1.
首先保证你已有程序,下面是MLP实现手写数字分类模型的代码实现。
不懂的可以对照注释理解。
#输入数据是28*28大小的图片,输出为10个类别,隐层大小为300个节点
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)
sess = tf.InteractiveSession()
x = tf.placeholder(dtype=tf.float32,shape=[None,784])
y_ = tf.placeholder(dtype=tf.float32,shape=[None,10])
image_reshaped_input = tf.reshape(x,[-1,28,28,1])
tf.summary.image('input',image_reshaped_input,10)
#tf.summary.image()用于将图像类型的tensor添加在Summary协议缓冲区中
#其本质就是将tensor统计存储,用于将来展示在tensorboard上
#在计算图中添加了一个新的节点,第一个参数是节点名称,第二个参数是接收的tensor
#第三个参数是最大存储的图像数目,此处指定为10,表明最多存储10个图像
#tf.summary.image()接受的tensor形状必须为[batch_size,height,width,channels],
#所以上面才对输入数据进行了reshape()操作
#channels为1时,图像被解析为灰度图,为3时解析为RGB图像,为4时解析为RGBA图像
W1 = tf.Variable(tf.truncated_normal([784,300],stddev=0.1))
b1 = tf.Variable(tf.zeros([300]))
hidden1 = tf.nn.relu(tf.matmul(x,W1)+b1)
keep_prob = tf.placeholder(tf.float32)
hidden1_drop = tf.nn.dropout(hidden1,keep_prob)
W2 = tf.Variable(tf.zeros([300,10]))
b2 = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(hidden1_drop,W2)+b2)
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y),reduction_indices=[1]))
