset:50937
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:50936
从上面的逻辑架构和故障转移试验中,可以看出Redis Sentinel的以下几个功能。
监控:Sentinel节点会定期检测Redis数据节点和其余Sentinel节点是否可达。
通知:Sentinel节点会将故障转移通知给应用方。
主节点故障转移:实现从节点晋升为主节点并维护后续正确的主从关系。
配置提供者:在Redis Sentinel结构中,客户端在初始化的时候连接的是Sentinel节点集合,从中获取主节点信息。
[root@hongquan1 redis]# tail -n 100 26380.log
632:X 16 Apr 07:10:51.086 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
632:X 16 Apr 07:10:51.086 # Sentinel runid is 1eb9076df7bbdd020895fd3de99e5800f1721ddc
632:X 16 Apr 07:10:51.086 # +monitor master mymaster 127.0.0.1 6379 quorum 2
632:X 16 Apr 07:10:51.899 * +sentinel sentinel 127.0.0.1:26379 127.0.0.1 26379 @ mymaster 127.0.0.1 6379
632:X 16 Apr 07:12:00.436 * +sentinel sentinel 127.0.0.1:26381 127.0.0.1 26381 @ mymaster 127.0.0.1 6379
632:X 16 Apr 07:23:41.083 # +sdown master mymaster 127.0.0.1 6379
632:X 16 Apr 07:23:41.173 # +new-epoch 1 #新一轮选举
632:X 16 Apr 07:23:41.174 # +vote-for-leader 3ffd9dcc66b8f11fbde922e194d60fbe16f112a8 1
632:X 16 Apr 07:23:41.183 # +odown master mymaster 127.0.0.1 6379 #quorum 2/2
632:X 16 Apr 07:23:41.183 # Next failover delay: I will not start a failover before Mon Apr 16 07:29:41 2018
632:X 16 Apr 07:23:42.390 # +config-update-from sentinel 127.0.0.1:26381 127.0.0.1 26381 @ mymaster 127.0.0.1 6379
632:X 16 Apr 07:23:42.390 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6380
632:X 16 Apr 07:23:42.390 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6380
632:X 16 Apr 07:23:42.390 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6380
632:X 16 Apr 07:24:12.404 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6380
632:X 16 Apr 07:25:38.842 # -sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6380
[root@hongquan1 redis]# tail -n 100 26379.log
32566:X 16 Apr 07:07:43.971 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
32566:X 16 Apr 07:07:43.971 # Sentinel runid is 2e4d81b47dfb256ba20eaf83f244ade2cb9c8a32
32566:X 16 Apr 07:07:43.971 # +monitor master mymaster 127.0.0.1 6379 quorum 2
32566:X 16 Apr 07:07:43.978 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
32566:X 16 Apr 07:07:43.979 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
32566:X 16 Apr 07:10:53.099 * +sentinel sentinel 127.0.0.1:26380 127.0.0.1 26380 @ mymaster 127.0.0.1 6379
32566:X 16 Apr 07:12:00.436 * +sentinel sentinel 127.0.0.1:26381 127.0.0.1 26381 @ mymaster 127.0.0.1 6379
32566:X 16 Apr 07:23:41.056 # +sdown master mymaster 127.0.0.1 6379
32566:X 16 Apr 07:23:41.173 # +new-epoch 1
32566:X 16 Apr 07:23:41.174 # +vote-for-leader 3ffd9dcc66b8f11fbde922e194d60fbe16f112a8 1
32566:X 16 Apr 07:23:42.168 # +odown master mymaster 127.0.0.1 6379 #quorum 3/2
32566:X 16 Apr 07:23:42.168 # Next failover delay: I will not start a failover before Mon Apr 16 07:29:41 2018
32566:X 16 Apr 07:23:42.390 # +config-update-from sentinel 127.0.0.1:26381 127.0.0.1 26381 @ mymaster 127.0.0.1 6379
32566:X 16 Apr 07:23:42.390 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6380
32566:X 16 Apr 07:23:42.390 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6380
32566:X 16 Apr 07:23:42.390 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6380
32566:X 16 Apr 07:24:12.433 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6380
32566:X 16 Apr 07:25:38.889 # -sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6380
选举领头sentinel
某个sentinel发现主节点客观不在线后都可以发起选举
一个sentinel在一次选举中只能投一次票,先到先得
一次投票完成后,无论是否成功,投票周期都会加一,即epoch加一
如果某个sentinel获取到超过一半的投票,则自己就成为领头sentinel,负责实施故障转移
选举举例
场景:三台sentinel,编号为1,2,3,master的ip为192.168.1.110,端口为6379
步骤:
1这个sentinel先判断主节点主观下线
1发送sentinel is-master-down-by-addr 192.168.1.110 6379 1 *给2和3节点
1获取到反馈后,达到了判断master客观下线的条件
1发起选举,发送sentinel is-master-down-by-addr 192.168.1.110 6379 1 ab12cd34(1自己的实例id)给2和3节点
2收到消息后,因为是第一个收到1的,所以它也选举1,回复消息包含1,ab12cd34,1,分别代表主已经下线,选举的sentinel的实例id为
ab12cd34,选举周期为1;
1收到2的反馈后,发现所获得票是一半以上,则自己成为主,执行故障转移操作
故障转移
选出新的主服务器
删除主服务器的所有slave中处于下线状态的从服务器
删除最近5秒内没有回复sentinel发出的info命令的从服务器
删除与主服务器断线时间超过down-after-milliseconds*10毫秒的服务器
按照slave的优先级排序,优先级越高,越容易被选中
优先级一样高,则按照复制偏移量来排,数据偏移量越大说明数据越新
通过向选出的从服务器发送slaveof no one命令来转变身份
以每秒一次的频率发送info命令,如果返回信息中role:master,则选中成功
修改从服务器的复制目标
向其它从服务器发送slaveof命令即可
将旧的主服务器变为从服务器
因为主服务器已经下线,并不会做任何操作,但是sentinel会在自己的内部状态中维护主已经变为从,当重新连接后,会发送slaveof命令