tf.summary.scalar("cross_entropy",cross_entropy)
#tf.summary.scalar()用于将标量类型的tensor统计存储,形成折线图,用于可视化
#在计算图中添加了一个新的节点,第一个参数是节点名称,第二个参数是接收的tensor
train_step = tf.train.AdagradOptimizer(0.3).minimize(cross_entropy)
prediction_result = tf.argmax(y,1)
tf.summary.histogram("prediction_result",prediction_result)
#t.summary.histogram()用于将向量类型的tensor统计存储,形成直方图,用于可视化
#在计算图中添加了一个新的节点,第一个参数是节点名称,第二个参数是接收的tensor
correct_prediction = tf.equal(tf.argmax(y_,1),prediction_result)
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
tf.summary.scalar("accuracy",accuracy)
merged = tf.summary.merge_all()
#这一步操作的意义在于:如前所述,所有的summary操作本质上是graph中的一个节点
#tensorflow程序运行的时候,由于计算其他的变量不需要用到summary的结果,所以需要指定运行每一个summary
#如如果程序中定义了多个summary,那么每一个summary都需要运行一次,写起来太麻烦
#tf.summary.merge_all()可以将所有的summary操作拼成一个,这样只需要运行一次即可
writer = tf.summary.FileWriter("./logs",sess.graph)
#这一步将计算图以event文件的格式存入了./logs文件夹当中
#注意此时会话尚未开始执行,所有变量也都未初始化,所以实际上之前定义的summary还统计不到任何信息
tf.global_variables_initializer().run()
for i in range(3000):
batch_xs,batch_ys = mnist.train.next_batch(100)
_,summary = sess.run((train_step,merged),feed_dict={x:batch_xs,y_:batch_ys,keep_prob:0.75})
#需要对merged的所有summary执行sess.run()的操作,才可以确保数据流入了统计图中
writer.add_summary(summary,i)
#writer的add_summary()方法将某一个step的summary统计结果添加到了event文件中,i是step数
#这里实际上就是将每一个step的数据都添加到了event文件当中
#由此我们也理解了summary起到的统计的作用,实际上其统计的就是某一个tensor在不同的时刻的值的变化情况
#tf.summary.scalar将标量统计为折线图,tf.summary.histogram将向量统计为直方图
print("The final resultis"+str(accuracy.eval({x:mnist.test.images,y_:mnist.test.labels,keep_prob:1.0})))
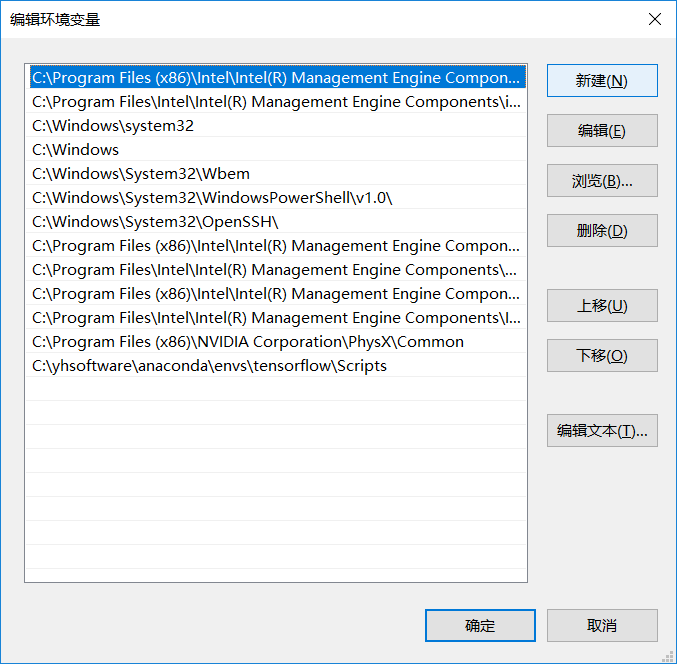
2.跑完程序后到程序当前目录下log文件夹找到 文件events.
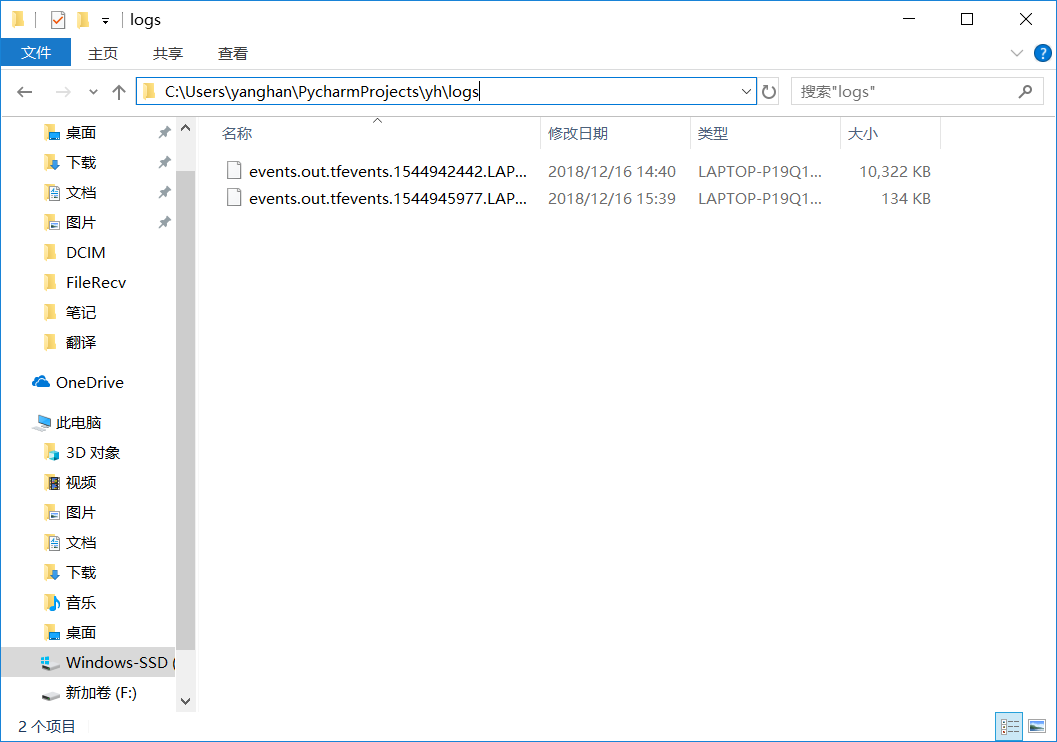
3.这一步是启动TensorBoard:
复制上面的路径,win10下打开Powershell ,输入:
tensorboard --logdir 上面的路径
4. 然后打开浏览器,我的是微软的edge浏览器,输入上面得到的网址:
http://localhost:6066
就得到了想要的图
------ ------------------------------------------------------------------------------------------------------分割线
如果在shell中只输入tensorboard命令就显示出错,则按以下步骤添加环境变量即可
1.搜索编辑系统环境变量
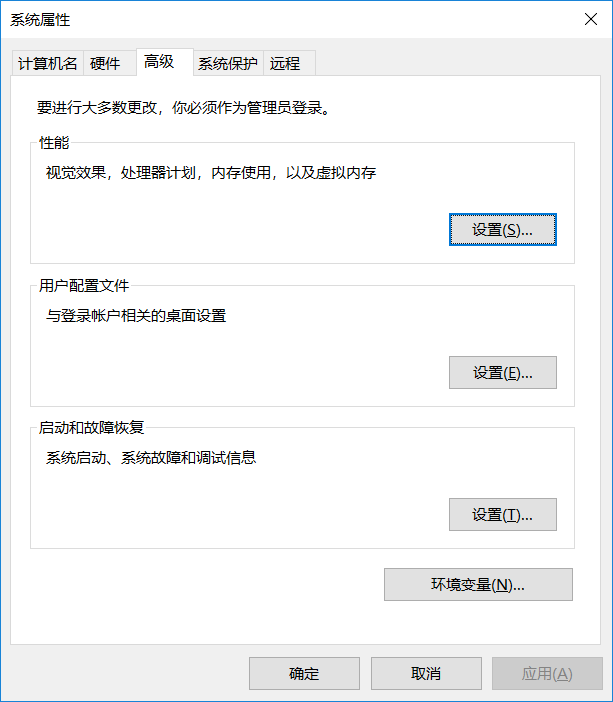
2.点环境变量,双击PATH
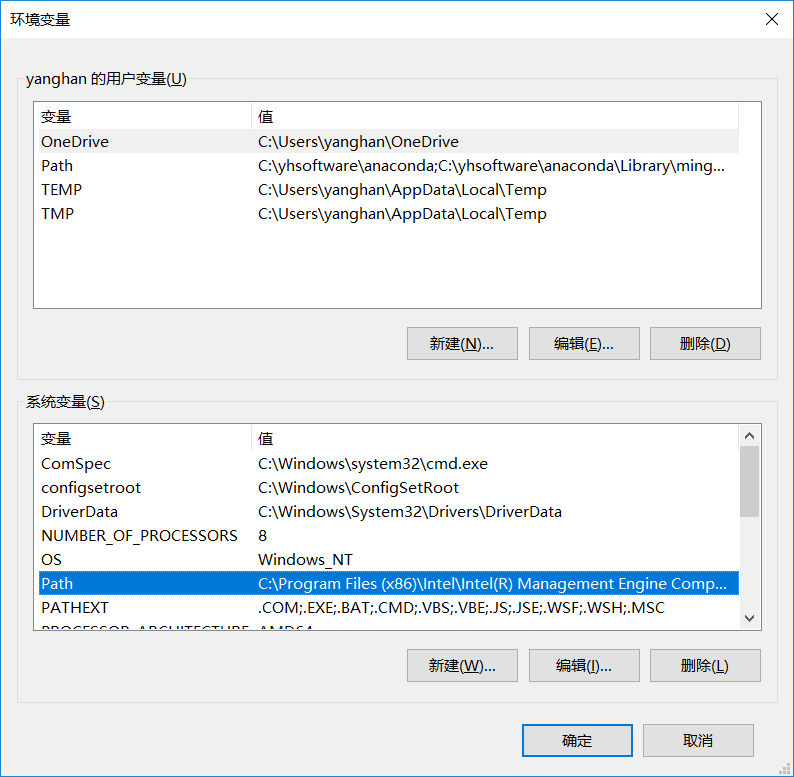
3.点击新建,把python路径添加进去,我的是anaconda下的Scripts,点进去复制上面的路径,新建添加的就是这个路径。
(图中最后一条)
再点击确定就行,这样就把环境变量添加好了,再输入tensorboard命令就不会出错了。